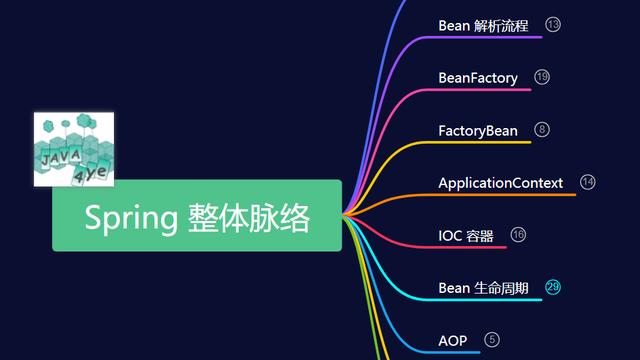
前面一篇文章我讲了一下Web应用程序的基础,主要是基于网络连接的I/O数据处理,为了对网络上传输的数据进行处理,我们首先必须清楚的了解网络传输的数据是二进制数据流由网络协议定义的数据包长短,格式等来进行分拆和封装。
通过对网络上节点的标识信息,主机名或者IP地址跟应用的端口来标识运行在某台计算机上的某个可以通信的节点。
其实网络技术就是标识节点建立连接,也就是是IP协议为基础标识了节点信息,然后以TCP或者UDP协议为基础进行的网络连接和数据传输。
在硬件方面这主要体现在一台计算机通过网卡来管理网络连接,网卡会将接收到的数据包拷贝到操作系统管理的输入/输出缓冲区里,我们应用程序或者说我们编写的程序会创建一个自己的缓冲并连接到一个对于网络数据进行处理的通道上,而这个通道是基于网络套接字协议创建的数据流通道,我们可以用它来读取网卡接收到的数据,并在通道和缓冲区操作期间对数据进行加工处理。
这个过程反应在应用程序内存,操作系统内存以及网卡管理的内存之间的数据拷贝。
简单了解了上面基于网络连接和数据传输以及在操作系统底层数据处理的基础后,我们就开始在这个底层网络数据流基础上构建我们的web应用程序了。
前面我们介绍了关于Web应用程序的特点,就是基于底层网络数据流处理的应用,所以必须现有网络数据流作为基础,而在我们现代的高级编程语言中已经将这些底层数据处理编写成了许多优秀的组件类库,我们可以直接使用,甚至将它们以规范的形式规定在了基础容器实现里。
比如我们介绍的Servlet规范,它提供了底层网络数据的封装和管理以及对宿主计算机环境的集成。
让我们可以使用JAVA语言不需要关心网络连接和底层二进制数据的处理而直接按照一定的规则来对输入的网络数据流进行处理,让后将处理结果通过固定的形式传递给网络进行输出。
Servlet原意是服务器小程序,它固定了一些基于服务器运行的小程序的相关的规范。
它首先对服务器环境进行了规定,对底层的基于网络的点对点之间的数据流进行了封装,这种封装就是在底层对网络传输的数据流按照某种约定的规则进行封装,这就是协议层级的应用处理,它是在网络服务器应用程序和操作系统以及网卡管理的输入输出控制器之间的数据拷贝和编解码过程。
我们知道在操作系统层级,它是一个管理和调度我们机器硬件的应用程序,而调度的对象就是CPU和内存,而网卡作为一个系统硬件它具备自己的驱动应用程序它在操作系统上运行,会有一个独立的管理的输入输出缓冲区,每次的输入输出数据流处理都只是通过相应事件触发来通过CPU的中断处理机制来完成的。
对于我们开发人员来说,我们需要做的就是借用Web服务器的底层处理提供的API来直接编写处理数据的组件,而Web服务器一般都是根据Servlet规范来实现的应用。
它负责根据服务器信息和资源路径来建立连接并传输和接收数据,并将数据转换为遵循某种协议的标准格式,我们Servlet规范主要是基于HTTP/1.1协议的,Servlet 3.0增加了反应式编程模型,到了Servlet 4.0将支持HTTP/2规范。
而我们在Web容器层级,它是一个运行在操作系统的中间服务程序,它的作用是负责跟操作系统交互同时为我们的具体服务组件的运行提供支持。
