DOM全称Document Object Model,即文档对象模型。是html和XML文档的编程接口,DOM将文档(HTML或XML)描绘成一个多节点构成的结构。使用JAVAScript可以改变文档的结构、样式和内容。
W3C DOM由以下三部分组成:
DOM目前有三种级别:
以下面的HTML为例:
<html>
<head>
<meta charset="UTF-8">
<title>节点树</title>
</head>
<body>
<div>测试块</div>
<a href="/about">链接</a>
</body>
</html>浏览器会将HTML文档解析成节点并组成节点树。
HTML DOM中通过不同类型节点来表示, Document是每个文档的根节点。这里的document只有一个<html>子节点,称之为文档元素(Element)。Element表示元素类型的节点,Text表示文本类型的节点。
DOM 的最小组成单位叫做节点(node)。上面的节点树中,每一段都由不同类型的节点组成。节点的类型有如下几种:
DOM1中定义了一个Node接口,JavaScript中所有节点类型都继承自Node类型,因此属性和方法都相同。
在Node类型中定义了nodeType属性来表明节点的类型,由12个常量表示。任何节点必居其一:
使用nodeType可以很容易确定节点类型,IE中没有公开Node类型的构造函数,使用Node.ELEMENT_NODE比较会导致错误。为了兼容IE,可以使用数值进行比较:
if (onenode.nodeType == Node.ELEMENT_NODE) { // 在IE中无效
console.log("The Node is an Element.");
}
// 或者
if (oneNode.nodeType == 1) { // 适用所有浏览器
console.log("The Node is an Element.");
}nodeName返回节点的标签名
var div = document.getElementByTagName('div')[0];
console.log(onenode.nodeName); // DIVnodeValue返回字符串,表示节点的文本值,可读写。
var div = document.getElementByTagName('div')[0];
console.log(onenode.nodeValue); // null文档中节点都存在着一定的关系,节点之间的关系可以使用类似人类家族关系的形式描述。如,在HTML文档中,可以把<html>看作是<body>的父元素;相对的,<body>也就是<html>的子元素;而作为<body>同级的<head>两者之间的关系为兄弟(姐妹)关系。
Node中提供了几种节点遍历的属性:parentNode、childNodes、firstNode/lastNode、
previousSibling/nextSibling、ownerDocument。
JavaScript通过Document类型表示文档。浏览器中的document对象是HTMLDocument的一个实例,表示整个HTML页面。Document节点具有以下特征:
document对象还有一些属性来表示网页的一些信息:
URL与domain属性是相互关联的。
Element类型用于表现XML或HTML元素,提供对元素标签名、子节点及特性的访问。例如<body>和<div>等。Element节点具有以下特征:
要访问元素的标签名,可以使用nodeName属性,也可以使用tagName属性;这两个属性会返回相同值。
获取<div id="divId"></div>的标签名:
var div = document.getElementById("divId");
console.log(div.tagName); // DIV
console.log(div.tagName == div.nodeName); // true所有HTML元素都由HTMLElement类型表示,不能直接通过这个类型,也是通过它的子类型来表示。HTMLElement类型直接继承自Element并添加了一些属性。每个HTML元素中的特性(例如<div id="d1" title="附加信息" lang="en" class="container">中的id、class等)会自动变成DOM对象的属性(class特性与className属性对应)。这些都可以通过div.id等获取并赋值。
一个元素中的id等是标准的特性,但也有非标准的特性不能使用div.id方式获取。那么要用什么方法来访问非特性。
DOM主要提供了几个方法用于对任何特性进行操作,分别是:
<div id="d1" title="附加信息" lang="en" class="container main" plug-add="添加的非标准的特性">以上面的HTML为例,使用这几种方法。
var div = document.getElementById('d1');
div.getAttribute('title'); // 附加信息
div.hasAttribute('plug-add'); // true
div.setAttribute('title', '修改附加信息');
div.removeAttribute('plug-add');有两类特殊的特性,虽有对应的属性名,但属性的值与getAttribute()返回的值并不相同。
第一类特性就是style,用于通过css为元素指定样式。通过getAttribute()返回的style中包含的是CSS文本,而通过属性返回的是一个对象。
第二类特性是onclick这样的事件处理。如果通过getAttribute()返回的是相应代码的字符串。而访问onclick属性返回的是JavaScript函数(如果未指定相应特性,返回的是null)。
Element类型的attributes属性返回该元素所有属性节点的一个集合,该集合是一个"动态"的NamedNodeMap对象。NamedNodeMap对象拥有下列方法。
attributes属性包含一系列节点,在节点中节点名称-nodeName 节点值-nodeValue。
var id = element.attributes.getNamedItem('id').nodeValue;
// 方括号语法
var id = element.attributes['id'].nodeValue;
// 属性名引用
var id = element.attributes.id;
// 如果知道特性名所在的下标,也可以使用下标引用,假设id特性名所在下标为0.
