成长是一棵树,总是在你不知不觉的情况下快乐长大;成长是一株草,总是在你不知不觉的情况下长满大地;成长是一朵花,总是在你不知不觉的情况下开满山头。
这不,随着时间的迁移。项目网站的用户量、数据量持续上升,普通模式下的单机MySQL即将面临被请求压力打垮的情景。老早就被急的像热锅上蚂蚁一样的产品经理,把我给叫了过去,看着那诚恳的小眼神儿。心理甚是开心。

你说,早知道会遇到这样的事儿,以前咋不见他好好说话,朝令夕改的需求,感觉就不要欠钱似的直接堆过来,今天终于轮到我 农民翻身把歌唱 啦。
自己首先就是一副处变不惊的表情,抽根烟,喝口茶。对产品说到:“不急不急,一切尽在我们团队的预料之中”。 由我一一道来,这下咱真的是腿不酸了,腰板儿也硬朗了。好不容易,你撞我枪口上来了,还不得杀杀你的锐气。 也让你知道知道咋的手段。
随着网站的发展,在面对高并发请求的时候。单机下面的MySQL肯定是会遇到性能的瓶颈。因为你单机无论是磁盘的存储、I/O的开销上都是会有资源上限。没办法支持网站后续的发展。毕竟双拳难敌四手。正是因为这样我们才会构建大规模、高性能的应用。基于“水平扩展”的方式来满足项目发展的需要。这也是搭建高可用、可扩展性、灾难恢复、备份及数据仓库等工作的基础。
在有规模的网站中,程序员往往都是避免不了这类型的话题。
1、自身不足:解决单机下的瓶颈问题
为什么随着公司的发展,需要越来越多的人,而不应该人数越少越好好吗?那是因为公司越发展业务会增多,相关的事情也会越来越多。如果都交给一个人,那必定精力是有限。根本不能完成每天的工作。
单机MySQL也是一样。它的磁盘、内存、I/O、CPU等资源都是有限制。
注:单机MySQL指在一台物理服务器上安装一台MySQL,专门只提供数据库的服务。单机多实例指在一台物理服务器上可以安装多台MySQL实例
一般中、大型网站的数据量可能达到几百GB、几个TB的数据,甚至是更高。而你单机下面的磁盘容量可能才是几十个GB。它能够支持数据存储的容量吗?
网站项目规模过大,那必定你业务的请求量肯定是十分巨大的,在这么大的情况下面,少说也得亿级的PV的用户请求吧。这样的条件下,你的I/O访问的频率过高,CPU切换忙都忙不过来,一直都是高负载的情况。它能搞的赢?
因为系统的软件运行是由CPU每隔一个时间片切换后才能执行程序的。这样服务器的压力会异常的大,一直都高负荷运行状态。从而导致宕机。 同时你在这样的条件下,每一个请求走到MySQL后,都需要给每一个请求分配一个线程去执行该请求里面的SQL语句。那线程的资源开销也是需要内存的啊。就算你是单机的MySQL。那你的内存也有上限,难道可以分配几千个线程?
