JavaScript引擎的一个流行示例是google的V8引擎。V8引擎被用在了Chrome和Nodejs里。

浏览器中有很多几乎每个开发都调用过的API,比如 setTimeout等,但引擎不提供这些API。

JS是单线程的并发语言,这就意味着,在一个时间段内,它只能处理一项任务或执行一段代码。它有一个单一的调用栈(Single Call Stack),和堆(Heap),队列(Queue)组成的JS并发模型(Javascript Concurrentcy Model).

[可视化表示]
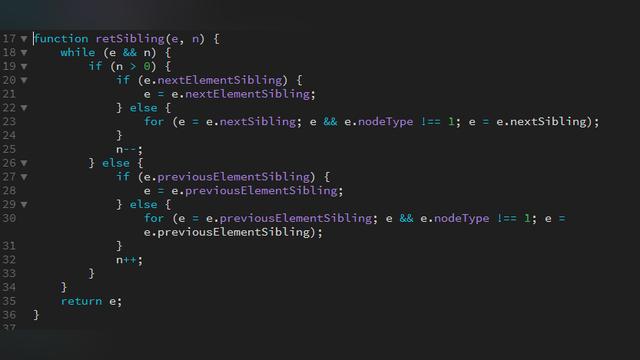
1. 调用栈(Call Stack): 在程序中,它是一个记录程序调用的数据结构。每个数据结构,也可称为栈帧。
来看一下MDN上的例子:
function foo(b) {
var a = 5;
return a * b + 10;
}
function bar(x) {
var y = 3;
return foo(x * y);
}
console.log(bar(6)); // 返回 100
当调用 bar 时,创建了第一个帧 ,帧中包含了 bar 的参数和局部变量。当 bar 调用 foo 时,第二个帧就被创建,并被压到第一个帧之上,帧中包含了 foo 的参数和局部变量。当 foo 返回时,最上层的帧就被弹出栈(剩下 bar 函数的调用帧 )。当 bar 返回的时候,栈就空了。
再加一张动态图:

我们有时会在浏览器的控制台看到长长的红色错误堆栈跟踪,它基本上指示了当前调用堆栈的状态,以及该函数在堆栈中从上到下失败的方式。
function foo(){
throw new Error("Oops!");
}
function bar(){
foo();
}
function baz() {
bar();
}
baz();
[Chrome浏览器]
有时,我们进入函数的无限循环,也会抛出错误。在Chrome中,栈里的最大深度为16,000。

2.堆(Heap):对象被分配在一个堆中,即用以表示一大块非结构化的内存区域。
3.队列(Queue):一个 JavaScript 运行时包含了一个待处理的消息队列。每一个消息都关联着一个用以处理这个消息的函数。
在事件循环期间的某个时刻,运行时从最先进入队列的消息开始处理队列中的消息。为此,这个消息会被移出队列,并作为输入参数调用与之关联的函数。正如前面所提到的,调用一个函数总是会为其创造一个新的栈帧。
函数的处理会一直进行到执行栈再次为空为止;然后事件循环将会处理队列中的下一个消息(如果还有的话)。
基本上,当我们评估 JS 代码的性能时,堆栈中的函数会使其速度慢或快,但执行d成千上万次迭代,或使用或执行超过数百万行代码的文件,速度将变慢,而且会保持堆栈占用或阻止。这样的代码或文件称为阻止脚本(Blocking script).
网络请求可能很慢,图片请求可能很慢,但幸运的是,服务器请求可以通过 AJAX(异步函数)来完成。我们假设,这些网络请求是通过同步函数进行的,那么会发生什么?网络请求发送到某些服务器,不能就是另一台在某处的计算机。现在,计算机发送回响应的速度可能会很慢。同时,如果我单击某个 CTA 按钮,或者需要执行一些其他渲染,则堆栈被阻止时不会执行任何操作。在多线程语言(如 Ruby)中,可以处理它,但在 Javascript 等单线程语言中,除非堆栈中的函数返回值,否则这是不可能的。网页将崩溃,因为浏览器不能做任何事情。如果我们想要最终用户的流畅 UI,这不是理想的选择。我们如何处理?
最简单的解决方案是使用异步回调,这意味着我们运行代码的某些部分,并给它一个回调(函数),稍后将被执行。我们都一定遇到异步回调,就像使用Node的任何AJAX请求一样,都是关于异步函数执行的。所有这些异步回调不会立即运行,将会在稍后运行,因此不能立即推送到堆栈内,不像同步函数,如它们到底去哪里,它们如何处理? $.get(),setTimeout(),setInterval(), Promises, etc. `console.log(), mathematical operations.`

