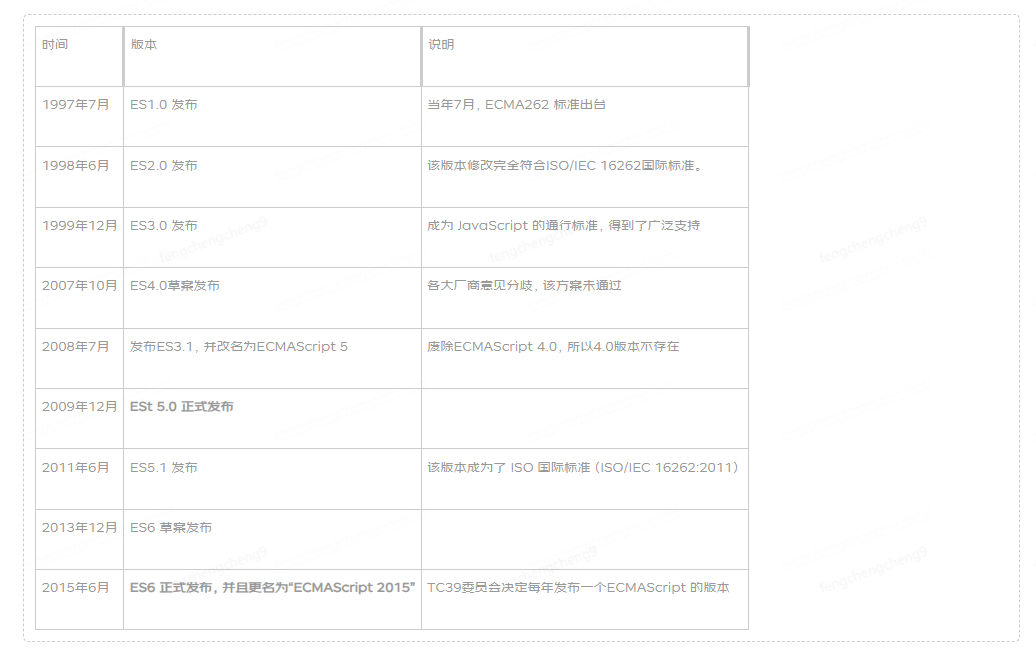
N+1问题:N+1问题是指在使用关系型数据库时,在获取一组对象及其关联对象时,产生额外的数据库查询的问题。其中N表示要获取的主对象的数量,而在获取每个主对象的关联对象时,会产生额外的1次查询。
N+1问题是很多项目中的通病。遗憾的是,直到数据量变得庞大时,我们才注意到它。不幸的是,当处理 N + 1 问题成为一项难以承受的任务时,代码可能会达到了一定规模。
在这篇文章中,我们将开始关注以下几点问题:
假设我们正在开发管理动物园的应用程序。在这种情况下,有两个核心实体:Zoo和Animal。请看下面的代码片段:
@Entity
@Table(name = "zoo")
public class Zoo {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
private String name;
@.NEToMany(mAppedBy = "zoo", cascade = PERSIST)
private List<Animal> animals = new ArrayList<>();
}
@Entity
@Table(name = "animal")
public class Animal {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
@ManyToOne(fetch = LAZY)
@JoinColumn(name = "zoo_id")
private Zoo zoo;
private String name;
}
现在我们想要检索所有现有的动物园及其动物。看看ZooService下面的代码。
@Service
@RequiredArgsConstructor
public class ZooService {
private final ZooRepository zooRepository;
@Transactional(readOnly = true)
public List<ZooResponse> findAllZoos() {
final var zoos = zooRepository.findAll();
return zoos.stream()
.map(ZooResponse::new)
.toList();
}
}
此外,我们要检查一切是否顺利进行。简单的集成测试:
@DataJpaTest
@AutoConfigureTestDatabase(replace = NONE)
@Transactional(propagation = NOT_SUPPORTED)
@TestcontAIners
@Import(ZooService.class)
class ZooServiceTest {
@Container
static final PostgreSQLContainer<?> POSTGRES = new PostgreSQLContainer<>("postgres:13");
@DynamicPropertySource
static void setProperties(DynamicPropertyRegistry registry) {
registry.add("spring.datasource.url", POSTGRES::getJdbcUrl);
registry.add("spring.datasource.username", POSTGRES::getUsername);
registry.add("spring.datasource.password", POSTGRES::getPassword);
}
@Autowired
private ZooService zooService;
@Autowired
private ZooRepository zooRepository;
@Test
void shouldReturnAllZoos() {
/* data initialization... */
zooRepository.saveAll(List.of(zoo1, zoo2));
final var allZoos = assertQueryCount(
() -> zooService.findAllZoos(),
ofSelects(1)
);
/* assertions... */
assertThat(
...
);
}
}
测试成功通过。但是,如果记录 SQL 语句,会注意到以下几点:
-- selecting all zoos
select z1_0.id,z1_0.name from zoo z1_0
-- selecting animals for the first zoo
select a1_0.zoo_id,a1_0.id,a1_0.name from animal a1_0 where a1_0.zoo_id=?
-- selecting animals for the second zoo
select a1_0.zoo_id,a1_0.id,a1_0.name from animal a1_0 where a1_0.zoo_id=?
