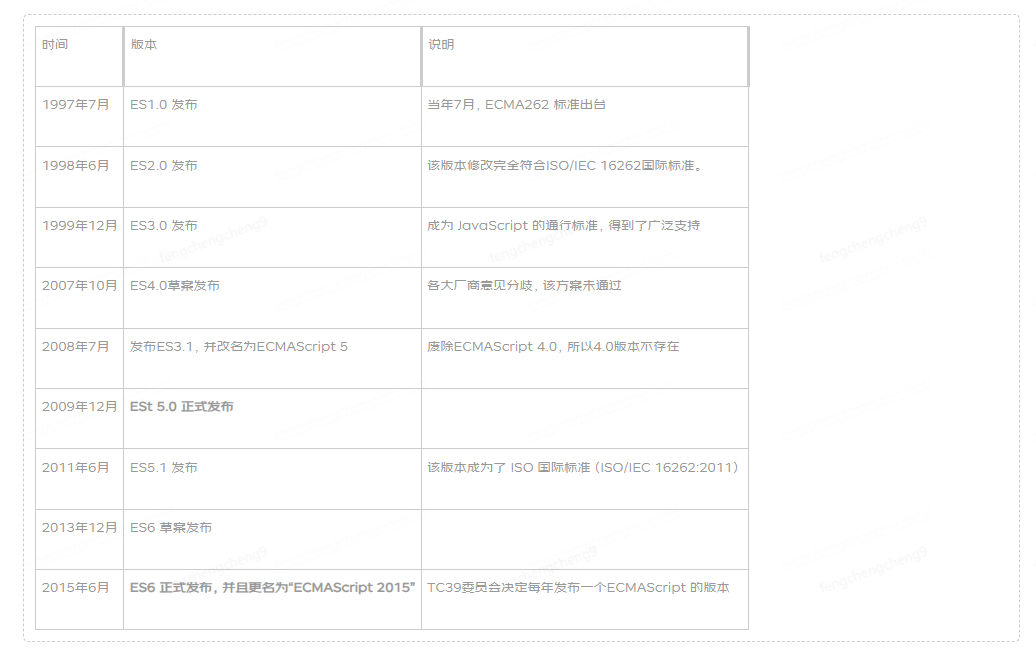
本文将介绍接下来的技巧和主题:
让我们切入正题,回顾一下我们将在示例中使用的类。我们将改变其结构并逐步估计其大小四次。

计算第一个快照大小
如上所述,我建议查看之前的文章以了解内存计算过程。在我们的例子中,我们将使用基于 64 位 JAVA 的计算。我们将使用Alexey Shipilev开发的JOL核心库验证所有计算。您可以在本手册中找到此库的示例。
启动用户对象
首先,让我们创建 3 个对象并设置所有字段。在我们的示例中,我们将使用所有唯一对象,甚至对于布尔值,我们也将使用新实例(通过使用)。在这种情况下,我们的计算将是最悲观的(从大小的角度来看),但完全正确:new boolean

现在让我们计算每个对象的大小(再次考虑到甚至所有布尔实例都是唯一的):

所以毕竟,总大小的实例是 320 字节(包括和实例一起)。为了验证它,让我们使用 JOL 核心库并打印它们的大小:User``UserSalary``UserPayment

打印结果为 56 字节、136 字节和 320 字节。
现在让我们改进这个荒谬的例子并正确启动布尔值。
在前面的示例中,我将布尔值作为唯一对象启动。在这里,我们将以重用sameandreferences的方式启动(这也是你经常初始化它们的方式)。通过这样的初始化,我们的例子将更加现实。(此步骤不是优化,它只是解释内存计算如何工作的附加步骤。Boolean.true``Boolean.false

现在我们必须重新计算所有对象,因为我们基本上改变了布尔初始化:

打印结果符合预期:56 字节、136 字节和 208 字节(从 320 字节减少)。
第一个内存优化:用基元替换所有包装器
在这里,我们通过仅使用原语而不是包装器对象来进行第一次真正的优化。在这种情况下,我们将失去空收益选项,默认情况下将初始化所有值。

现在,让我们重新计算快照大小,考虑到所有基元值都没有额外的引用并保留在其容器对象中:

如您所见,所有包装器对象都会添加 16 个额外的字节。这种转换将总大小从 208 字节减少到 112 字节,几乎减少了 2 倍。
第二次内存优化:在一个类中折叠数据
在大多数情况下,这种优化是不可能的,或者至少使 OOP 结构的可读性和可维护性降低;但是在某些内存不足的紧急情况下,您别无选择。因此,让我们将所有字段移动到一个类上,并查看改进:

现在只有一个用户对象,我们也失去了在引用上花费的额外内存。是的,代码更具可读性和可维护性,但我们几乎将大小提高了 2 倍。JOL-Core 库还确认现在的总大小为 64 字节!
第三个内存优化:使用窄类型
如果您检查我们使用的所有类型,您可能会提到其中一些涵盖的范围比我们需要的要大:例如,isvalue 和覆盖范围从 -2147483648 到 -2,147,483,647,但根据我们的业务需求,它不会超过每月 32,767 美元。因此,我们可以使用数据类型而不是整数。同样,我们可以替换**java.sql.Date并只保留长**值(已经是未来和过去的数千年)。salary``int``Short
因此,在我们的例子中,我们将进行以下更改:

现在,快照总大小为 40 字节大小。我们能进一步改进它吗?是的!
第四个内存优化:使用窄类型
在此步骤中,我们将在较大的类型中“隐藏”较小的数据类型。整数值由 2^32 个值覆盖。布尔值由 2^1 覆盖。所以在一个整数中,我们可以“隐藏”32个布尔值。同样的事情可以应用于这些示例:
在我们的示例中,我们将所有 9 个布尔值封装在一个短时间内。我们将使用按位运算(向右、向左移动等)。您可以在本文中找到更多示例。
从布尔值到短线的转换:
转换包括 3 个后续步骤:boolean``short
因此,使用定义的标志顺序如下:

并在一种方法中实现所有步骤:

现在有了这个函数,我们可以在一个单一中隐藏值:boolean``short

从短值中揭示隐藏的布尔值
为了识别哪个标志具有什么值,我们需要进行向后转换:
所有步骤如下所示:

现在使用所有这些函数,我们可以尝试隐藏下一个值:
我们的最终值是229,或者可以用二进制格式表示为011100101并表示下一个值,如下所示:

现在有了这个结果值,我们可以使用并得到一个特定的封装布尔值:mask

最终的计算是 我们类的总大小为 32 字节。User

结论
在我们的示例中进行了四次转换之后,我们得到了下一个足迹改进:

完成所有转换后,我们将类的大小从 208 字节减少到 32 字节,几乎减少了7 倍。我们的对象更难读取和维护,但内存消耗急剧下降。在节省 1000 万用户的情况下,我们只需要 320MB 而不是 2.1GB。