|
 |
怎样更好地吸引百度蜘蛛爬取网站?想让蜘蛛抓取网站内容,想要吸引蜘蛛的青睐,需要很多技巧,下面带大家一起来了解一下。1.新站提交文章链接网站是新站的话,百度蜘蛛自然是不太感兴...【详细内容】 |
| 2023-12-18 网络营销 |
|
 |
什么是Python爬虫框架?就像超市里有卖半成品的菜一样,Python爬虫工具也有半成品,就是Python爬虫框架。就是把一些常见的爬虫功能的代码先写好,然后留下一些借口。当我们在做不同...【详细内容】 |
| 2023-12-08 Python |
|
 |
在信息时代,数据是无处不在的宝藏。从网页内容、社交媒体帖子到在线商店的产品信息,互联网上存在着大量的数据等待被收集和分析。Python爬虫是一种强大的工具,用于从互联网上获...【详细内容】 |
| 2023-10-21 Python |
|
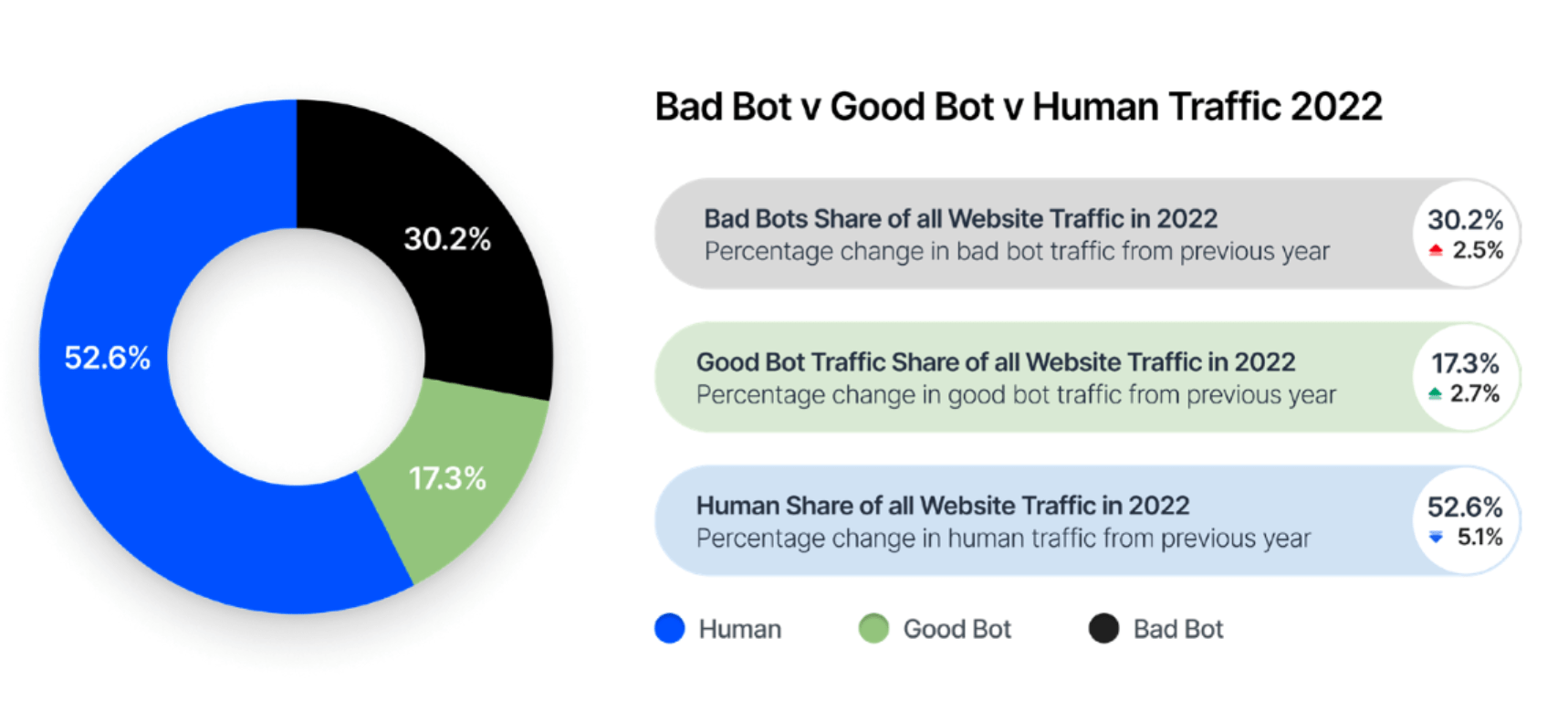 |
引言 如果您仔细分析过任何一个网站的请求日志,您肯定会发现一些可疑的流量,那可能就是爬虫流量。根据 Imperva 发布的《2023 Imperva Bad Bot Report》在 2022 年的所有互联...【详细内容】 |
| 2023-09-06 编程百科 |
|
 |
Python爬虫是一种用于自动化网页数据抓取的技术,它能够帮助我们快速、高效地获取互联网上的数据。对于那些想要快速入门学习Python爬虫的人来说,可能会有一些困惑:如何才能快速...【详细内容】 |
| 2023-08-30 Python |
|
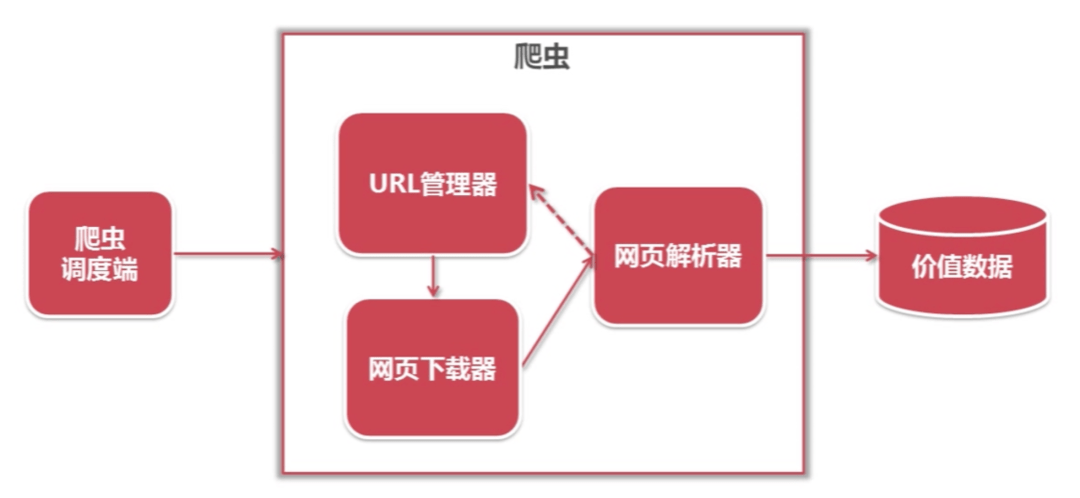 |
你听过爬虫吗?计算中的爬虫,又称为网络爬虫、网页蜘蛛、网络机器人,它是一段计算机器代码,可以自动抓取网页上的数据。网页是由什么组成呢?网页一般由文本、图像、音频、视频等元...【详细内容】 |
| 2023-08-18 Python |
|
 |
大多数人可能并不知道,我们浏览和创建的网站上充斥着各种数字蜘蛛。其中最活跃的蜘蛛可能就是谷歌爬虫,它自动收集网页信息,以便谷歌可以在搜索结果中对其进行排名和展示。就在...【详细内容】 |
| 2023-08-10 网站 |
|
 |
什么是网络爬虫?网络爬虫是一种自动化程序,用于抓取互联网上的数据。网络爬虫可以自动访问网页、解析网页内容、提取所需数据、存储数据等。通过使用网络爬虫,我们可以获取大量...【详细内容】 |
| 2023-05-17 Python |
|
 |
在数据分析的过程中,我们常常需要用到stata软件进行数据处理。而在获取数据时,很多时候需要用到爬虫技术。但是,使用stata进行爬虫时,会遇到乱码问题。本文将介绍如何解决stata...【详细内容】 |
| 2023-05-06 电脑软件技术 |
|
 |
在当今数字化世界中,WordPress已成为许多人创建自己的网站的首选平台。然而,仅仅创建一个WordPress网站并不足以吸引足够的流量。为了达到这一目标,使用爬虫技术是至关重要的。...【详细内容】 |
| 2023-04-28 网站 |