var id = element.attributes[0];而removeNamedItem()方法与removeAttribute()方法都是将给定名称的特性删除,唯一区别就是removeAttribute()没有返回值,removeNamedItem()返回被删除特性的Attr节点。
var oldAttr = element.attributes.removeNamedItem('id');setNamedItem()方法为Element添加一个新特性:
element.attributes.setNamedItem(newAttr);一般情况下getAttribute()、removeAttribute()和setAttribute()方法就够使用了,但想要遍历元素的特性,attributes属性倒是比较方便。下面展示如果迭代元素中每一个特性并将它们以name="value" name="value"这样的字符串格式。
function listAttributes(element) {
var pairs = new Array(),
attrName,
attrValue,
i,
len;
if (element.hasAttributes()) {
var attrs = element.attributes;
for (i = 0, len = element.attributes.length; i < len; i++) {
attrName = attrs[i].nodeName;
attrValue = attrs[i].nodeValue;
pairs.push(attrName + "="" + attrValue + """);
}
}
return pairs.join(" ");
}className属性用于操作类名,但className是一个字符串,修改后要设置整个字符串的值。
HTML5扩展了classList属性实现类名的操作。该属性返回DOMTokenList集合。定义了几个方法:
Attr类型在DOM表示元素特性。特性是位于元素attributes属性中的节点。具有下列特征:
特性节点不被认为是DOM文档树的一部分。最常使用getAttrubute()、setAttribute()和removeAttribute()方法,很少直接引用特性节点。
Attr对象有3个属性:
如果要为元素添加特性,可以使用document.createAttribute(localName)方法,创建名为localName的特性节点。例如,要为元素添加align特性,可以使用下列代码:
var attr = document.createAttribute("align");
attr.value = "left";
element.setAttributeNode(attr);
alert(element.attributes["align"].value); //"left"
alert(element.getAttributeNode("align").value); //"left"
alert(element.getAttribute("align")); //"left"文本节点由Text类型表示,包含的是可以照字面解释的纯文本内容。纯文本中可以包含转义后的HTML字符,但不能包含HTML代码。Text节点具有以下特征:
可以通过nodeValue属性或data属性访问Text节点中包含的文本,这两个属性中包含的值相同。对nodeValue的修改也会通过data反映出来,反之亦然。使用下列方法可以操作节点中的文本。
除了这些方法外,文本节点还有一个length属性,保存着节点中字符的数目。而且,nodeValue.length和data.length中也保存着同样的值。
修改文本节点的结果会立即得到反映。因此字符串会经过HTML(或XML,取决于文档类型)编码。
使用document.createTextNode()可以创建文本节点,在DOM创建中会讲述它。
注释在DOM中是通过Comment类型来表示的。Comment节点具有下列特征:
Comment类型与Text类型继承自相同的基类,因此它拥有除splitText()之外的所有字符串操作方法。与Text类型相似,也可以通过nodeValue或data属性取得注释的内容。
