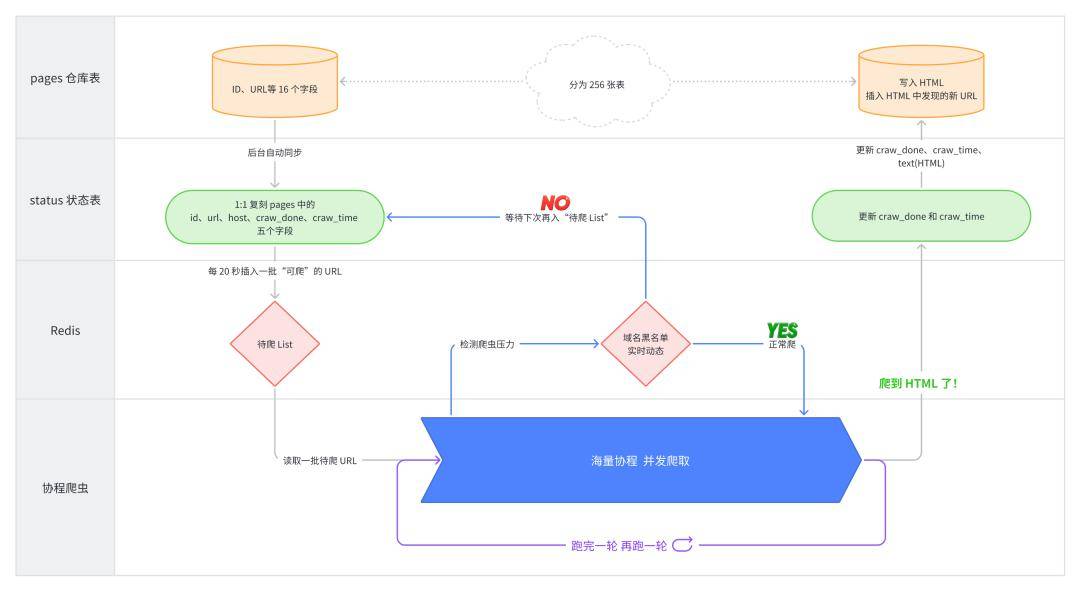
正如你可能之前看到的,Discord去年发布了一篇有价值的文章,讨论了他们成功存储了数万亿条消息。虽然有很多关于这篇文章的YouTube视频和文章,但我认为这篇文章中一个名为“数据服务为数据服务”的部分没有得到足够的关注。在这篇文章中,我们将讨论Discord对数据服务的方法,并探讨如何利用Golang的并发特性来减少特定情况下的数据库负载。
如你所知,消息和频道是Discord中最常用的组件。让我们想象一个场景:一个拥有50万成员的频道的管理员提到@everyone。会发生什么?成千上万个同时的请求直接指向那个数据库分区,所有请求的目标都是检索相同的消息。这种模式重复发生,直到该分区无法回应其他请求。

Discord引入了一个位于Python/ target=_blank class=infotextkey>Python API和数据库集群之间的中间服务 — 他们称之为数据服务。这个服务大致包含每个查询一个gRPC端点,没有任何业务逻辑。对Discord来说,这个服务的重要特性就是请求合并。
正如我们之前讨论过的,每当在一个庞大的频道中有提及时,就会有大量类似的请求直接指向数据库分区。通过合并这些请求,如果多个用户请求相同的数据库行,我们可以将这些请求合并成一个选择查询,并执行该查询。

通过使用数据服务而不是直接连接到数据库,我们可以实现许多令人兴奋的功能,比如批量查询,这些功能可以显著减少数据库开销,并改善查询的平均值,特别是第99百分位数。
与许多其他公司一样,Discord使用Python作为其主要的后端语言。无论是微服务还是单体架构,后端服务通常直接连接到数据源进行查询。虽然Python确实是一种多功能语言,但在并发性方面存在一些不足。使用Python实现并发和高吞吐量的服务可能有些挑战,而性能与用C++、Rust和Golang等编译语言编写的类似服务相比,往往会较低。
在进行任何操作之前,让我们模拟一下提到的情况。假设服务总共收到了5,000个请求,其中并发数为1,000。
type Message struct {
gorm.Model
Text string
User string // some random properties that a message row may have
}
func generateRandomData(db *gorm.DB) {
for i := 0; i < 100; i++ {
msg := &messages.Message{Text: fmt.Sprintf("Message #%d", i)}
db.Save(msg)
}
}
我使用Gorm构建了一个简单的数据库模型来表示Message(消息)表,然后向表中填充了100条虚拟消息。
e := echo.New()
e.GET("/randomMessage", func(c echo.Context) error {
randomMessageID := rand.Intn(100)
var msg messages.Message
if err := db.Where("id=?", randomMessageID).First(&msg).Error; err != nil {
return err
}
return c.JSON(200, msg)
})
e.Logger.Fatal(e.Start(":1323"))
我创建了一个简单的端点来模拟对0到100之间的随机ID进行SELECT查询。现在我们可以对这个端点进行基准测试,模拟在这种情况下会发生什么。

img

如果我们有10秒的超时策略,大约有2%的请求将收不到响应。现在让我们改变代码。Golang有一个名为“single flight”的内置包。这个包提供了重复函数调用抑制机制。一般来说,你给它一个键和一个函数,而不是多次运行该函数,SingleFlight会暂时保持其他调用,直到第一次调用完成其请求并以相同的结果作出响应。
var g = singleflight.Group{}
e.GET("/randomMessage", func(c echo.Context) error {
randomMessageID := rand.Intn(100)
msg, err, _ := g.Do(fmt.Sprint(randomMessageID), func() (interface{}, error) {
var msg messages.Message
if err := db.Where("id=?", randomMessageID).First(&msg).Error; err != nil {
return nil, err
}
return &msg, nil
})
if err != nil {
return err
}
return c.JSON(200, msg)
})
func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool)
Do 执行并返回给定函数的结果,确保同一时间针对给定键只有一个执行过程。如果出现重复,重复的调用者会等待原始调用完成并接收相同的结果。返回值 shared 表示是否将 v 给了多个调用者。
现在让我们重新运行模拟并比较结果。


正如你所看到的,仅使用了一个简单的技术就将第99百分位数减少了14秒,新方法支持的每秒请求次数提高了7.6倍。
从那时起我们就注意到,通过优化数据库查询,可以大大提高应用程序的整体性能。虽然我们讨论的方法是情景性的,但Discord已经使用了一年多,对他们有很大帮助。
你应该知道,如果你使用数据服务,你将面临其他的复杂情况。例如,你可能会有多个数据服务实例,而你的Python API必须有一种机制将类似的请求发送到同一个实例。