作者:汉朝,阿里云数据库算法专家
互联网时代个性化推荐已经渗透到人们生活的方方面面,例如常见的“猜你喜欢”、“相关商品”等。互联网能够对用户投其所好,向用户推荐他们最感兴趣的内容,实时精准地把握用户兴趣。目前很多成功的手机App都引入了个性化推荐算法,例如,新闻类的有今日头条新闻客户端、网易新闻客户端、阿里UC新闻客户端等;电商类的有拼多多、淘宝、天猫等。分析型数据库PostgreSQL版推出的向量分析「链接」可以帮助您实现上述个性化推荐系统。
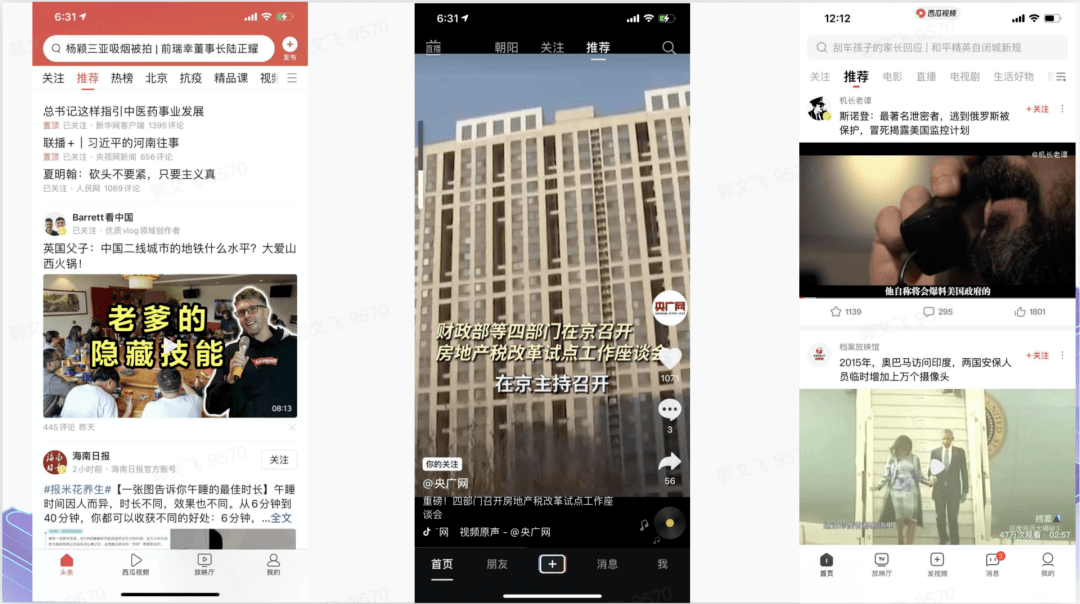
以个性化新闻推荐系统为例,一篇新闻包含新闻标题、正文等内容,可以先通过NLP(Neuro-Linguistic Programming,自然语言处理)算法,从新闻标题和新闻正文中提取关键词。然后,利用分析型数据库PostgreSQL版向量内置的文本转换为向量函数,将从新闻标题和新闻正文中提取出的关键词转换为新闻向量导入分析型数据库PostgreSQL版向量数据库中,用于用户新闻推荐,具体实现流程如图1所示。

图1.推荐算法整体框架
整个新闻推荐系统由以下步骤实现:
分析型数据库PostgreSQL版内置的文本转换为向量函数采用BERT(Bidirectional Encoder Representations from Transformers)模型,同时支持中文和英文两种语言。该模型基于大量的语料进行训练,其中包含了语义信息,而且其查询精度比简单的TF-IDF(term frequency–inverse document frequency)算法高。
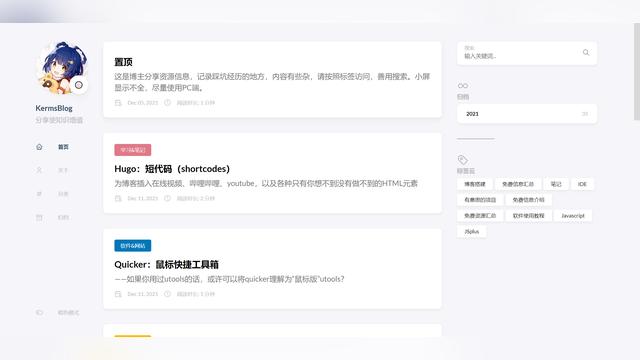
图2是个性化新闻推荐系统中分析型数据库PostgreSQL版数据库表结构设计,系统包含了三张表(News, Person,Browses_History),分别存储新闻信息、用户基本信息、用户浏览记录。

