在亿万服务、海量数据的今天,对于互联网服务的要求就是三高,高并发、高性能、高可用。为了实现“三高”,程序员们可真是使尽浑身解数,在技术架构上使用微服务架构,在部署方式上使用Docker、Kubernetes,在弹性扩容方面使用云计算等等。而今天要给大家介绍的便是应用监控体系。监控就像应用的跟屁虫一样,走到哪跟到哪,做了什么全知道并记录下来,通过监控体系的搭建,当应用有问题时可以快速“回放”应用轨迹,找到原因,长远来说,还可以预测故障的发生,提前避免。
那么一个应用体系是怎么样的呢?用户通过在PC或智能终端(手机)通过浏览器或App对应用发起请求,请求通过网络传输到业务系统,业务系统的函数通过应用框架、中间件运行起来,运行系统又依托于操作系统,操作系统需要网络设备如网卡等与外界建立通讯,而这全套软件都是安装在硬件之上,如服务器、网卡等硬件设备都是安装在机房中。因此对一个应用体系的全栈监控就包含APP监控、浏览器监控、服务器监控、网络监控、日志监控、基础设施监控、物理环境监控。
APP监控
目前APP的主流操作系统有Android、IOS,因此每个APP开发时都会有两个版本,APP的开发流程是研发根据产品需求进行功能的开发,开发完成后打对应的Android包、IOS包在安卓应用商店、苹果应用商品进行上线。因此对于APP的监控是通过打包时将探针安装在对应的应用包里,形成正式包对外发布。
当用户手机下载了APP后,在使用APP的各个功能时,整个的行为轨迹也被探针记录下来了。探针会采集两类数据,用户数据和APP运行数据,用户数据包括设备所在的地域、城市、设备的操作系统、使用时长、使用次数,运行数据包括APP运行网络情况、卡顿情况、缓慢情况。获取到用户数据和运行数据后就可以运营分析和运维监控了,了解开发的APP用户日活、访问区域、访问版本等,帮助产品运营同学进行产品的优化迭代提供意见;通过运维数据可以知道用户打开APP是否白屏、是否卡顿、是否缓慢、是否网络被运营商劫持,从而帮助研发人员快速解决问题,提高用户留存率。
浏览器监控
对于浏览器的监控,起源于早期互联网时代,购物、购票、办公等都是在PC端进行,随着移动互联网的兴起,逐步的被弱化,但是却是不可缺少的,因此浏览器监控也是监控体系中不可缺少的一环节。浏览器监控体系也是包含三部分,探针采集数据发送后端、后端处理数据给到前端、前端呈现给用户。
探针的实现取决于应用如何运行,对于浏览器应用来说,主要是前端基于html/css、JAVAScript进行开发,用户在浏览器输入URL,首先在本地进行缓存查询是否有该地址对应的IP地址,如果没有则再使用DNS进行域名解析,找到提供服务的地址,其次再对该地址进行TCP三次握手连接,发送请求获取请求数据,获取到数据后进行数据解析,包括HTML文档解析、DOM构建、页面渲染,最后呈现给到可视化页面用户。
因此浏览器探针是一段JS代码,通过浏览器的加载事件、导航事件等获取页面访问的数据,比如浏览器基本信息、采集页面性能数据、采集Ajax性能数据和请求响应数据、JS错误数据、页面追踪数据等,再发送给到后台处理加工,形成用户运营数据(比如页面PV、运营商信息、浏览器信息、访问城市省会信息)、运维数据(比如Ajax错误信息、JS缓慢页面信息),帮助运营了解产品用户情况,更好的推广营销、帮助研发运维团队解决产品生产环境中的功能性能问题。
服务器监控
对于服务器监控主要是监控后端系统的运行情况,因Java、Python、php、.Net/.NetCore、C/C++、Golang等语言都可以开发后端应用,因此服务器探针也包含各种语言的探针。从这八种开发语言的特性来看,有的语言是编译型,即将源代码翻译成机器码后才能运行,例如Golang,C/C++;有的语言是解释型,边执行边翻译,例如PHP、Python;有的语言是混合型,介于编译型和解释型之间,即把代码编译成中间码再在语言提供的平台运行,例如Java、.Net/.NetCore。因此不同类型语言的探针实现也不一样。
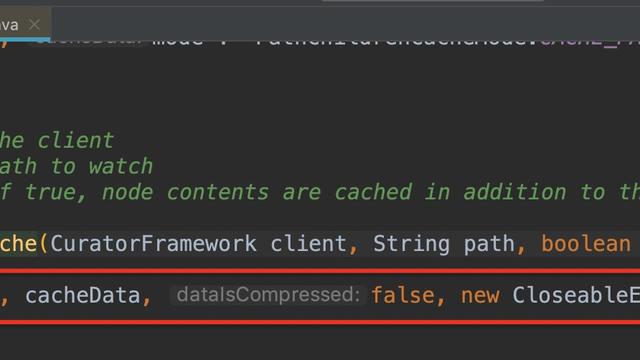
