其实“多核”这个词已经流行很多年了,世界上第一款商用的非嵌入式多核处理器是2002年IBM推出的POWER4。当然,多核这个词汇的流行主要归功与AMD和Intel的广告,Intel与AMD的真假四核之争,以及如今的电脑芯片市场上全是多核处理器的事实。接下来,学术界的研究人员开始讨论未来成百上千核的处理器了。有一个与多核匹配的词叫片上网络�.NETworks on Chip),讲的是多核里的网络式互连结构,甚至有人预测未来将互连网集成到片上这种概念了。当然,这样的名词是很吸引眼球的,不过什么东西都得从实际出发,这篇文章也就简单地分析了为什么有多核这个事情,以及多核系统的挑战。
事先需要提及的是,一个常见误区就是多核和众核处理器的发展来源于应用和市场驱动。实际上,应用和市场希望单核处理器的寿命越来越长,而物理限制是多核以及未来众核处理器出现和发展的动力。之后我们来谈论一下,首先,为什么有多核处理器?从Intel 80286到Intel Pentium 4大概二十多年的时间都是单核处理器的天下,为什么最近几年单核处理器却销声匿迹了?是什么导致了多核时代的到来?
这里需要知道一个经验定律和三个限制,他们是多核处理器的最本质缘由。这个定理就是摩尔定律。Gordon Moore博士是Intel的创始人之一。早在他参与创建Intel之前的1965年,他就提出,在至少十年内,每个芯片上集成的晶体管数(集成度)会每两年翻一番。后来,大家把这个周期缩短到十八个月。这个指数规律的发展速度是令人难以置信的,大家都听过那个国王按几何级数赏赐大臣谷粒,从而使得国库被掏空的传说。而摩尔定律讲得就是现实中晶体管数量几何级数倍增的故事,更令人难以置信的是这个速度保持到今天已经快五十年了。人类历史上应该还没有任何技术是指数发展这么久的。题外话一句,若干年前,互联网骨干网带宽曾经这么指数了几年,曾有人将其总结为一个定律忽悠一堆人研究光纤通讯,后来发现带宽没法按照指数定律涨了,许多搞光电的人也就找不到工作了。扯远了点,整个IT产业之所以风光了这么多年,摩尔定律是本质的因素。
当无数的硅公硅婆和软件民工们将晶体管数目的增长转换为计算机等IT产品的性能时,摩尔定律也就有了两个推论,每十八个月,计算机等IT 产品的性能会翻一番;相同性能的计算机等 IT 产品,每十八个月价钱会降一半。后面这个推论很可怕的一件事情,他说,如果你IT产品像菜市场的商贩一年年复一年的卖同样的东西,那么你IT产品的价钱会指数下降。从某种意义上来说摩尔定律逼迫着所有的IT企业不断的按指数规律提高产品的性能,并且创新出新的产品。但不幸的是,这种从晶体管数转换为性能增长的过程日趋困难。