这不,葛优大爷出演的电影《甲方乙方》也说道了,"地主家也没有余粮啊"
并且,你磁盘I/O的读写也是需要时间的,请求越多,你磁盘读写机会也机会多,而从数据库的数据是需要从磁盘里面读取到内存中,然后在响应给客户端的。那所有的请求都要做磁盘寻址。那这个消耗也是很大的。
后面出一篇详细的数据库数据载入原理,这里大家先给一个总结
2、压力分担:让请求负载均衡给多台数据库
做了主从复制后最明显的特点就是,把相关的读写请求分离。主库针对写请求,从库针对读请求,这样能够在业务上面把各个数据库的职责划分开。对后续的一切客户端的请求,我们可以根据读或者是写直接交给对应的数据库。
一般项目绝大多数都是读操作,通过MYSQL复制将读操作分布到多个服务器上,从而实现对密集性应用的优化,通过Nginx简单的代码修改就能实现基本负载均衡。
对于小规模的网站,可以对机器名做硬编码或使用DNS轮询(将一个机器名指定到多个IP地址),当然也可以选择复杂的方法,采用LVS网络的负载均衡来实现网络的情求的分担。
业务上针请求类型来划分。在读请求上,针对负载均衡实施到多个数据库中,你说这个手段怎么样? 要得不呢? 咱程序员也不是吃素的。嗓子干了,喝口水再来
3、数据备份与数据分布
对于数据备份。这应当是每个网站中都需要考虑的环节,从而保证线上环境因为误删而导致数据库不能追踪回来。但是这里的主从复制和我们常说的备份不一样。
主从复制是通过把主库的数据复制到从库中,虽然是复制的过程,但也可以达到备份的效果,就像你的电影从D盘复制到E盘,就存在2份了,删除一份,另一份还在。
对于主从复制的过程中,可以选择在不同的地理位置来分布数据,不同的数据中心内,即使不稳定的网络条件下,远程复制也是进行的。这样我们能够让数据库有多个数据中心节点,分布到各地。异地多活就是自在。
4、高可用和故障迁移
复制能够帮助应用程序避免MySQL单点失败。一个包含复制的设计良好的故障切换系统能够显著的缩短宕机时间。这也就是主从复制为什么可以做到高可用的特点。
假如我的服务器因为机房停电了,这台服务器就没法使用了,但是它的数据都被Copy到另外的服务器中,这样我可以直接从库里直接选择一台服务器来替代没法工作的服务器。从而继续提供服务。
总结一下,备份的操作就是做为高可用的首选条件。
前面经过经过各方面的问题以及主从复制做了详细的解析,大家需要自己汇总下主从复制的特点与解决到了单机什么的问题,因为面试有时候就喜欢问一些你对于业务特点的理解和底层原理,那前面是问题的理解,这个实现原理怎么来办? 放心,作为暖男的我,下面就给大家一 一道明。
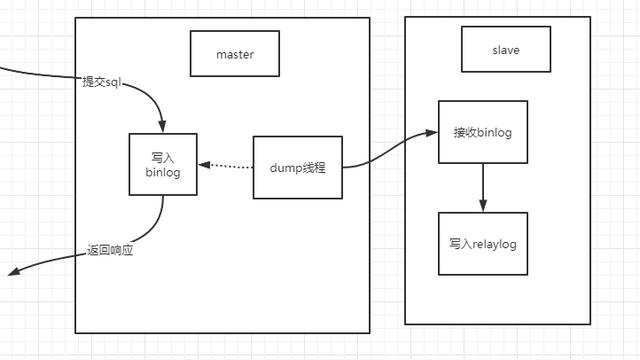
主从复制原理解析
MySQL主从复制上的复制,总的来说,有三个过程来实现数据的复制操作。
注:更新记录的SQL语句为与DDL和DML类型语句。DDL语句就是对数据库、表层面的操作,如CREATE、ALTER、DROP;DML就是对表中数据的增删改查,如SELECT、UPDATE、INSERT、DELETE操作的语句。但是在二进制中SELECT不会记录进去。
以上就是大概的描述,下面来个图进行详细过程梳理。

主从复制大家步骤
前面咱们了解到原理,现在就着手来搭建主从复制。
复制前的准备工作:
创建用户
MySQL会赋予一些特殊的权限给复制线程,在备库运行IO线程会建立一个到主库的TCP/IP连接,这意味着必须在主库创建一个用户,并赋予其合适的权限,备库I/O线程一该用户名连接到主库并读取其二进制文件。
在每台服务器上都创建复制用户账号,并授权:用户:test 密码:test1
# 创建用户
create user 'test'@'10.16.1.118' identified by 'test1';
# 授权,只授予复制和客户端访问权限
grant replication slave on *.* to 'test'@'10.16.1.119';#分配权限
为什么每台服务器都创建复制账号呢?