它涉及到数据流的接收,解析,转换和封装底层的操作。基本上就是实现将二进制的字节流根据规定好的协议结构读取并转换为我们应用程序能够使用的格式和数据类型。
对于网络数据流的接收和处理方式,从阻塞型,即获取一定数据后就停止接收数据,然后调用对应的处理程序进行处理,直到处理完成一个请求数据后,才会开始再次接收后面数据。
为提高性能,我们提供了对应处理组件的线程池,由特定的管理程序根据情况调度,即将一个服务处理组件实例化多个提供给进入的数据流请求调用,处理完成后,将服务组件归还给某个调度管理器,以备后面的请求使用。
随着应用程序的复杂程度加大,为了获取更好的处理性能,我们开始采用异步方式来处理,也就是由独立的线程负责接收请求,然后将请求交给工作线程处理,它不会阻止其继续接收请求。而在请求处理完成时,会向系统发送通知,通过线程中断处理来响应通知,如此以来可以使用较少的线程获取高效率,提高应用的反应效率。
当然这种反应式异步处理的开发模型是建立在Java NIO数据流模型基础上的。
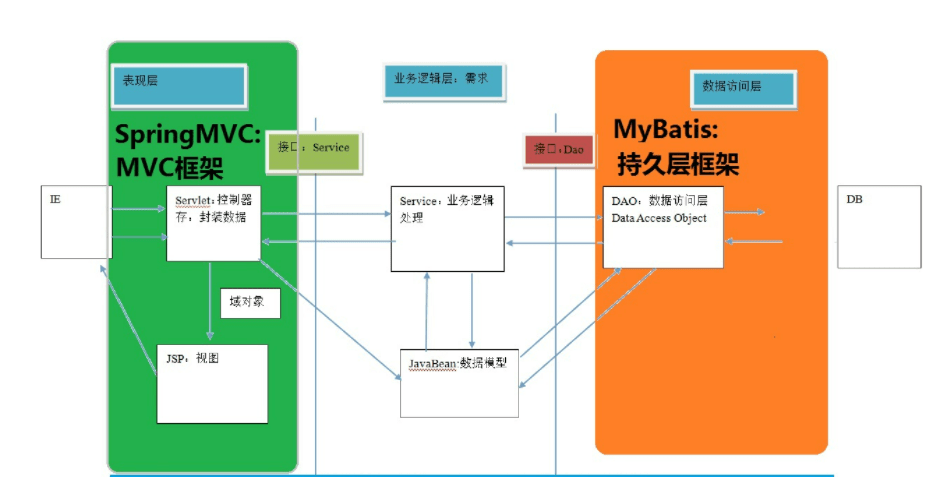
前面我们说过,Spring框架的优势在于它在Servlet级别上提供了一个开发复杂应用的组件容器,而且这个容器是实现了可配置的工厂模式,也就是说在容器初始化时,它会将组件服务实例化或者将其相关联的组件定义配置好,在需要时动态的去实例化对象。
开发人员在使用Spring框架进行开发时,基本上是将自己应用程序的数据类型和逻辑组件都作为Spring容器管理的组件,对于组件的构建和销毁以及整个调用过程的管理都由Spring容器来完成。
开发人员只需要将定义的数据类型和组件告诉容器,让它遵循容器管理的规则即可。
为此Spring容器为了获取它能管理哪些数据类型或者逻辑组件实现类,它通过读取特定格式的花名册来完成,比如有XML,YML以及Annotation或者代码等格式。
其实其本质都是一样的就是工厂模式,将构建某个依赖项的工作交给专门干这件事的人,我们可以理解为我们有无数的人将创建自己实例的任务交给了一个专门做这事的人。
而这里这个人就是Spring容器,我们只需要在任何一个需要构建的数据类型或者组件时,将这个能够创建依赖的对象提供给它即可。我们称这个被委托者为容器。
它会在启动时读取需要使用的所有组件和数据类型定义信息,并将它们初始化实例放入到其管理的内存空间里,并为每个实例定义唯一标识,并工作这些内容来获取其对应的对象实例。
上面对前面说的内容做了简单的回顾,是为了能够衔接后面所要说的内容,如此是为了想连贯的从底层网络数据流到如何被封装进入我们开发语言运行的领域,以及我们如何在应用程序层级上对数据流的设计和管理,从而能够网络技术,数据编解码,Web服务器,高级的应用程序开发框架能够串联起来,找出它们之间的关联,它们为什么要如此设计,以及它们解决的问题什么,来帮助初学的小伙伴将自己所学的知识串联成一个完整的技术图谱,更加宏观的掌握技术思路,为以后开拓创新打好基础。
由于现在在网络上文章过长就没有人愿意读了,所以每次写都没组织好,由于字数问题而不得不中断,不过我会尽量的连贯的去说。