时至今日,集成度还在以摩尔定律的速度增长,但是性能的增长遇到了三个物理规律的限制。第一是功耗,第二是互连线延时,第三是设计复杂度。
功耗限制:晶体管的主要工作就以翻转提供信息计算,要让晶体管翻转就是给他们提供能量,而他们一翻转就要发热。从Intel 80286到Pentium 4的路线一直是让晶体管翻转得越来越快(约两千倍的差别),处理器频率随之不断上升,也就是意味单位时间提供给芯片的能量——功耗,会逐步上升,发热也越来越厉害。一个很明显的现象是,286不需要散热,但是Pentium IV却需要散热片加强劲的风扇。这种靠不断增加翻转速度的方式带来的最大好处是同一个程序,你什么优化也不做,买一个下一代的芯片就可以让程序跑快很多。但是与此同时,翻转速度的上升带来功耗的急剧增长,所散热超过了风扇散热的热预算。不幸地是,散热的能力却不能够同步增长,这限制了处理器所发热的总功耗,从而使得传统地提高处理器频率的老法子不再具有可扩展性。单核处理器的性能发展走到了尽头。那摩尔定律提供的多余的处理器怎么办呢?最简单的办法就是用来增加单片集成处理器核的数量而不是性能。
互联线延迟:芯片上除了晶体管就是互连线。它的主要工作是把一个晶体管干活儿的结果给另一个晶体管,是个车间搬运工的角色。曾几何时,晶体管是很慢的,所以没人在乎这种搬运工带来的任何延时影响。但是随着晶体管越来越小,越来越快,互连线的延迟并不随之变块,这就成了问题了。以前晶体管每翻转一次的时间互连线能够把数据从芯片的一头送到另一头,而如今这种对角线传输得花好几个晶体管翻转的时间。摩尔定律说晶体管集成度越来越高,但是互连线却相对的越来越慢了。这带来的最大问题是干一件事情需要花的步骤更多了,打个比方就是工厂里的流水线级数越来越多,很多步骤都花在把东西从一个车间搬到另一个车间上。在Pentium IV的时候,干一件事情(执行一条指令)要花20级流水线。流水线级数长不是什么好事,因为一旦当流水线级前面处理的东西出了问题,后面正在处理的那些东西就得重头来做。当年AMD Athon之所有能够在与Intel Pentium 4争夺中占领一席之地,就是因为虽然AMD的晶体管翻得慢,但流水线级数少,因此那种重头来做的机会和代价都小,因此性能还很高。克服互联线延迟增加的最好办法就是把一个大厂房分成很多个小厂房,事情都在一个小厂房里解决,这样运输的距离就变短了。换句话说,使用较小的核组成一个多核的芯片,而不是以往的单核芯片。
