
处理图像不是一项简单的任务。 对你来说,作为一个人,很容易看着某样东西然后马上知道你在看什么。 但电脑不是这样工作的。
对你来说太难的任务,比如复杂的算术,或者一般意义上的数学,是计算机毫不费力就能完成的。 但在这里, 情况正好相反 ——对你来说很琐碎的任务,比如识别图像中的猫或狗,对电脑来说真的很难。 在某种程度上,我们是天造地设的一对。 至少现在是这样。
虽然图像分类和涉及到一定程度计算机视觉的任务可能需要大量的代码和扎实的理解,但是从格式良好的图像中读取文本在Python中却是简单的,并且可以应用于许多现实生活中的问题。私信小编01 领取完整项目代码~
在今天的帖子中,我想证明这一点。 虽然会安装一些库,但不会花很多时间。 这些是你需要的库:
现在,这个库将只用于加载图像,实际上你不需要事先对它有太多了解(尽管它可能有帮助,你将看到为什么)。
根据官方文件:
OpenCV(开源计算机视觉库)是一个开源的计算机视觉和机器学习软件库。 OpenCV的目的是为计算机视觉应用提供一个通用的基础结构,并加速机器感知在商业产品中的使用。 OpenCV是bsd许可的产品,OpenCV使企业可以轻松地使用和修改代码
简而言之,你可以使用OpenCV来做任何类型的 图像转换 ,这是一个相当简单的库。
如果你还没有安装它,那么它将只是终端中的一行:
pip install opencv-python
差不多就是这样。 在此之前,一切都很简单,但这种情况即将改变。
这个库到底是什么东西?根据维基百科:
Tesseract是用于各种操作系统的光学字符识别引擎。它是免费软件,根据Apache许可2.0版发布,自2006年以来由google赞助开发。
我敢肯定,现在有更多复杂的库可用,但是我发现这个库运行良好。 根据我自己的经验,该库应该能够从任何图像中读取文本,但前提是该字体不会使你连连看都看不懂。
如果无法从你的图像中读取文字,花更多的时间使用OpenCV,应用各种过滤器使文本高亮。
现在安装在底部有些麻烦。 如果你使用的是linux,则全部归结为几个 sudo-apt get 命令:
sudo apt-get update sudo apt-get install tesseract-ocr sudo apt-get install libtesseract-dev
我用的是windows系统,所以这个过程有点乏味。
首先,打开这个URL:
https://github.com/UB-Mannheim/tesseract/wiki
下载32位或64位的安装程序:

安装本身很简单,只需单击几次Next。 是的,你还需要做一个 pip安装 :
pip install pytesseract
接下来要需要告诉Python Tesseract安装在何处。 在Linux机器上,我不需要这样做,但在Windows上是必需的。 默认情况下,它安装 Program Files 。
如果你做的一切正确,执行这些代码应该不会产生任何错误:

让我们从一个简单的开始。 我找到了一些免版税的图片,里面有一些文字,第一个是这样的:

它应该是简单的一个,有可能Tesseract会读那些蓝色的“对象”作为括号。 让我们看看会发生什么:
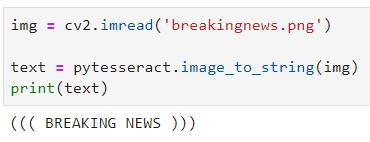
我的猜测是正确的。 不过,这不是一个问题,你可以使用一些Python技巧轻松地解决这些问题。
下一个可能更棘手:

我希望它不会检测到硬币上的“B”:

看起来效果很好。
现在轮到你把它应用到你自己的问题上了。 如果文本与背景混合,OpenCV技能在这里可能是至关重要的。
对计算机来说,从图像中读取文本是一项相当困难的任务。 想想看,电脑不知道字母是什么,它只对数字有效。 在引擎盖后面发生的事情一开始可能看起来像一个黑盒子,但我鼓励你进一步研究,如果这是你感兴趣的领域。
我并不是说PyTesseract每次都能很好地工作,但是我发现即使在一些比较复杂的图像上它也足够好。 但不是所有情况都很好,有时候需要一些图像处理需要使文本高亮让其相对于背景更加突出。

