|
 |
网络爬虫是一种自动化程序,可以获取互联网上的数据并将其存储在本地计算机上。Python是一种功能强大的编程语言,广泛用于Web开发、数据分析和科学计算。在本文中,我们将详细介...【详细内容】 |
| 2023-04-26 Python |
|
 |
本次通过猫眼电影,对春节贺岁大片【满江红】进行数据分析。而本次我们通过动态接口形式获取评论信息,静态HTML解析需要额外的字体解析,网上的教程也已经很全了,有兴趣的小伙伴们...【详细内容】 |
| 2023-03-24 Python |
|
 |
《硕宇精选》专注于探索、发现、分享开源技术应用和优质开源项目。本期推荐的优质项目是开源的智能爬虫系统,新一代爬虫平台,以图形化方式定义爬虫流程,不写代码即可完成爬虫。...【详细内容】 |
| 2022-10-04 编程百科 |
|
 |
要在 Python 中构建一个简单的网络爬虫,我们至少需要一个库来从 URL 下载 HTML,还需要一个 HTML 解析库来提取链接。Python 提供标准库urllib用于发出 HTTP 请求和html.parser...【详细内容】 |
| 2022-09-06 Python |
|
 |
简介从上面两节实战中已经可以做一个属于自己的翻译应用了,甚至可以对翻译结果进行对比然后通过一些语意软件进行优化,这里的所有的DEMO都只是为了学习JS逆向这些技能的过程,今...【详细内容】 |
| 2022-08-03 编程百科 |
|
 |
Beautiful Soup 简介Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据的 Python 库,它提供了一些简单的操作方式来帮助你处理文档导航,查找,修改文档等繁琐的工作。因...【详细内容】 |
| 2022-07-04 Python |
|
 |
#coding=utf-8import requestsimport osimport jsonfrom jsonpath import jsonpathimport timeurl='https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/...【详细内容】 |
| 2022-06-29 Python |
|
 |
在学习爬虫前,我们需要先掌握网站类型,才能根据网站类型,使用适用的方法来编写爬虫获取数据。今天小编就以国内知名的ForeSpider爬虫软件能够采集的网站类型为例,来为大家盘点一...【详细内容】 |
| 2022-06-16 网络技术 |
|
 |
私信里经常有人问:为什么自己的爬虫明明设置了代理,但一访问网站就能被发现。我总结了几种常见的情况。实际上,网站要识别你是否使用了代理,并不一定非要什么高深的反爬虫机制,也...【详细内容】 |
| 2022-04-01 Python |
|
 |
前言目前是直播行业的一个爆发期,由于国家对直播行业进行整顿和规范,现在整个直播行业也在稳固发展。随着互联网和网络直播市场的快速发展,相信未来还有广阔的发展前景。今天用...【详细内容】 |