从上图中,网络请求在执行过程:
1、请求函数被执行,传递一个匿名函数作为回调,这个函数在将来某个时候,当响应(response)可用时执行。
2、“Script call done!” 被立即输出到控制台。
3、在将来某时刻,响应(response)从服务端返回,执行我们的回调函数,并将其body输出到控制台。
调用方与响应的解耦使JavaScript运行时可以在等待异步操作完成并触发其回调前执行其他操作。在浏览器中,用于处理异步事件,是由C++来实现的,例如DOM事件,http请求,setTimeout等(知道了这一点之后,在Angular 2中,使用了区域,这些区域对这些API进行了猴子修补,以引起运行时更改检测,现在我可以了解它们如何实现此目的。)在浏览器中,当这些API被调用时,浏览器将创建进程处理异步的回调函数。
浏览器Web API-由浏览器创建的线程,使用C ++实现,用于处理异步事件,例如DOM事件,http请求,setTimeout等。
由于这些WebAPI本身不能将执行代码放到堆栈上,如果这样做了,它将随机出现在代码中间。由于这些WebAPI本身不能将执行代码放到堆栈上,如果这样做了,它将随机出现在代码中间。 上面讨论的消息回调队列展现了方法。 任何WebAPI在执行完,都会将回调(function)推送到此队列中。现在,事件循环(Event Loop)负责在 队列(Queue) 中执行这些回调,并在其为空时将其压入 堆栈(Stack) 。
进入队列,并不会立即被执行,只有当前Event Loop执行栈中的任务被执行完成后,才会被压入执行栈。
事件循环(Event Loop)的基本工作是同时查看堆栈(Stack)和任务队列(Queue),并在将堆栈视为空时将队列中的第一件事推入堆栈。 在处理任何其他消息之前,将完全处理每个消息或回调。
while (queue.waitForMessage()) {
queue.processNextMessage();
}
在 Web 浏览器中,每当发生事件(Event)并附加事件侦听器(Listener)时,都将添加消息(Message)。如果没有侦听器(Listener),则事件(Event)将丢失。因此,单击具有 click 事件处理程序的元素(Element)将添加一条消息(Message) - 与任何其他事件一样。此回调函数(Callback function)的调用将用作调用堆栈中的初始帧,由于 JavaScript 是单线程的,在堆栈上返回所有调用之前,将停止进一步的消息轮询和处理。后续(同步)函数调用向堆栈添加新的调用帧。
现在可以看出,有很多不同的任务队列,由上面可知,一般可分为两类,1)宏任务,2)微任务。
队列优先级
我先把结论COPY过来,有时间再写一篇文章详细说明。
小结
在JS引擎中,我们可以按性质把任务分为两类,macrotask(宏任务)和 microtask(微任务)。
浏览器JS引擎中:
macrotask(按优先级顺序排列): script(你的全部JS代码,“同步代码”), setTimeout, setInterval, setImmediate, I/O,UI rendering
microtask(按优先级顺序排列):process.nextTick,Promises(这里指浏览器原生实现的 Promise), Object.observe, MutationObserver
JS引擎首先从macrotask queue中取出第一个任务,执行完毕后,将microtask queue中的所有任务取出,按顺序全部执行;
然后再从macrotask queue(宏任务队列)中取下一个,执行完毕后,再次将microtask queue(微任务队列)中的全部取出;
循环往复,直到两个queue中的任务都取完。
所以,浏览器环境中,js执行任务的流程是这样的:
第一个事件循环,先执行script中的所有同步代码(即 macrotask 中的第一项任务)
再取出 microtask 中的全部任务执行(先清空process.nextTick队列,再清空promise.then队列)
下一个事件循环,再回到 macrotask 取其中的下一项任务
再重复2
反复执行事件循环…
NodeJS引擎中:
先执行script中的所有同步代码,过程中把所有异步任务压进它们各自的队列(假设维护有process.nextTick队列、promise.then队列、setTimeout队列、setImmediate队列等4个队列)
按照优先级(process.nextTick > promise.then > setTimeout > setImmediate),选定一个 不为空 的任务队列,按先进先出的顺序,依次执行所有任务,执行过程中新产生的异步任务继续压进各自的队列尾,直到被选定的任务队列清空。
重复2...
也就是说,NodeJS引擎中,每清空一个任务队列后,都会重新按照优先级来选择一个任务队列来清空,直到所有任务队列被清空。