总结一下,多核系统的出现是摩尔定律与物理规律限制相互作用的结果,三个主要的限制是:功耗、互连、设计复杂度。一个处理器上的晶体管数越来越多,但是他们却因为功耗和互连线的限制并不能直接提供很高的性能,那么怎么办呢?一个最简单的办法就是用在一个处理器中集成多个简单的处理器核。这样既把多出来的晶体管用上了,而每个处理器核就像前一代的处理器一样简单,因此不必提高他们的翻转速度,各个处理器核只需要自己交换数据,因此没有很长的连线延迟。这也就是Intel放弃Pentium IV采用Core 2结构的缘由,也是本篇文章最本质的原理。
从单核到多核乃至未来众核的变化并不是芯片设计公司根据客户需求,市场趋势做出的主动选择,而是在物理规律限制不得已的情况下被逼走上的道路。这意味着以前那种处理器频率越来越高的时代已经一去不复返了。在那个已经过去的黄金时代,程序员不需要怎么优化程序,因为优化程序所花的功夫和时间还不一定值得去市场上买一个新款处理器。这也就使得Microsoft敢于做越来越慢的软件。他不怕因为软件太慢卖不出去,因为处理器的翻转速度的增长会使得他本来很慢的软件,不久就会快得可以接受。但是这个故事已经结束了,现在的新款处理器跑老程序并不会快到哪里去,而当你买了新处理器还得对老程序作进一步的优化才能利用上新增的晶体管。这可能也就是微软的Vista按照老路子设计,但卖得没那么好的原因,也带来了微软裁员5000人,但是linux却还是比较红火的结果。下面这个图是09年初Redhat Linux和windows的股票走势,可以比较明显的看出来,当处理器速度不再翻倍的时候,当人们没钱总是换硬件的时候,微软的表现就不是那么好了。因为Windows Vista是微软沿用了以前处理器发展规律设计的操作系统,因此并不叫座。微软公司不得不花大力气重写了他们的内核代码,推出了Windows 7来收拾Vista的残局。

多核虽然说着容易,做起来也不难,但是难得却不在多核本身上,下面的内容简单地揭开了多核设计貌似困难实则简单地面纱,同时也指出多核之难不在核上,而在互连与编程两大挑战。
多核处理器的发展其实很大程度上是一个学术界最早提出但是由工业界引领的题目,从本质上来说设计一个多核处理器本身没有什么有深度的挑战,难点其实是互连和编程的问题。不过在我们深入了解这两个问题前还是先回顾一下多核处理器的发展之路,目的是看看人们怎么从单核走到多核的。
多核的点子最早学术界提出的。典型的有四个:斯坦福的Hydra(1996),斯坦福的Imagine (2000),MIT的RAW(2002),以及UT奥斯丁的TRIPS(2003)。在这个问题上,是不得不佩服美国的创造力,要知道直到在2000年左右,所有的人都还在为处理器频率按照摩尔定律翻翻而狂热,美国的顶尖研究员就早已看到了这条路的尽头并指出未来处理器的发展之路。
