本文较长,可提前收藏。
用户中心,几乎是所有互联网公司,必备的子系统。随着数据量不断增加,吞吐量不断增大,用户中心的架构,该如何演进呢。
什么是用户中心业务?
用户中心是一个通用业务,主要提供用户注册、登录、信息查询与修改的服务。
用户中心的数据结构是怎么样的?
用户中心的核心数据结构为:
User(uid, login_name, passwd, sex, age, nickname, …)
其中:
(1)uid为用户ID,为主键;
(2)login_name, passwd, sex 等是用户属性;
其系统架构又是怎么样的呢?
在业务初期,单库单表,配合用户中心微服务,就能满足绝大部分业务需求,其典型的架构为:
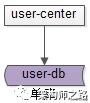
(1)user-center:用户中心服务,对调用者提供友好的RPC接口;
(2)user-db:对用户进行数据存储;
当数据量越来越大,例如达到1亿注册量时,会出现什么问题呢?
随着数据量越来越大,单库无法承载所有的数据,此时需要对数据库进行水平切分。
常见的水平切分算法有“范围法”和“哈希法”。
水平切分,什么是范围法?
范围法,以用户中心的业务主键uid为划分依据,采用区间的方式,将数据水平切分到两个数据库实例上去:

(1)user-db1:存储0到1千万的uid数据;
(2)user-db2:存储1千万到2千万的uid数据;
范围法有什么优点?
(1)切分策略简单,根据uid,按照范围,user-center很快能够定位到数据在哪个库上;
(2)扩容简单,如果容量不够,只要增加user-db3,拓展2千万到3千万的uid即可;
范围法有什么缺点?
(1)uid必须要满足递增的特性;
(2)数据量不均,新增的user-db3,在初期的数据会比较少;
(3)请求量不均,一般来说,新注册的用户活跃度会比较高,故user-db2往往会比user-db1负载要高,导致服务器利用率不平衡;
画外音:数据库层面的负载均衡,既要考虑数据量的均衡,又要考虑负载的均衡。
水平切分,什么是哈希法?
哈希法,也是以用户中心的业务主键uid为划分依据,采用哈希的方式,将数据水平切分到两个数据库实例上去:
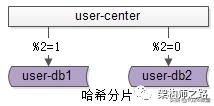
(1)user-db1:存储奇数的uid数据;
(2)user-db2:存储偶数的uid数据;
哈希法有什么优点?
(1)切分策略简单,根据uid,按照hash,user-center很快能够定位到数据在哪个库上;
(2)数据量均衡,只要uid是随机的,数据在各个库上的分布一定是均衡的;
(3)请求量均衡,只要uid是随机的,负载在各个库上的分布一定是均衡的;
画外音:如果采用分布式id生成器,id的生成,一般都是随机的。
哈希法有什么缺点?
(1)扩容麻烦,如果容量不够,要增加一个库,重新hash可能会导致数据迁移;
用户中心架构,实施了水平切分之后,会带来什么新的问题呢?
使用uid来进行水平切分之后,对于uid属性上的查询,可以直接路由到库,假设访问uid=124的数据,取模后能够直接定位db-user1:
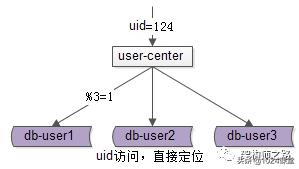
但对于非uid属性上的查询,就悲剧了,例如login_name属性上的查询:
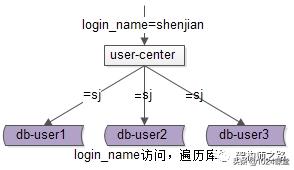
假设访问login_name=shenjian的数据,由于不知道数据落在哪个库上,往往需要遍历所有库,当分库数量多起来,性能会显著降低。
用户中心,非uid属性查询,有哪些业务场景?
