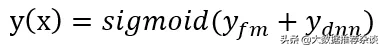工业推荐系统一般包含四个环节,分别是召回、粗排、精排和重排。召回阶段根据用户的兴趣和历史行为,从海量的物品库里,快速找回一小部分用户潜在感兴趣的物品,然后交给排序环节,排序环节可以融入较多特征,使用复杂模型,来精准地做个性化推荐。有时候因为每个用户召回环节返回的物品数量还是太多,怕排序环节速度跟不上,所以可以在召回和精排之间加入一个粗排环节,通过少量用户和物品特征,简单模型,来对召回的结果进行粗略的排序,在保证一定精准的前提下,进一步减少往后传送的物品数量,粗排往往是可选的,可用可不同,跟场景有关。之后,是精排环节,使用你能想到的任何特征,可以上你能承受速度极限的复杂模型,尽量精准地对物品进行个性化排序。排序完成后,传给重排环节,重排环节往往会上各种技术及业务策略,比如去已读、去重、打散、多样性保证、固定类型物品插入等等,主要是技术产品策略主导或者为了改进用户体验的。
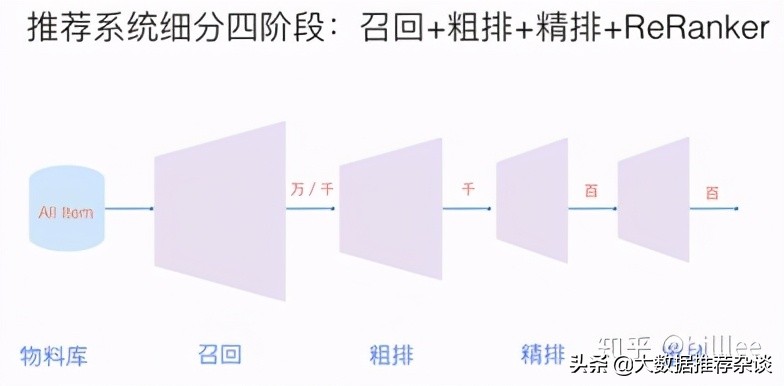
排序环节是推荐系统最关键,也是最具有技术含量的部分, 工业界应用的排序模型,大致经历三个阶段,如下图所示。
当前业界主流的推荐排序模型是深度学习模型,基于深度学习模型的多目标优化、ListWise以及强化学习是当前最常见的技术演进方向,本文主要介绍工业界经典的推荐排序模型。
LR算法
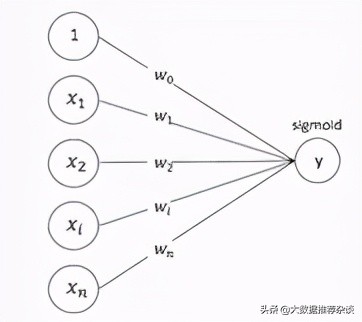
LR 模型是 CTR 预估领域早期最成功的模型,大多早期的工业推荐排序系统采取 LR 这种 “线性模型 + 人工特征组合引入非线性” 的模式。LR 模型具有训练快、上线快、可解释性强、容易上规模等优点,目前仍然有不少实际系统采取这种模式。

普通逻辑回归不适应大规模稀疏特征的点击率预估。一是传统的逻辑回归参数训练过程都依赖牛顿法或L-BFGS等算法,这些算法并不容易在大规模数据集上得以处理,二是不容易得到稀疏解,而实际上对于大规模稀疏的数据来说,通常仅有少量特征是被激活的。FTRL梯度优化算法改进了传统的LR算法,其核心就是模型的参数会在每一个数据点进行更新,是一种在线学习算法,其参数更新伪代码如下:

FM算法在 LR 的基础上加入二阶特征组合,即任意两个特征进行组合,将组合出的特征看作新特征,加到 LR 模型中。组合特征的权重在训练阶段学习获得。但这样对组合特征建模,泛化能力比较弱,尤其是在大规模稀疏特征存在的场景下。FM 模型也直接引入任意两个特征的二阶特征组合,但对于每个特征,学习一个大小为 k 的一维向量,两个特征 Xi和 Xj 的特征组合的权重值,通过特征对应的向量 Vi 和 Vj 的内积 <Vi , Vj> 来表示。这本质上是对特征进行 Embedding化表征,和目前常见的各种实体 Embedding 本质思想是一样的。