如果从学术界多核处理器的发展上学到一点最关键的内容的话,那就是:做一个多核的处理器不是一件有理论困难的事情。曾有人据此预测说多核设计给了学术界一次超越工业界的机会,就像当年一个随便的学生project做出来的RISC处理器就能胜过工业界的CISC处理器一样。但是就目前看来这件事情并没有如期发生。真正的难点并不在处理器设计上,当工业界用各自不同的方式实现多核处理器后,一个重要经验就是:真正的难点在提供一个多核平台上的编程环境。
在介绍多核处理器的设计的时候我们将学术和工业界的研究情况结合在一起。多核处理器架构的学术深度是有限的,但是工业界的实现却是多种多样的,SUN、IBM、Intel、AMD、甚至ARM都相继设计并推出了了自己的多核处理器。面对不同的客户市场,不同的公司推出的不同多核处理器具有截然不同的特点。
多核处理器的设计依照大致可以分为三类:总线或者交换开关互连的或和设计,流处理器和图形处理器,以及网络互连的处理器:
以总线或交换开关为基本互连架构的多核设计
最初的多核处理器集成的处理器核数量较小,典型的特点就是互连方式是以总线和交换开关为主,而每个核结构相似功能较为强大。这种设计也该可以看作传统一个主板上多处理器结构在片上的集成,主要的创新来源于摩尔定律指导下半导体技术进步带来的集成度提高,体系结构的创新并不明显。这种结构的始祖(当然也是片上多核的始祖)是Hydra。
斯坦福的Hydra处理器是最早提出的片上多核处理器。Hydra发明后成立了一家公司,然后这个公司被SUN公司购买(后来SUN又被Oracle买了,不过那是后话),Hydra也就成为了现在SUN主流处理器Niagara的原型。不仅如此,现在Intel的双核、四核处理器也是采用了和Hydra类似的结构。Hydra的出发点也就是看到了多发射超标量处理器架构的末日,然后将多个简单的处理器核集成在了一个芯片上,互连方式还是最简单的总线互连,每个处理器通过总线广播的方式发送信息,也通过总线侦听来接受其他处理器。这种方法设计简单、有效,可以重用复杂的处理器设计,并且借用版级总线设计的协议,是一种多核发展初级阶段的重要一步。下图就是Hydra的示意图,可以看到这其实就是一个集成在片上的总线带动的多处理器。这种结构的发展也有不同的阶段和变体:最初只有处理器核、总线和缓存集成在片上;后来存储和I/O控制器也集成了进到片上来;图中的总线之下的L2缓存有时候也会被放在总线与处理器之间;片上与片外的连接也不一定要是处理器与存储器的接口,而可以成为两个或多个多核处理器的接口。 Hydra引领的以总线为主的片上多核设计方案也成为了工业界第一代双核甚至四核处理器设计的雏形。
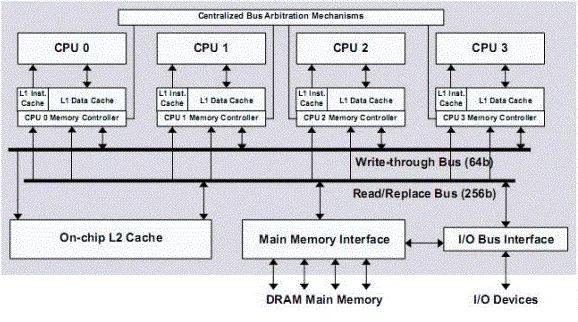
最早的双核处理器以及Intel的第一代四核处理器都是这种设计。总线可以替换为交换开关,来实现类似的功能。如下图所示的是SUN在2007年推出的八核Niagara 2,其互连结构就是交换开关。
