概述
分布式系统主要用于解决单机在处理高并发请求,海量数据存储和海量数据计算分析时的瓶颈,通过将系统拆分为各个子系统,各个子系统可以在各自的机器上部署从而来实现整个系统的横向拓展。其中针对系统业务的差异,分布式系统设计的思路也会存在差异,以下主要是针对企业级应用服务,数据存储访问,数据计算分析服务来做个分析。
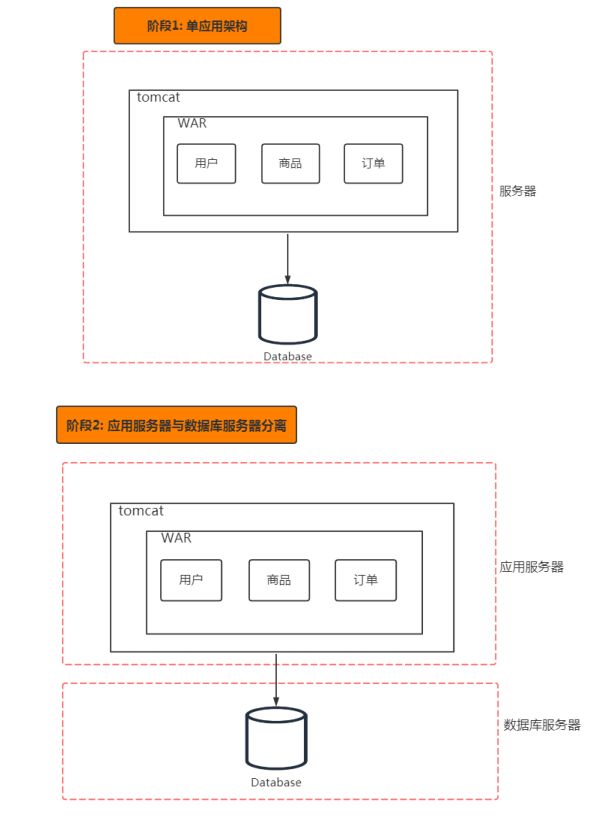
1. 企业应用服务
(1)集群部署
应对高并发请求的处理,同一个服务部署多个节点来解决单机处理能力有限和单点问题,而实现这个的前提是服务节点的无状态,即不在服务进程进程的内存维护数据,这样每个服务节点都可以随时停止运行和重启。通过负载均衡机制来将请求分散到这多个服务节点,从而实现动态的横向拓展;
(2)分布式应用
分布式应用是指一个系统由多个子服务组成,每个子服务对应一个独立的进程,部署在不同的节点,各子系统通过网络来进行交互协作,所以服务请求的处理开销主要是在网络通信方面。分布式应用相对于单体应用虽然由于各子服务需要通过网络来进行协作而增加了网络开销,但是提高了应用的拓展性,可维护性,并发性,可靠性和整体的性能,不过也存在缺点就是服务调用追踪更加复杂,网络的不稳定性增加了服务调用的时间延迟和出错的概率。
2. 数据存储服务
应对海量数据的存储,分散数据到多个节点存储来解决单机存储空间问题,同时每个数据节点包含多个备份节点来实现数据冗余存储来避免节点宕机导致数据丢失,但是需要在多个主从数据节点之间进行数据同步来保持数据一致性。所以数据存储访问的分布式系统设计一般需要考虑数据的复制同步和数据一致性要求,即通常需要在数据可用性和数据一致性之间做个折中,如果要强一致性,则每次数据写入都需要在主从节点之间写入成功才返回,在这个过程中客户端无法读取这个数据;如果要求可用性,则可以在主节点写入成功,或者部分从节点写入成功,如Quorum机制,则成功响应客户端。
3. 数据计算服务
应对海量数据的离线和实时计算分析,首先数据计算通常涉及海量数据,而数据通常被分散存储在多个节点来解决单机存储空间的问题。为了提高计算速度,需要在每个数据节点进行计算,然后在主节点进行结果汇总。而数据计算方面为了避免数据通过网络传输,通常计算任务调度服务会将计算任务分配到数据节点上来进行计算,在计算完成时只需要同步计算结果给主节点汇总即可。
CAP理论与BASE理论
以上系统都设计到多个子节点和不同节点之间数据存在相关性,如企业的分布式应用就是一次请求调用涉及的多个子服务的各自数据,数据存储访问就是一个数据的多个备份数据。而由于是存在于不同机器节点的服务,需要通过网络来通信协作,而网络的不稳定是固然存在的。所以也就产生了分布式系统设计的CAP理论来阐述分布式系统只能存在数据强一致性和服务高可用的其中一种,二者无法同时满足。而在实际进行分布式系统设计时,则一般基于BASE理论,即基本可用,软状态和最终一致性。