| 2022-03-15 Python |
|
 |
《开源精选》是我们分享Github、Gitee等开源社区中优质项目的栏目,包括技术、学习、实用与各种有趣的内容。本期推荐的是一个使用 Python 编写的轻量级百度爬虫—&mdash...【详细内容】 |
| 2022-02-21 Python |
|
 |
如今,很多互联网创业者若是需要爬出大量数据一般会使用代理工具。代理服务器位于您的设备和互联网之间。因此,在使用代理时,您将无法直接访问Internet,但您的Web请求将首先通过...【详细内容】 |
| 2022-02-14 网络技术 |
|
 |
在我没接触这一行时这个问题困扰了我很长时间,让我十分的不理解到底什么是爬虫,它难道是一种实体工具?,直到我学习python 深入分析了解以后才揭开了它神秘的面纱。 爬虫是什么呢...【详细内容】 |
| 2022-02-10 编程百科 |
|
 |
利用Python实现中国地铁数据可视化。废话不多说。让我们愉快地开始吧~开发工具Python版本:3.6.4相关模块:requests模块;wordcloud模块;pandas模块;numpy模块;jieba模块;pyecharts模...【详细内容】 |
| 2021-12-08 Python |
|
 |
这个开源项目程序可以持续爬取一个或多个新浪微博用户(如李文di、无疫烦)的数据,并将结果信息写入文件或数据库。写入信息几乎包括用户微博的所有数据,包括用户信息和微博信息两大类。...【详细内容】 |
| 2021-10-27 Python |
|
 |
回顾python学习历程,感慨良多,这门语言实在是太强了,当然,分支也很多,有的在做安全,有的在做数据,有的在做爬虫,本文就笔者本身的爬虫入门的小经验分享给读者,期待各位在学习python的...【详细内容】 |
| 2021-08-11 Python |
|
 |
上次写的如何给小孩约马术课过程,见这里 Python 约课[1], 本想一劳永逸,但是好景不长,预约系统升级了,而且还换了服务商,从之前的公众号 H5 应用,换成了小程序,之前编写的方式直接失...【详细内容】 |
| 2021-05-07 Python |
|
 |
众所周知,代理IP可以助力爬虫工作更好的进行,很多人认为:如果没有代理IP,爬虫工作寸步难行。那么,如果爬虫不使用代理IP会出现什么情况呢? 一、小型爬虫:可有可无爬几百篇文章,几百...【详细内容】 |
| 2021-05-07 Python |
|
 |
前言 将爬虫的爬取过程分为网络请求,文本获取和数据提取3个部分。 信息校验型反爬虫主要出现在网络请求阶段,这个阶段的反爬虫理念以预防为主要目的,尽可能拒绝反爬虫程序的请...【详细内容】 |
| 2021-04-20 Python |
|
 |
在了解爬虫基础、请求库和正则匹配库以及一个具体豆瓣电影爬虫实例之后,可能大家还对超长的正则表达式记忆犹新,设想如果想要匹配的条目更加多那表达式长度将会更加恐怖,这显然...【详细内容】 |
| 2021-04-12 Python |
|
|
|