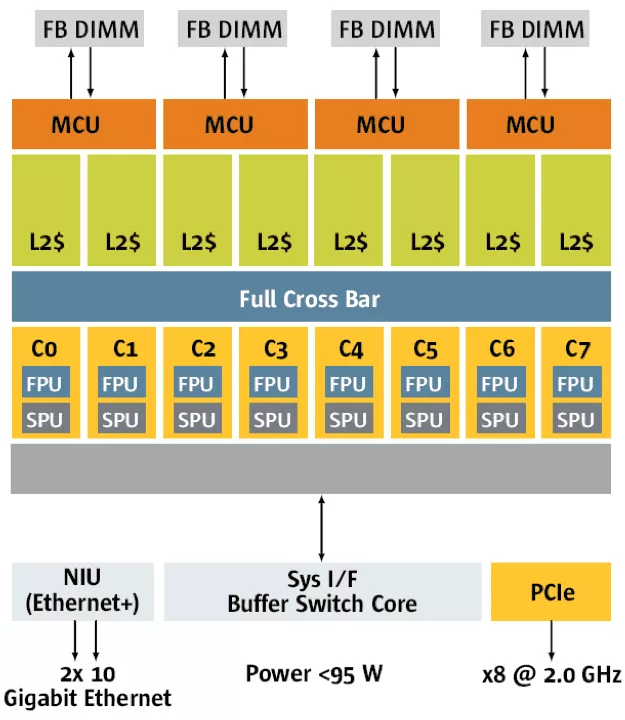
这种结构有以下这些特点:
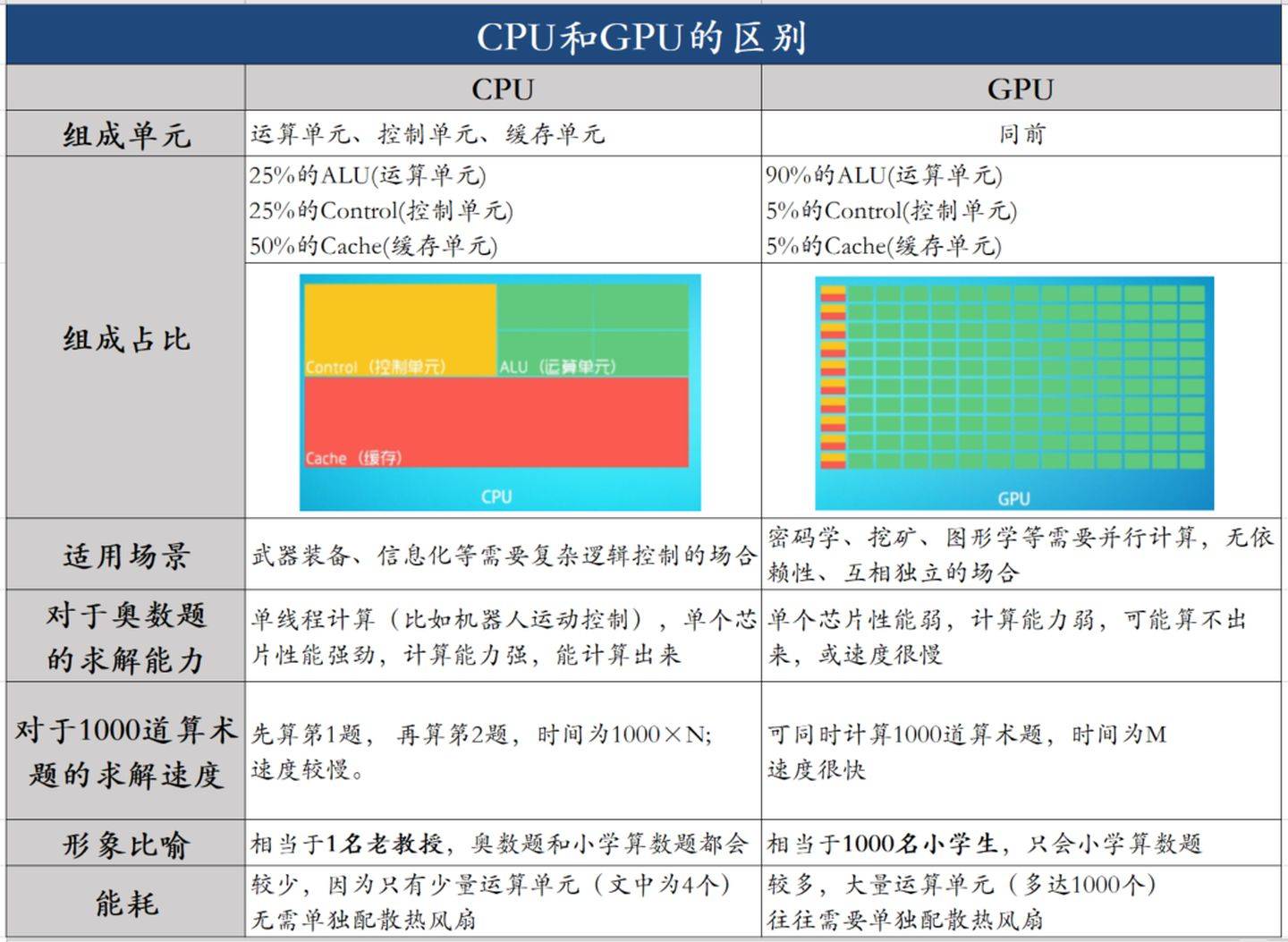
• 从存储器读写的角度来讲这种设计统称为UMA(Uniform Memory Access)。每个处理器核访问存储的路径都是一样的,总线(或者交换开关)被不同的处理器核交替使用从而达到访问共享存储的目的。这种存储访问结构自然地支持了内存空间在各个处理器核之间共享已经基于总线侦听的缓存一致性协议。
• 各个处理器核类似于传统的单核处理器,具有较为强大的计算功能,只是作了一些裁剪来优化功耗等要素。也就是说,就算单线程应用程序没有任何改变,也能在新的多核处理器上运行,性能有可能有所提高。
• 从编程上来讲类似于传统的多处理器编程,再加上内存空间共享,并控制了多线程编程的复杂度。比如说,像Linux之类的操作系统很早就支持多处理器,可以无缝地在多核处理器上运行,并从容地调配多个应用程序进程。其实,最早多核处理器的性能提升大部分就来自于应用程序能够各自独享一个核所带来的独占优势
这种结构的明显劣势来自于总线或者交换开关成为系统瓶颈,这个瓶颈体现在系统性能和功耗两个方面:从系统性能上来讲这种体系结构的核心:总线或者交换开关仍旧依赖全局金属互联线,其性能并不能随着半导体技术进步而提高。这种全局性地互连要求所有的通信都先汇聚到同一个地方然后又再传播出去,其效率之低也是可想而知的。从延迟上讲,电信号需要给长达整个芯片边长的金属线充电,其电阻电容很大,充电时间很长,因此信号延迟很大;从吞吐率上来讲,所有的信号传输都要通过这个总线或者交换开关,其带宽是无法适应处理器核数量的增长的。同样的坏消息来自于功耗。无论是连接多个核的总线还是四通八达的交换开关,其功耗都不是可以扩展的。上述的不可扩展性决定了,基于片上总线或者交换开关的体系结构终究不能支持片上多核随着摩尔定律而扩展到片上众核,人们不得不放弃这种简单的结构而选择流处理器或者片上网络等较为复杂的体系结构。
Hydra的故事虽然简单,但是却发生在1996,可以说在那个年代是极其具有前瞻性的。一句题外话,在那个年代,ISCA(International Symposium on Computer Architecture,计算机体系结构最牛的学术会议 )还基本上是Cache Architecture的天下,所有的体系结构研究者还在考虑怎么样提高单核的性能。反观今日,当世界上所有人都在讨论多核的时候,我们是不是应该前瞻性地考虑一下下一个热点是什么呢?