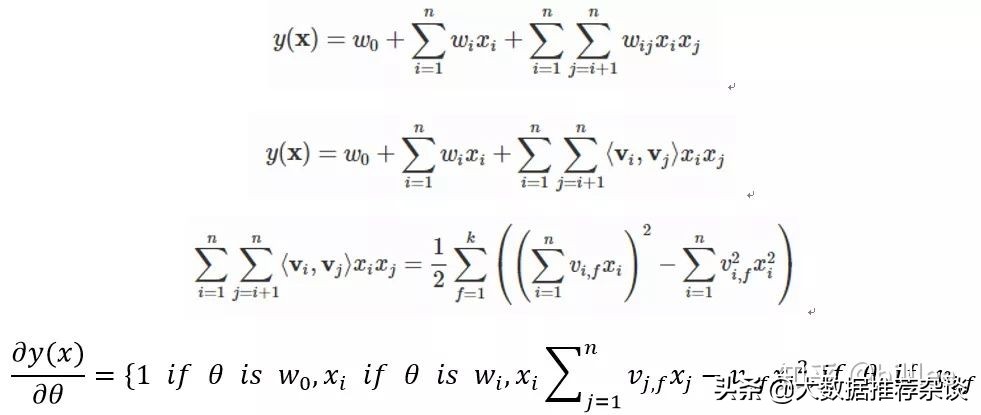
FM 可以模拟二阶多项式核SVM,但是FM的训练和预估复杂度是线性的,而二阶多项式核SVM需要计算核矩阵,复杂度为N平方。MF算法相当于只有User和Item两类特征的FM模型,而 FM模型可以加入任意特征,比如Context特征。
Wide&Deep 是推荐领域取得较大成功的最早期深度模型,由 google 于 2016 年提出。Wide&Deep模型包括 Wide 部分和 Deep 部分,Wide 部分为 LR,输入为one-hot 后的离散型特征和等频分桶后的连续性特征,这部分可以对样本中特征与目标较为明显的关联进行记忆学习;Deep 部分为 MLP,输入为Embedding 后的离散型特征和归一化后的连续型特征,可以泛化学习到样本中多个特征之间与目标看不到的潜在关联。使用 Wide&Deep 的另一个优势在于 Wide 部分的存在,可以沿用之前浅层学习的成果,尤其是特征工程部分。
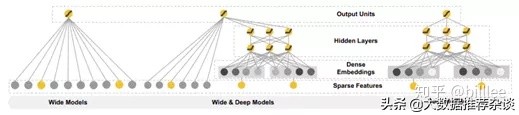
Wide部分是广义线性模型,可以包括原始特征及转换后的特征,Deep部分是神经网络。
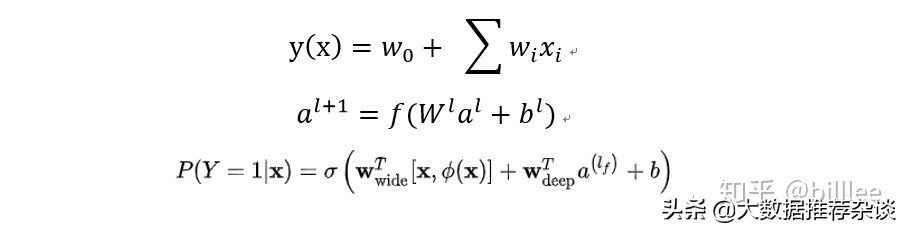
DeepFM 将 Wide&Deep 的Wide 部分 LR 替换成 FM 来避免人工特征工程。DeepFM 相比 Wide&Deep 模型更能捕捉低阶特征信息。同时,Wide&Deep 部分的 Embedding 层需要针对 Deep 部分单独设计,而在 DeepFM 中,FM 和 Deep 部分共享Embedding 层,FM 训练得到的参数及作为 wide 部分的输出,也作为 MLP 部分的输入。DeepFM 支持end-end 训练,Embedding 和网络权重联合训练,无需预训练和单独训练。从个人实践效果来看,DeepFM算法如果在人工交叉特征已经比较丰富的情况下,效果相对于Wide&Deep算法提升有限。
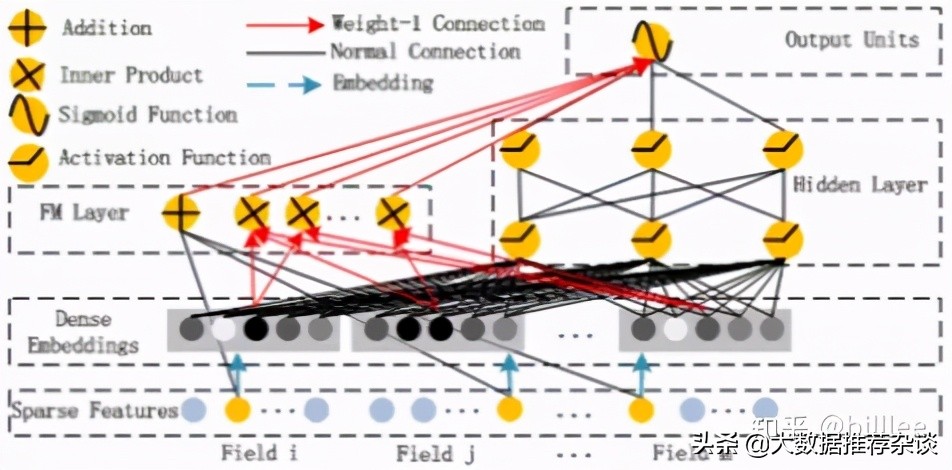
其输出为: