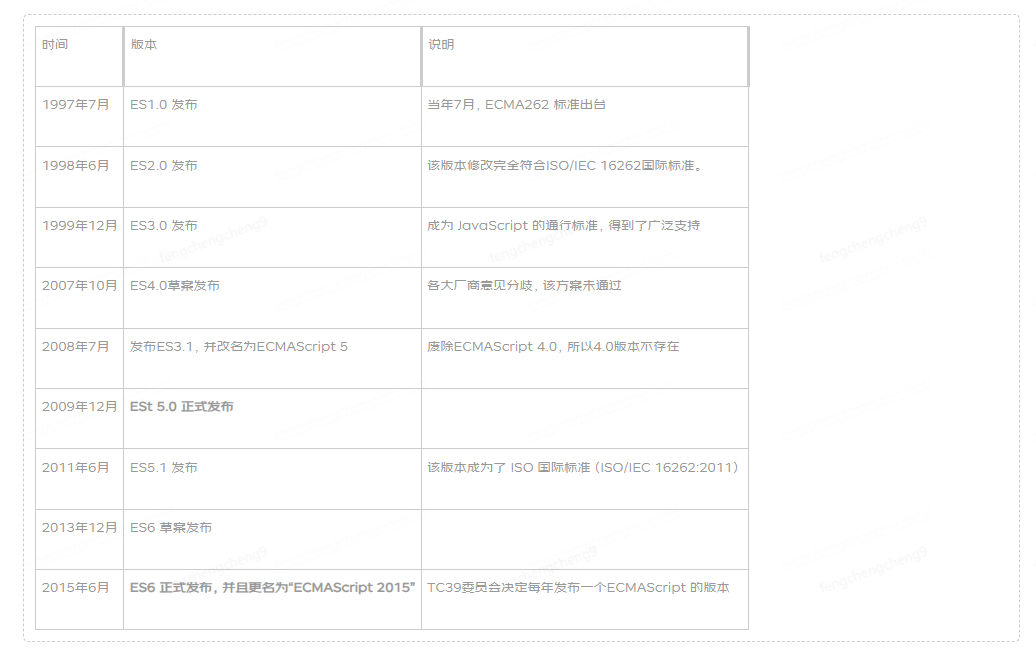
在本文中,我们将研究Dynatrace在托管多个JVM的机器上报告的内存饱和错误的解决方案。
在linux机器上,当内存使用率超过80%且页面错误超过每秒20个页面错误时,Dynatrace会抛出内存饱和错误。若想要更加系统更加详细的学习 JVM 知识,建议参加JAVA培训,有经验丰富的专业讲师面授指导教学,能够帮你更全面了解JVM。
我们假设我们使用的是一台具有128GB内存的Linux机器,6个应用程序JVM正在运行,16GB被设置为最小和最大堆大小。如果JVM开始消耗更多内存,可能会引发内存饱和错误。当最小(-Xms)和最大(-Xmx)堆值设置为16GB时,系统将为每个JVM向堆提交16GB的RAM空间。JVM将使用这个16GB用于堆,除此之外,它还需要更多的内存来进行处理。总体而言,每个JVM可能需要大约20GB的内存来完成处理,这取决于每个JVM的请求。在某一点上,所有6个JVM都可能使用大约120GB的内存,从而导致该机器中出现内存饱和错误和页面错误。

有三种方法可以解决这个问题。
第一个也是最简单的方法是向现有机器添加更多内存。如果我们在这台机器上再增加128GB,将内存增加一倍,这将使这台机器总共拥有256GB的内存。现在,在我们的情况下,如果进程消耗256GB中的120GB,这不到总内存使用量的50%,并且不会达到80%的内存使用阈值。此外,由于内存中有空间容纳所有页面,因此不会发生页面错误。Dynatrace将消除内存饱和错误。这种方法的缺点是,如果它是数据中心中的一台机器,最终将导致硬件采购成本。如果它是一个云实例,它将占用一个具有更多内存的实例,这将导致额外的成本。在java培训中,也有关于JVM内存的学习,学好这部分的知识,可以避免在工作中出现的很多问题。
第二种方法是调查JVM是否需要那么多内存,并对其进行优化。这种方法需要进行详细分析,以确定占用更多内存的区域,优化并降低内存使用率。这将有助于减少所有6个JVM占用的内存,并在相同的硬件上运行应用程序而不会出现任何内存饱和错误,无需任何升级。这种方法需要时间,具体取决于优化应用程序内存使用所涉及的复杂性。
第三种方法是不对最小和最大堆大小参数设置相等的值。相反,为应用程序所需的最小堆大小参数设置一个最小值。例如,将最小堆大小(-Xms)设置为4GB,将最大堆大小(-Xmx)设置为16GB。这将使系统最初每个JVM只提交4GB的堆大小,从而将整个JVM内存使用量减少到每个JVM 8GB以下。所有6个JVM将占用大约58GB,这将使总内存使用率降至50%以下,并避免内存饱和错误。如果应用程序确实消耗了较少的堆内存,这将起作用。如果堆大小增长到最大堆大小,这可能会成为一个问题,如果所有JVM都达到该值,这将使系统提交16GB,从而导致内存饱和错误。参加java培训学习,可以在短时间内获得很大提升,避免在学习上多走弯路,节省时间,提高学习效率。
在了解堆使用模式后,可以采用这种方法,如果应用程序的堆使用率较低,则会有所帮助。将不同的值设置为最小和最大堆大小可能对堆收缩和扩展影响不大。与系统中发生的页面错误相比,这种影响将更小。
根据发生内存饱和错误的场景,可以应用上述推荐的任何一种或所有方法来解决Dynatrace中的内存饱和错误。想对JVM有更深入的了解,可以参加java培训,在专业老师的指导下,你可以很快掌握JVM的更多特性。