对于解释型语言来说,使用HookApi的方式实现,例如Python在运行过程中会需要调用框架和函数,因此Python探针针对各个框架各数据库需要专门定义Hook函数,探针启动时会将我们写好的Hook函数(针对WEB框架,WSGI,数据库等)加入sys_meta_path中,这样用户函数在执行后就会先执行我们定义好的Hook函数,采集数据;对于编译型语言来说,使用SDK的方式实现,总体的思路和HookAPI一致,差别在于SDK是完全封装好的内容;对于混合型语言来说,使用Agent的方式实现,比如Java探针在JavaSE的Instrumention上做开发,在Java代码编译的时候进行了代码注入,Java探针依附在Java进程里,不会创建新的进程,而是创建多个线程来采集和汇总数据,如下图所示 用户的类A.class通过ClassLoader装载进JVM时会调用Javaagent嵌入监控代码生成A'.class,当有用户请求进来时,Engine会找到A'.class执行正常的业务逻辑,逻辑执行完毕后Engine会将监控Data写入监控数据缓存区(即一次采集周期),并且每隔60s会向Server发送数据,清理缓存区。

探针采集了应用运行函数的时间运行轨迹、调用数据库、第三方服务、消息中间件、下一个业务系统的时长和调用语句,经过后端处理分析,呈现给用户应用调用全链路拓扑图、函数执行堆栈、函数响应时间和调用次数、慢/错SQL语句、慢外部调用语句,帮助研发人员了解整体业务运行情况,快速定位分析后端错误、优化应用性能。
网络监控
对于网络监控,主要是获取应用运行过程中的网络情况定位数据传输过程中的网络问题。实现方式是探针安装用户的数据中心,通过将流经交换机的流量拷贝出来(即旁路镜像),解析网络协议(如TCP、SNMP)获取数据,然后将数据发送给后端进行处理分析,最后在前端呈现给用户。用户通过网络监控可获取网络流量、吞吐量、带宽利用率、丢包率、包连接情况、连接尝试情况、建链时间、网络传输时间、URL页面耗时、SQL执行耗时等,快速定位网络问题、带宽问题,优化网络使用情况。这种方式最大的好处就是对用户业务没有入侵,因为是将流量完全拷贝出来再做分析处理,通常银行、金融等对业务可用性要求极高的行业会使用此类监控方式。
日志监控
日志即服务的运行轨迹,所有的服务在运行中都会产生日志,主要有主机日志、网络设备日志、应用日志、中间件日志、数据库日志等五种类型。日志监控的实现逻辑是通过日志探针、上传日志、对接MQ队列接口获取数据源,再给到后台处理分析,最后在前端呈现。用户可在前端根据业务出现问题的时间范围来获取该段时间内的日志,也可以输入关键字进行搜索日志,通过日志可了解应用的原生运行情况,帮助研发人员快速定位问题。日志平台最重要的两个能力是存储大量数据、快速搜索能力,对于搜索来说一般采用Eleasearch大数据来提供数据的存储和搜索功能。
基础设施监控
基础设施包括物理机房、服务器、网络设备、中间件、数据库、存储、虚拟化等,对于基础设施的监控则包含该机房运行环境的温度湿度、服务器的CPU内存磁盘网络、数据库的数据库类型、版本、字符集、IP端口、状态、安装路径和数据库大小等。对于非物理机房类型的实现逻辑是通过各种协议(SNMP、WMI、Telnet、SSH、IPMI、JMX、JDBC、Agent等)对各种原始数据进行采集,再通过协议解析数据,后台处理加工,前台呈现给到用户;对于物理机房的实现逻辑是通过API接口调用服务器的数据。运维人员通过基础设施监控,便能全景了解整个业务物理情况,当机房断电或服务器CPU内存指标异常时,通过升级硬件的方式便能解决问题。
通过上述各类监控平台的介绍,相信你对监控产品的类别、监控的使用与价值、实现原理已经清晰了吧。对于研发人员来说,选对了监控产品,在业务运行过程中便能事半功倍,大幅度提高开发效率;对于运维人员来说,选对了合适的监控产品,在业务运维过程中也更能保障业务的正常运行,提高用户满意度;对于想入门监控的同学来说,每一个方向的监控原理和用户价值都很清晰了,结合自己兴趣,选择最适合自己的运维监控领域即可。