用于监控和管理复制账号的权限,主库账号用于从库连接并进行日志复制使用,而从库账号,用于当主库宕机时,把从库切换为主库时,自身所需的配置。
配置主库与从库
找到主数据库的配置文件my.cnf,默认在 /etc/my.cnf
vi /etc/my.cnf
在[mysqld]部分插入
[mysqld] log-bin=mysql-bin #开启二进制日志 server-id=1 #设置server-id,必须唯一
配置说明
log-bin:设置二进制日志文件的基本名; log-bin-index:设置二进制日志索引文件名; binlog_format:控制二进制日志格式,进而控制了复制类型,三个可选值 -STATEMENT:语句复制,默认选项 -ROW:行复制 -MIXED:混和复制 server-id:服务器设置唯一ID,默认为1,推荐取IP最后部分; sync-binlog:默认为0,为保证不会丢失数据,需设置为1,用于强制每次提交事务时,同步二进制日志到磁盘上。
打开mysql会话shell
mysql -uroot -p
查看master状态
记录二进制文件名(mysql-bin.000013)和位置(8369):
mysql> show master status; +------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------+ | mysql-bin.000013 | 8369 | | | | +------------------+----------+--------------+------------------+-------------------+ 1 row in set (0.00 sec)
配置从库Slave
找到从数据库的配置文件my.cnf,默认在/etc/my.cnf
vi /etc/my.cnf
在[mysqld]部分插入
[mysqld] server-id=2 #设置server-id,必须唯一 relay-log=/var/lib/mysql/mysql-relay-bin #指定中继日志的位置和命名
启动主从复制
重启从mysql,打开从mysql会话,在从数据库上执行同步SQL语句(需要主服务器主机名,登陆凭据,二进制文件的名称和位置):
mysql> CHANGE MASTER TO -> MASTER_HOST='10.16.1.118 ', -> MASTER_USER='test', -> MASTER_PASSword='test1', -> MASTER_LOG_FILE='mysql-bin.000013', -> MASTER_LOG_POS=8369; Query OK, 0 rows affected, 2 warnings (0.02 sec)
启动slave同步进程
mysql>start slave;
查看slave状态
mysql> show slave statusG *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 10.16.1.118 Master_User: test Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-relay-bin.000002 Read_Master_Log_Pos: 8369 Relay_Log_File:relay-bin.000002 Relay_Log_Pos: 640 Relay_Master_Log_File: mysql-bin.000013 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: ......
当Slave_IO_Running和Slave_SQL_Running都为YES的时候就表示主从同步设置成功了。
测试:
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+ 4 rows in set (0.00 sec) mysql> create database test; Query OK, 1 row affected (0.00 sec) mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | test | | performance_schema | | sys | +--------------------+ 5 rows in set (0.00 sec)
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+ 4 rows in set (0.00 sec) mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | test | | performance_schema | | sys | +--------------------+ 5 rows in set (0.00 sec)
注:数据库复制同步之前,两者的数据库、表一定要同步,不然的话会导致同步之前,并没有把相关更新操作执行的SQL存储到binlog日志,到时候就会导致数据不一致而报错。
架构原理对我们的启发
上面针对于原理上的解析,但是这个东西使用的模式设计,我们从中可以的得到什么启发?并运用自己的业务系统中,这个是我们学习的另一个重点。作为暖男的我,岂能不帮助大家呢?
这种主从的复制架构实现了日志获取和数据重放的解耦,允许这两个过程是异步进行处理的,也就是l/O线程能够独立于SQL线程之外点的工作。
大家都知道异步的好处就是实现业务上的解耦,然后对业务进行针对性的操作,从而来提升执行的效率。这里面线程的职责分别是获取与重放的单一职责处理。同时也方便后面系统的管理。
注:默认的主从方式为异步模式,后面出一篇详细的同步方式和复制常见问题解决。尽请期待
假如,如果说从库只有一个工作I/O完成所有的复制工作,那么就会阻塞日志读取,在来进行重放,并且重放过程中,SQL语句执行时,还会进行语法、词法分析等。这样就导致复制效率降低,从而引发延迟问题。所以这也是为什么在这里要涉及业务分析的原因。现在大家对你们的业务有优化的考虑吗? 欢迎留言讨论
但这种架构也限制了复制的过程,其中一点在主库上并发运行的操作在备库只能串行化执行。因为只有一个SQL线程来重放中继日志。在5.7以上有了多线程的模式。
总结一下:MySQL主从可以解决单机性能、存储不足的问题,所以主从复制是通过扩容的思路来进行数据的分布,从而划分请求来抵御过大的用户请求。对于从库实现的原理分为三大阶段,分别是记录日志、写入到中继日志、重放日志。对于架构模式考虑上,也需要代入我们的业务场景中来做分析使用
大家如果有什么需求,也是可以留言的。如有感悟,欢迎关注@php智慧与能力
大冬天的,作为暖男的我,也希望能够给大家温暖下去。关注下,咳咳咳咳。如果需要欠缺实战的同学可以购买专栏额。