任何脱离业务的架构设计都是耍流氓。
在进行架构讨论之前,先来对业务进行简要分析,用户中心非uid属性上,有两类典型的业务需求。
第一大类,用户侧,前台访问,最典型的有两类需求:
(1)用户登录:通过登录名login_name查询用户的实体,1%请求属于这种类型;
(2)用户信息查询:登录之后,通过uid来查询用户的实例,99%请求属这种类型;
用户侧的查询,基本上是单条记录的查询,访问量较大,服务需要高可用,并且对一致性的要求较高。
第二大类,运营侧,后台访问,根据产品、运营需求,访问模式各异,按照年龄、性别、头像、登陆时间、注册时间来进行查询。
运营侧的查询,基本上是批量分页的查询,由于是内部系统,访问量很低,对可用性的要求不高,对一致性的要求也没这么严格。
对于这两类不同的业务需求,应该使用什么样的架构方案来解决呢?
总的来说,针对这两类业务需求,架构设计的核心思路为:
(1)用户侧,采用“建立非uid属性到uid的映射关系”的架构方案;
(2)运营侧,采用“前台与后台分离”的架构方案;
用户侧,如何实施“建立非uid属性到uid的映射关系”呢?
常见的方法有四种:
(1)索引表法;
(2)缓存映射法;
(3)生成uid法;
(4)基因法;
接下来,咱们一一介绍。
什么是,索引表法?
索引表法的思路是:uid能直接定位到库,login_name不能直接定位到库,如果通过login_name能查询到uid,问题便能得到解决。
具体的解决方案如下:
(1)建立一个索引表记录login_name与uid的映射关系;
(2)用login_name来访问时,先通过索引表查询到uid,再通过uid定位相应的库;
(3)索引表属性较少,可以容纳非常多数据,一般不需要分库;
(4)如果数据量过大,可以通过login_name来分库;
索引表法,有什么缺点呢?
数据访问,会增加一次数据库查询,性能会有所下降。
什么是,缓存映射法?
缓存映射法的思路是:访问索引表性能较低,把映射关系放在缓存里,能够提升性能。
具体的解决方案如下:
(1)login_name查询先到cache中查询uid,再根据uid定位数据库;
(2)假设cache miss,扫描所有分库,获取login_name对应的uid,放入cache;
(3)login_name到uid的映射关系不会变化,映射关系一旦放入缓存,不会更改,无需淘汰,缓存命中率超高;
(4)如果数据量过大,可以通过login_name进行cache水平切分;
缓存映射法,有什么缺点呢?
仍然多了一次网络交互,即一次cache查询。
什么是,生成uid法?
生成uid法的思路是:不进行远程查询,由login_name直接得到uid。
具体的解决方案如下:
(1)在用户注册时,设计函数login_name生成uid,uid=f(login_name),按uid分库插入数据;
(2)用login_name来访问时,先通过函数计算出uid,即uid=f(login_name)再来一遍,由uid路由到对应库;
生成uid法,有什么缺点呢?
该函数设计需要非常讲究技巧,且有uid生成冲突风险。
画外音:uid冲突,是业务无法接受的,故生产环境中,一般不使用这个方法。
什么是,基因法?
基因法的思路是:不能用login_name生成uid,但可以从login_name抽取“基因”,融入uid中。
假设分8库,采用uid%8路由,潜台词是,uid的最后3个bit决定这条数据落在哪个库上,这3个bit就是所谓的“基因”。
具体的解决方案如下:
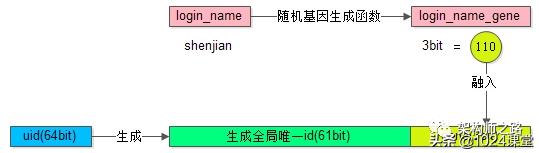
(1)在用户注册时,设计函数login_name生成3bit基因,login_name_gene = f(login_name),如上图粉色部分;
(2)同时,生成61bit的全局唯一id,作为用户的标识,如上图绿色部分;
(3)接着把3bit的login_name_gene也作为uid的一部分,如上图屎黄色部分;
(4)生成64bit的uid,由id和login_name_gene拼装而成,并按照uid分库插入数据;
(5)用login_name来访问时,先通过函数由login_name再次复原3bit基因,login_name_gene = f(login_name),通过login_name_gene%8直接定位到库;
画外音:基因法,有点意思,在分库时经常使用。
用户侧,如何实施“前台与后台分离”的架构方案呢?