流处理器以及GPGPU(通用图形处理器)
流处理器以及GPGPU代表的路径是完全绕开了传统处理器设计而针对新的应用借鉴其他专用处理器(GPU)而展开的全新设计。具体地讲,Hydra面对的应用还是超标量处理器所面对的传统应用,大量的程序循环和跳转,不规则的内存地址访问。而随着计算技术不断升入到人们的生活当中,另一种计算模式异军凸显,这就是大规模的数据并行计算模式。比较通俗一点的应用就是图像和视频的处理以及综合,比如视频的编解码,动画的合成等。在数字通讯的年代这种计算越发重要,像无线基站或者手机上各种通讯协议栈的处理。在单核的年代,进行这种计算的处理器叫DSP(Digital Signal Processor),以有别于CPU这种擅长控制和跳转的处理器。DSP的结构与普通的CPU的超标量结构不同,大量采用了SIMD(Single Instruction Multiple Data)或者VLIW(Very Long Instruction word)的结构,以实现在同一个处理器流程通路下的数据乃至指令的并行。那么就像Hydra是超标量CPU在多核时代的领头羊一样,斯坦福这个信息工业的圣地也诞生了DSP在多核时代的领头羊Imagine。
这里可能需要叉开话题来讲一下并行的基本分类了。一般地讲,并行处理有三个分类:数据并行、指令并行和线程并行。线程是一串串行执行的指令,每条指令操作一个或多个数据。在此基础上,实现并行的方式有三种:
一种是多个这样的串行指令序列同时执行,就是Hydra为代表的线程并行模式;
第二种数据并行是同一条指令应用在并行的数据上。比如本来是一条加法指令计算C=A+B,同时将加法应用到一组A和一组B上得到一组C上就是数据并行。SIMD和即将讲到的Imagine都利用了这种并行;
第三种是指令并行,也就是说在同一时间发射多条指令,同时计算不同数据多个不同运算,VLIW就是这样一种并行方式。但是由于实现VLIW的编译器难度太高,使得直接实现大规模可扩展的指令并行比较困难。
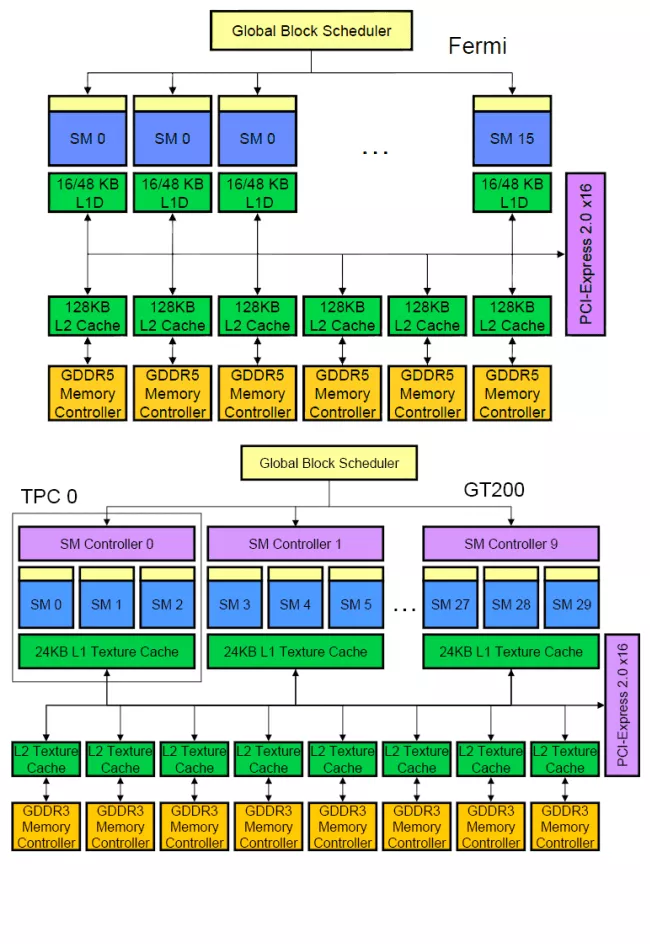
回到多核处理器的学术路径上来。Imagine是斯坦福的一个数据并行的多核处理器。Imagine有8个ALU单元被同一个控制器所控制,同时对大量的并行数据进行同样的操作。这种处理器的模式后来被称为流处理器。后面我们讲到的Nvidia的Fermi就是这种数据并行流处理器的一种实现实例。下面这个图即是Imagine的结构框图,可以看到它是多么像一个大型的SIMD单元啊。实际上它也即是48个ALU单元分成了8个SIMD簇。但是不可否认的是,就这样一个看似简单的设计提供了极高的数据并行度,使得它在处理一系列与多媒体有关的应用上得心应手,发挥了更多晶体管所带来的性能优势。