获取<div id="divId"><!--A comment--></div>代码中的注释:
var div = document.getElementById("divId");
var comment = div.firstChild;
console.log(comment.data); // A comment如果想创建注释节点,可以使用document.createComment(data)方法创建。
var comment = document.createComment("Create a comment node");浏览器不会识别位于</html>标签后面的注释。一定保证访问的注释节点位于<html></html>之间。
CDATASection类型只针对基于XML文档,表示的是CDATA区域。与Comment类似,CDATASection类型继承自Text类型,因此拥有除splitText()之外的所有字符串操作方法。CDATASection节点具有以下特征:
CDATA区域只会出现在XML文档中,因此多数浏览器都会把CDATA区域错误地解析为Comment或Element。以下面的代码为例:
<div id="divId"><![CDATA[This is content.]]></div>这个例子中的<div>元素应该包含一个CDATASection节点。可是,四大主流浏览器无一能够这样解析它。即使对于有效的XHTML页面,浏览器也没有正确地支持嵌入的CDATA区域。
在真正的XML文档中,可以使用
document.createCDataSection()来创建CDATA区域,只需为其传入节点的内容即可。
DocumentType类型在Web浏览器中并不常用。DocumentType包含着与文档有关的doctype有关的所有信息,它具有下列特征:
DOM 1级规定的DocumentType对象不能动态创建,只通过解析文档代码的方式来创建。支持DocumentType的浏览器会把它保存在document.doctype中。
DocumentType对象在DOM 1级中有3个属性:
浏览器中一般是HTML或XHTML类型的文档。所以entities和notations都是空列表。只有name属性有用。
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN"
"http://www.w3.org/TR/html4/strict.dtd">在这里,DocumentType中的name属性保存的就是HTML。
console.log(document.doctype.name); // HTMLDocumentFragment是文档片段,一种"轻量级"文档,可以包含和控制节点,但不像完整文档那样占用额外资源。可以将它作为"仓库"使用。具有下列特征:
使用
document.createDocumentFragment()方法创建文档片段,如下所示:
var fragment = document.createDocumentFragment();继承了Node的所有方法,用于执行针对文档的DOM操作。可以通过appendChild()或insertBefore()添加到文档中相应位置,但本身不会成为文档树的一部分。来看下面的HTML 示例代码:
<ul id="ulId"></ul>我们给<ul id=ulId></ul>添加3个列表项。可以使用文档片段来保存创建的列表项,一次性将它们添加到文档中,避免浏览器反复渲染。
var fragment = document.createDocumentFragment();
var ul = document.getElementById("myList");
var li = null;
for (var i=0; i < 3; i++){
li = document.createElement("li");
li.appendChild(document.createTextNode("Item" + (i+1)));
fragment.appendChild(li);
}
ul.appendChild(fragment);现在有一段html页面模板
...
<style>
.container {
background-color: blue;
width: 55%;
height: 55%;
}
</style>
...