图2. 个性化推荐系统分析型数据库PostgreSQL版表结构
我们对着三张表进行分别介绍:
• News表存储新闻信息,包含新闻id(news_id)、新闻创建时间(create_time)、新闻名字(title)、新闻内容(content)、总的用户点击数(click_times)、两个小时内的用户点击次数(two_hour_click_times)。根据新闻的名称和内容得到新闻的关键词keywords,然后将新闻的关键词转化成向量(news_vector)。向news表中插入数据时,系统自动根据关键词转换为向量,将向量和其他新闻信息一起插入news表。
CREATE TABLE news (
news_id bigint,
create_time timestamp,
title varchar(100),
content varchar(200),
keywords varchar(50),
click_times bigint,
two_hour_click_times bigint,
news_vector real[],
primary key (news_id)
) distributed by (news_id);
• Browses_History表记录用户浏览的新闻的情况,包括新闻id(news_id)、用户id(person_id)、用户浏览新闻的时间(browse_time)。
CREATE TABLE browses_history (
browse_id bigint,
news_id bigint,
person_id bigint,
browse_time timestamp,
primary key (browse_id)
) distributed by (browse_id);
• Person表记录用户信息,包括用户的id(person_id)、用户的年龄(age)、用户的星级(star)。
CREATE TABLE person(
person_id bigint,
age bigint,
star float,
primary key (person_id)
) distributed by (person_id);
分析型数据库PostgreSQL版通过内置的文本转换为向量函数,抽取新闻特征向量,然后将新闻特征向量存入新闻表news中。例如,执行以下SELECT将返回文本“ADB For PG is very good!”对应的特征向量。
select feature_extractor('text', 'ADB For PG is very good!');
假设新闻如下图所示,通过以下两个步骤将新闻信息存入新闻表news表中。

(1)提取新闻关键词。由于分析型数据库PostgreSQL版暂时不支持关键词提取函数,您可以调用jieba结巴中文NLP系统)中的关键词抽取函数(
jieba.analyse.extract_tags(title + content, 3))提取关键词。
(2)执行INSERT将新闻信息(包含关键词和新闻特征向量)存入新闻表news表中。
insert into news(news_id, create_time, title, content,
keywords, click_times,two_hour_click_times)
values(1, now(),'韩国军方:朝鲜在平安北道一带向东发射不明飞行物','据韩国联合参谋本部消息,当地时间今天下午16时30分左右,朝鲜在其平安北道一带向东发射不明飞行物。', '韩国 朝鲜 不明飞行物', 123, 3);
(1)提取用户浏览关键词。根据用户的新闻浏览日志,我们很容易得到用户的浏览关键词。例如,执行以下SELECT得到用户 person_id为9527的浏览关键词。
select keywords
from Person p, Browses_History bh, News n
where p.person_id = bh.person_id and bh.news_id = n.news_id and p.person_id = 9527;
(2)将用户浏览关键词转换为用户特征向量。将用户浏览关键词全部提取出来之后,就可以得到用户总的浏览关键词 。例如,用户person_id为9527浏览了关键词为“NBA 体育”、“总决赛”、“热火”、“火箭”的新闻。然后通过文本转换为向量函数,将用户person_id为9527浏览的关键词转换成向量。
select feature_extractor('text', 'NBA 体育 总决赛 热火 火箭'));
通过用户特征向量,到新闻表news中查询相关的新闻信息。例如,执行以下SELECT将返回和用户相关的前500条新闻,同时系统也会过滤掉用户已经阅读过的文章。获取新闻推荐结果之后,应用就可以将用户感兴趣的新闻推荐给用户了。
select news_id, title, content, (extract(epoch from (now()-create_time)) * w1 + click_times/extract(epoch from (now()-create_time)) * w2 + two_hour_click_times/extract(epoch from (now()-create_time)) * w3 + ann_distance * w4) as rank_score
from (select *, l2_distance(news_vector, feature_extractor('textf', 'NBA 体育 总决赛 热火 火箭')) as ann_distance from news order by ann_distance desc limit 500) S
order by rank_score desc;
参数说明:
• ann_distance:用户与新闻的相关度。
• create_time:新闻的创建时间。
• click_times/(now()-create_time):新闻热度点击率。
• two_hour_click_times/(now()-create_time):新闻近期热度点击率。
• w1、w2、w3、w4:逻辑回归模型学习中各个属性的权重。