如所见,我们select对每个 present 都有一个单独的查询Zoo。查询总数等于所选动物园的数量+1。因此,这是N+1问题。
这可能会导致严重的性能损失。尤其是在大规模数据上。
当然,我们可以自行运行测试、查看日志和计算查询次数,以确定可行的性能问题。无论如何,这效率很低。。
有一个非常高效的库,叫做datasource-proxy。它提供了一个方便的 API 来JAVAx.sql.DataSource使用包含特定逻辑的代理来包装接口。例如,我们可以注册在查询执行之前和之后调用的回调。该库还包含开箱即用的解决方案来计算已执行的查询。我们将对其进行一些改动以满足我们的需要。
首先,将库添加到依赖项中:
implementation "net.ttddyy:datasource-proxy:1.8"
现在创建QueryCountService. 它是保存当前已执行查询计数并允许您清理它的单例。请看下面的代码片段。
@UtilityClass
public class QueryCountService {
static final SingleQueryCountHolder QUERY_COUNT_HOLDER = new SingleQueryCountHolder();
public static void clear() {
final var map = QUERY_COUNT_HOLDER.getQueryCountMap();
map.putIfAbsent(keyName(map), new QueryCount());
}
public static QueryCount get() {
final var map = QUERY_COUNT_HOLDER.getQueryCountMap();
return ofNullable(map.get(keyName(map))).orElseThrow();
}
private static String keyName(Map<String, QueryCount> map) {
if (map.size() == 1) {
return map.entrySet()
.stream()
.findFirst()
.orElseThrow()
.getKey();
}
throw new IllegalArgumentException("Query counts map should consists of one key: " + map);
}
}
在那种情况下,我们假设_DataSource_我们的应用程序中有一个。这就是_keyName_函数否则会抛出异常的原因。但是,代码不会因使用多个数据源而有太大差异。
将SingleQueryCountHolder所有QueryCount对象存储在常规ConcurrentHashMap.
相反,_ThreadQueryCountHolder_将值存储在_ThreadLocal_对象中。但是_SingleQueryCountHolder_对于我们的情况来说已经足够了。
API 提供了两种方法。该get方法返回当前执行的查询数量,同时clear将计数设置为零。
现在我们需要注册QueryCountService以使其从 收集数据DataSource。在这种情况下,BeanPostProcessor 接口就派上用场了。请看下面的代码示例。
@TestComponent
public class DatasourceProxyBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) {
if (bean instanceof DataSource dataSource) {
return ProxyDataSourceBuilder.create(dataSource)
.countQuery(QUERY_COUNT_HOLDER)
.build();
}
return bean;
}
}
我用注释标记类_@TestComponent_并将其放入_src/test_目录,因为我不需要对测试范围之外的查询进行计数。
如您所见,这个想法很简单。如果一个 bean 是DataSource,则将其包裹起来ProxyDataSourceBuilder并将QUERY_COUNT_HOLDER值作为QueryCountStrategy.
最后,我们要断言特定方法的已执行查询量。看看下面的代码实现:
@UtilityClass
public class QueryCountAssertions {
@SneakyThrows
public static <T> T assertQueryCount(Supplier<T> supplier, Expectation expectation) {
QueryCountService.clear();
final var result = supplier.get();
final var queryCount = QueryCountService.get();
assertAll(
() -> {
if (expectation.selects >= 0) {
assertEquals(expectation.selects, queryCount.getSelect(), "Unexpected selects count");
}
},
() -> {
if (expectation.inserts >= 0) {
assertEquals(expectation.inserts, queryCount.getInsert(), "Unexpected inserts count");
}
},
() -> {
if (expectation.deletes >= 0) {
assertEquals(expectation.deletes, queryCount.getDelete(), "Unexpected deletes count");
}
},
() -> {
if (expectation.updates >= 0) {
assertEquals(expectation.updates, queryCount.getUpdate(), "Unexpected updates count");
}
}
);
return result;
}
}
该代码很简单:
此外,您还注意到了一个附加条件。如果提供的计数类型小于零,则跳过断言。不关心其他查询计数时,这很方便。
该类Expectation只是一个常规数据结构。看下面它的声明:
@With
@AllArgsConstructor
@NoArgsConstructor
public static class Expectation {
private int selects = -1;
private int inserts = -1;
private int deletes = -1;
private int updates = -1;
public static Expectation ofSelects(int selects) {
return new Expectation().withSelects(selects);
}
public static Expectation ofInserts(int inserts) {
return new Expectation().withInserts(inserts);
}
public static Expectation ofDeletes(int deletes) {
return new Expectation().withDeletes(deletes);
}
public static Expectation ofUpdates(int updates) {
return new Expectation().withUpdates(updates);
}
}
让我们看看它是如何工作的。首先,我在之前的 N+1 问题案例中添加了查询断言。看下面的代码块:
final var allZoos = assertQueryCount(
() -> zooService.findAllZoos(),
ofSelects(1)
);
不要忘记
_DatasourceProxyBeanPostProcessor_在测试中作为 Spring bean 导入。
如果我们重新运行测试,我们将得到下面的输出。
Multiple Failures (1 failure)
org.opentest4j.AssertionFailedError: Unexpected selects count ==> expected: <1> but was: <3>
Expected :1
Actual :3
所以,确实有效。我们设法自动跟踪 N+1 问题。是时候用 替换常规选择了JOIN FETCH。请看下面的代码片段。
public interface ZooRepository extends JpaRepository<Zoo, Long> {
@Query("FROM Zoo z LEFT JOIN FETCH z.animals")
List<Zoo> findAllWithAnimalsJoined();
}
@Service
@RequiredArgsConstructor
public class ZooService {
private final ZooRepository zooRepository;
@Transactional(readOnly = true)
public List<ZooResponse> findAllZoos() {
final var zoos = zooRepository.findAllWithAnimalsJoined();
return zoos.stream()
.map(ZooResponse::new)
.toList();
}
}
让我们再次运行测试并查看结果:

这意味着正确地跟踪了 N + 1 个问题。此外,如果查询数量等于预期数量,则它会成功通过。
事实上,定期测试可以防止 N+1 问题。这是一个很好的机会,可以保护那些对性能至关重要的代码部分。