<div class="container" id="divId1">Div Text One</div>
<p class="container" id="pId1">P Text One</p>
<a class="container" id="aId1">A Text One</a>
<div class="container" id="divId2">Div Text Two</div>
<form id="primary-form" action="#" method="get">
<p>UserName: <input type="text" name="input-name"></p>
<p class="container">NickName: <input type="text" name="input-name"></p>
<p>Email: <input type="text" name="input-email"></p>
<input type="submit" value="Submit">
</form>
...在该模板中,我们想要获取这些标签元素,可以使用document对象获取的几种方法:
getElementById(elementId: string): HTMLElement | null;
该方法返回匹配指定id属性的元素节点,如果不存在,则返回null。
下面通过id选择器来获取id为aId1的元素:
let div = document.getElementById("aId1");
console.log(div); // <a class="container" id="aId1">A Text One</a>注意:严格匹配,包括大小写。如果写成document.getElementById("aid1"),输出为null。
getElementsByTagName(qualifiedName: string): HTMLCollectionOf<Element>;
该方法返回匹配指定HTML标签名的元素列表。返回的是一个类似数组对象(HTMLCollection实例),可以实时反映HTML文档的变化,如果不存在,则返回null。
let inputs = document.getElementsByTagName('input');
console.log(inputs); /* HTMLCollection(4) [input, input, input, input, input-name: input, email: input]*/
这个对象可以使用length属性获取元素数量,使用数组语法或item()方法来访问HTMLCollection对象中的项。
inputs.length; // 输出p标签的数量
inputs[0].id; // 输出p标签集合中第一个元素的id特性的名称
inputs.item(0).className; // 输出p标签接种中第一个元素的class特性的名称还可以通过namedItem()方法根据元素的name特性获取集合中的项。
var nameOfInput = inputs.namedItem("input-name");也可以使用方括号语法来访问:
var nameOfInput = inputs["input-name"];要想取得文档中的所有元素,可以向getElementsByTagName()中传入"*",表示"全部"。
var allElements = document.getElementsByTagName("*");getElementsByName(elementName: string): NodeListOf<HTMLElement>;
该方法返回匹配name属性的所有元素,返回值是NodeList,如果不存在,则返回null。
var names = document.getElementsByName("input-name");
console.log(names);
注意,这个选择器在不同浏览器的效果是不同的,比如在IE和Opera浏览器下,这个方法也会返回id属性为这个值的元素。在使用的时候,应该小心使用,尽量保证name不和其它元素的id一致。
getElementsByClassName(classNames: string): HTMLCollectionOf<Element>;是HTML5中添加的方法。
该方法返回匹配class属性的所有元素,返回值是HTMLCollection,如果不存在,则返回null。
// 获取所有class中同时包含'red'和'test'的元素
var classes = document.getElementsByClassName("container");
console.log(classes);
可以接收包含一个或多个类名的字符串,传入的多个类名的先后顺序不重要。
W3C发起指定的标准,可使浏览器支持CSS查询。Selectors API的核心是两个方法:querySelector()和querySelectorAll()。兼容的浏览器中通过Document及Element节点类型的实例进行调用。
querySelector<E extends Element = Element>(selectors: string): E | null;
该方法返回匹配指定选择符的第一个HTMLElement元素,如果不存在,则返回null。传入的selectors必须是有效的CSS选择器;如果选择器不合法,会引发SYNTAX_ERR异常。
document.querySelector("#aId1"); // 取得Id为"aId1"的元素
document.querySelector("p"); // 取得p元素
document.querySelector(".container"); // 取得类为"container"的第一个元素
document.querySelector("..selector"); // 引发'SYNTAX_ERR'异常(Uncaught DOMException:Failed to execute 'querySelector on 'Document': '..selector' is not a valid selector. 意思是'..selector'不是一个有效的选择。)Document和Element都可以调用querySelector()方法,只是Document会在文档元素的范围内查找匹配的元素;Element只会在该元素后代元素的范围内查找匹配的元素。
querySelectorAll<E extends Element = Element>(selectors: string): NodeListOf<E>;