前台用户侧,业务需求基本都是单行记录的访问,只要建立非uid属性login_name到uid的映射关系,就能解决问题。
后台运营侧,业务需求各异,基本是批量分页的访问,这类访问计算量较大,返回数据量较大,比较消耗数据库性能。
此时的架构,存在什么问题?
此时,前台业务和后台业务共用一批服务和一个数据库,有可能导致,由于后台的“少数几个请求”的“批量查询”的“低效”访问,导致数据库的cpu偶尔瞬时100%,影响前台正常用户的访问(例如,登录超时)。
画外音:本质上,是系统的耦合。
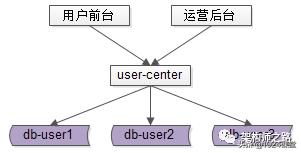
而且,为了满足后台业务各类“奇形怪状”的需求,往往会在数据库上建立各种索引,这些索引占用大量内存,会使得用户侧前台业务uid/login_name上的查询性能与写入性能大幅度降低,处理时间增长。
对于这一类业务,应该采用“前台与后台分离”的架构方案。
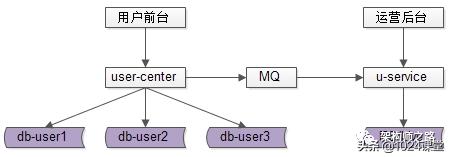
什么是,前台与后台分离的架构方案?
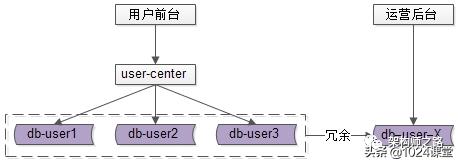
用户侧前台业务需求架构依然不变,产品运营侧后台业务需求则抽取独立的 web / service / db 来支持,解除系统之间的耦合,对于“业务复杂”“并发量低”“无需高可用”“能接受一定延时”的后台业务:
(1)可以去掉service层,在运营后台web层通过dao直接访问db;
(2)不需要反向代理,不需要集群冗余;
(3)不需要访问实时库,可以通过MQ或者线下异步同步数据;
(4)在数据库非常大的情况下,可以使用更契合大量数据允许接受更高延时的“索引外置”或者“HIVE”的设计方案;
总结
用户中心,是典型的“单KEY”类业务,这一类业务,都可以使用上述架构方案。
常见的数据库水平切分方式有两种:
(1)范围法;
(2)哈希法;
水平切分后碰到的问题是:
(1)通过uid属性查询能直接定位到库,通过非uid属性查询不能定位到库;
非uid属性查询,有两类典型的业务:
(1)用户侧,前台访问,单条记录的查询,访问量较大,服务需要高可用,并且对一致性的要求较高;
(2)运营侧,后台访问,根据产品、运营需求,访问模式各异,基本上是批量分页的查询,由于是内部系统,访问量很低,对可用性的要求不高,对一致性的要求也没这么严格;
针对这两类业务,架构设计的思路是:
(1)用户侧,采用“建立非uid属性到uid的映射关系”的架构方案;
(2)运营侧,采用“前台与后台分离”的架构方案;
前台用户侧,“建立非uid属性到uid的映射关系”,有四种常见的实践:
(1)索引表法:数据库中记录login_name与uid的映射关系;
(2)缓存映射法:缓存中记录login_name与uid的映射关系;
(3)生成uid法:login_name生成uid;
(4)基因法:login_name基因融入uid;
后台运营侧,“前台与后台分离”的最佳实践是:
(1)前台、后台系统 web/service/db 分离解耦,避免后台低效查询引发前台查询抖动;
(2)可以采用数据冗余的设计方式;
(3)可以采用“外置索引”(例如ES搜索系统)或者“大数据处理”(例如HIVE)来满足后台变态的查询需求;
任何脱离业务的架构设计都是耍流氓。
来源公众号:架构师之路
作者:58沈剑