接下来我们来GPU处理器结构:Nvida的Fermi以及前一代的GT200,然后我们就可以发现他们和Imagine惊人的相似之处:每一个处理器核是一个简单的ALU阵列。当然,在Nvidia的名词里,处理器核叫Streaming Multiprocessor(SM),每个Fermi的SM里有32个32位ALU、32个单精度的浮点运算单元还有一些特殊运算单元;每个GT200的SM里的运算单元少地多。SM相当于Imagine里地ALU Cluster,能够执行SIMD的操作,但是绝对和Intel以及AMD里面的处理器核相去甚远。通用处理器中的每个核里有庞大的指令池和寄存器堆,执行繁杂的指令预取,分支预测,条件跳转等操作,虽然计算单元不如SM多,但是计算精度较高(64位)。换句话说,如果你的程序没有那么宽的单指令多数据并行,那么不要指望SM比传统处理器核快。
片上存储是为流数据简化(也算是优化)过的。在传统的GT200中,这种存储就叫texture cache,在Imagine里叫Stream memory。在图形图像中,大部分的操作是流水线化的,所以这种cache不需要支持不同SM之间存储共享(即使需要,必需程序员显式指定,而不是处理器代劳),部分的缓存甚至是私有的,就连地址空间都是独立的。这对于流处理器来说,没有任何问题。我们把流处理想象成一个巨大的SIMD,不同的data之间没有任何共享,texture cache就够用了。但是一旦有了分支、线程并行、数据交换、信号锁,这种cache就会让程序员头痛,于是Fermi做了一些优化,使得片上缓存至少在地址上是共享了,但是并不完全支持缓存一致性。只有当程序员显示使用同步信号量,存储的顺序核一致性才是可以保证的。
这里需要澄清一个很明显的误区就是在GPU上编程能够成百倍地提高CPU的性能,这个观点在Nvidia推出CUDA的时候被狠狠吹捧了一番,不过后来大家发现GPGPU的能力其实非常有限:
如果结合上面探讨的两种类型的多核处理器设计,有一个很明显的问题是,到底用少数几个强大的单核,还是很多简单的单核最能优化处理器设计呢?问题的困境是:如果每个核很强大,其能提供的总指令吞吐率与其功耗或面积成本呈亚线性关系,投入产出效率较低,但是如果每个核很简单,那么单线程的性能很低,而不幸的是每个应用程序总是有一部分没法并行化,这部分将最终决定整个程序的性能。
这篇文章给了一个很有意思的讨论。问题的一个直白答案是取决于程序的并行性:一个程序到底有多大部分是必需串行执行的?如果这个部分很大,那么少数几个强大的单核是比较理想的方案,而如果这个部分很小,那么倾向于使用更多的较简单的核。最为理想的方案是一个异构多核的设计,这样串行的部分能在一个强大的单核上加速,而可以并行的部分则通过很多很小的核来提速。这个思想的一个很明显体现就是Intel的Sandy Bridge处理器,这个处理器没有遵循以往不断增加核数量的规律,其设计中里既有强大的传统处理器核又有类似GPU的处理器,期望做到异构多核来实现性能的提升,下图就是Sandy Bridge的系统结构:
无论是总线和交换开关的设计,还是流处理器,就没法从本质上改变多核乃至众核处理器设计上的不可扩展性。改变这种传统的互连,人们提出了使用片上网络的办法,使得未来众多的处理器核通过分布式的通讯方式相互沟通,从而避免了集中的互连设计带来的系统性能瓶颈以及较大的功耗开销。不过当片上集成核的数量不断增加时,如何把这个功能组织起来,并不是一个简单的事情,无论是学术界还是工业界都做了许多的尝试,从目前开来实际结果都不太理想。