该方法返回匹配指定选择符的元素列表,返回的对象是NodeList,如果不存在,则返回空的NodeList。传入的selectors必须是有效的CSS选择器;如果选择器不合法,会引发SYNTAX_ERR异常。
// 获取id为"primary-form"中所有<p>元素
document.getElementById("primary-form").querySelectorAll("p");
// 获取类为"container"的所有元素
document.querySelectorAll(".container");
// 获取所有<form>元素中的所有<p>元素
document.querySelectorAll("form p");
Selectors API Level 2规范为Element类型新增了一个方法:
matches(selectors: string): boolean;
该方法判断当前DOM节点是否能完全匹配指定选择符,如果匹配成功,返回true;匹配失败,返回false。
var elems = document.getElementsByTagName('p');
for (var i = 0; i < elems.length; i++) {
// 获取匹配'container'类选择符的dom节点
if (elems.item(i).matches('.container')) {
console.log('The ' + elems.item(i).textContent + ' is container');
}
}
/*The P Text One is container
The NickName: is container*/注意,有些供应商会有自己实验性方法在matchesSelector()方法之前加些前缀。如果想使用这种方法,可以编写一个包装函数。
function matchesSelector(element, selector){
if (element.matches) {
// 标准方法
return element.matches(selector);
} else if (element.matchesSelector){
return element.matchesSelector(selector);
} else if (element.msMatchesSelector){ // IE 9+支持
return element.msMatchesSelector(selector);
} else if (element.mozMatchesSelector){ // Firefox 3.6+支持
return element.mozMatchesSelector(selector);
} else if (element.webkitMatchesSelector){ // Safari 5+和Chrome支持
return element.webkitMatchesSelector(selector);
} else {
throw new Error("Not supported.");
}
}
if (matchesSelector(document.body, ".container")){
//执行操作
}当有的浏览器不支持Element.matches()或Element.matchesSelector(),但支持document.querySelectorAll()方法,可以有替代方案:
if (!Element.prototype.matches) {
Element.prototype.matches =
Element.prototype.matchesSelector ||
Element.prototype.mozMatchesSelector ||
Element.prototype.msMatchesSelector ||
Element.prototype.oMatchesSelector ||
Element.prototype.webkitMatchesSelector ||
function(s) {
var matches = (this.document || this.ownerDocument).querySelectorAll(s),
i = matches.length;
while (--i >= 0 && matches.item(i) !== this) {}
return i > -1;
};
}Node节点提供了几种属性,用于访问DOM节点。
node.parentNode属性用于返回指定节点的父节点。除document外,所有节点都有父节点,document对象的父节点为null。示例如下:
document.getElementById('divId2').parentNode;node.childNodes属性用于返回指定节点的子结点的Node对象集合。示例如下:
document.getElementById('primary-form').childNodes;node.firstChild属性用于访问第一个子节点;node.lastChild属性用于访问最后一个子节点。如果要访问的节点不存在,则返回null。示例如下:
document.getElementById('primary-form').firstChild
document.getElementById('primary-form').lastChild;node.previousSibling属性用于访问之前的同级节点;node.nextSibling属性用于访问之后的同级节点。具有相同父节点为同级节点,之前或之后表示它们在文档中出现的顺序。实例如下:
document.getElementById('divId2').previousSibling;
document.getElementById('divId2').nextSibling;node.ownerDocument属性用于返回元素的根节点,即:文档对象(Document)。通过这个属性,我们能够直接访问根节点而不必层层遍历。实例如下:
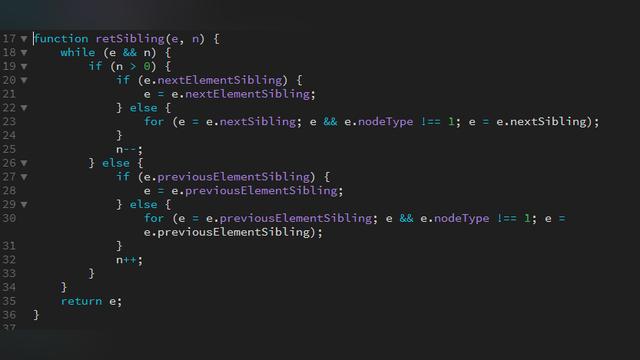
document.getElementById('divId2').ownerDocument;Element Traversal API 为DOM元素添加了以下5个属性。
支持的浏览器为DOM元素添加了这些属性,利用这些元素不必担心空白文档节点,从而可以更方便地查找DOM元素。
因为关系节点都是只读的,所以DOM提供了一些操作节点的方法。
node.appendChild(newChild)方法用于向childNodes列表的末尾添加一个节点并返回新增的节点。
var returnedNode = div.appendChild(newNode);node.insertBefore(newChild, refChild)方法会在指定的参照节点refChild之前插入新节点newChild。插入节点后,被插入的节点会变成参照节点的前一个同胞节点(previousSibling),同时被方法返回。如果refChild是null,则insertBefore()与appendChild()执行相同的操作。
var returnedNode = div.insertBefore(newNode, div.lastChild);node.replaceChild(newChild, oldChild)方法将要替换的节点oldChild移除,并将要插入的节点newChild插入并占据其位置。实例如下:
document.getElementById('divId2').replaceChild(newnode, oldnode);在使用replaceChild()插入一个节点时,该节点的所有关系指针都会从被它替换的节点复制过来。被替换的节点仍然还在文档中,但它在文档中已经没有自己的位置了。
而如果只想移除而非替换节点,可以使用node.removeChild(oldChild)方法,该方法将要移除的节点oldChild移除,并返回移除的节点。
var removedNode = node.removeChild(node.firstChild);与使用replaceChild()方法一样,通过removeChild()移除的节点仍然为文档所有,只不过在文档中已经没有了自己的位置。
上面介绍的四种方法操作的都是某个节点的子节点,要使用这几个方法必须先取得父节点。另外,并不是所有类型的节点都有子节点,如果在不支持子节点的节点上调用这些方法,将会导致错误发生。
DOM节点创建最常用的便是document.createElement()和document.createTextNode()方法。
document.createElement(tagName)方法根据指定tagName标签名创建新元素节点,返回一个HTMLElement对象。标签名在HTML文档中不区分大小写,在XML(包括XHTML)文档中区分大小写。例如,创建一个<p>元素。
var p = document.createElement('p');在使用createElement()方法创建新元素的同时,也为新元素设置了ownerDocument属性。
document.createTextNode(data: string)方法根据指定data文本创建新文本节点。作为参数的文本按照HTML或XML的格式进行编码。
var textNode = document.createTextNode("<h4>Hello </h4> world!");在创建新文本节点的同时,也会为其设置ownerDocument属性。
node.cloneNode(deep)方法用于对调用这个方法的节点创建一个完全相同的副本。deep是布尔值,设置是否执行深复制。默认为false,执行浅复制(只复制节点本身);当为true时,执行深复制(复制节点及其整个子节点树)。
var node = document.getElementById('divId2').lastChild.cloneNode(true);这些用于创建节点和复制节点的方法,创建或复制的节点并不会出现在文档中,需要通过appendChild()、insertBefore()或replaceChild()将它添加到文档中。
document.getElementById('divId2').appendChild(node);不管是createElement()、createTextNode()或者cloneNode()三种的哪种方法,创建新的节点都未被添加到文档树中。可以使用上面介绍的appendChild()、insertBefore()或replaceChild()方法将新节点添加到文档树中。
一旦将节点添加到文档树中,浏览器就会立即呈现。
一旦使用appendChild()等方法插入相邻的同胞文本节点时,会导致相邻文本节点混乱。
而在一个包含两个或多个文本节点的父元素上调用normalize()方法,就会将所有文本节点合并成一个节点。
var element = document.createElement("div");
element.className = "message";
var textNode1 = document.createTextNode("Hello, ");
element.appendChild(textNode1);
var textNode2 = document.createTextNode("Pandora!");
element.appendChild(textNode2);
document.body.appendChild(element);
console.log(element.childNodes.length); // 2
element.normalize();
console.log(element.childNodes.length); // 1
console.log(element.firstChild.nodeValue); // "Hello, Pandora!"浏览器在解析文档时永远不会创建相邻的文本节点。这种情况只会作为执行DOM操作的结果出现。
还有一个与normalize()相反的方法splitText(offset):将一个文本节点分成两个文本节点。
var element = document.createElement("div");
element.className = "message";
var textNode = document.createTextNode("Hello, Pandora!");
element.appendChild(textNode);
document.body.appendChild(element);
var newNode = element.firstChild.splitText(6);
console.log(element.firstChild.nodeValue); // "Hello,"
console.log(newNode.nodeValue); // " Pandora!"
console.log(element.childNodes.length); // 2