第一个真正采用网络来连接片上很多核的是2002年MIT一组研究人员提出来的RAW众核处理器。MIT的RAW处理器第一次应用了片上网络的概念。这个设计后来成立了一家公司叫Tilera。RAW的出发点在于看到传统单核处理器中的瓶颈在于操作数网络(scalar operand network)。这个网络把各个ALU中计算出来的数值中间结果存储到寄存器堆,又把寄存器堆里的数给ALU就行操作。随着金属互联线延迟的增加,这个移动操作数回路成为系统瓶颈,成为了导致ALU中晶体管性能提高并不能外化为处理器性能的绊脚石。
解决这个问题的办法是用操作数网络把计算单元(ALU)组织起来,而不是传统意义上的操作数网络为ALU服务。每个操作数通过网络进入到一组ALU里,经过漫长流水线的处理和计算输出出来到网络中,然后送到临近的另一组ALU里,而不必绕回去。这样把每组ALU看成一个“核”,这样就构成了片上网络。下图就是RAW中每个处理器核的结构:
图中可以看到,与其他商业多核处理器不同的是,RAW的片上网络深入到了处理器流水线的内部。接着,既然ALU可以编程,那么操作数网络也可以编程,这样就达成了一个软件可以控制的计算、通信众核系统。当然其网络设计就是一个普通的Mesh网格网络,如下图所示,没啥特殊的。不过这个Mesh其实是由若干个不同功能的网络联合而成,各自负责操作数、片上存储以及I/O等片上通讯的需求。
RAW的难点在于对于应用程序需要就行网络和计算的双重优化,否则程序运行的效率较低。这使得编译器中指令调度不光考虑运算单元的成本,还有通讯的成本,搜索空间和复杂度大大提高。
接下来介绍IBM的Cell处理器,算是工业界探索异构多核设计的先河吧。Cell的来头还是蛮大的,是IBM,SONY和Toshiba三家大公司为未来的消费电子设计的核心计算引擎。其最典型的应用就是索尼的PS3。Cell的设计采用了环形的片上互连、异构的片上多核、以及片上系统的集成,然后在IBM的90纳米、65纳米和45纳米工艺条件下做了实现,应该说是代表了当时业界的最先进水平。不过不幸的是IBM在2009年年底的时候停止了对Cell的进一步研发,而基于Cell的索尼PS3销售上没有敌过任天堂的Wii(截止2010年9月低,Wii在全世界销售了七千六百万台,而PS3仅有四千两百万台)。这背后的原因在于什么呢?
首先我们来看IBM Cell处理器的设计,其中包含了一个Power processing element(PPE)作为主处理器(其性能相当于64位的Power PC),加上八个Synergistic Processing Elements (SPE)作为协处理器(其性能相当于普通的RISC处理器和一个128位的SIMD),这些处理单元通过一个环形网络就行互连,达到超过200GB每秒的带宽。光从这些数据上来讲,这个多核处理器符合前面讲述的异构并行原理,并且技术也不差。最为不幸的是这个处理器太难编程了。每个协处理器有一个私有的局部存储器(256KB)大小,这个存储器几乎需要程序员来手动调度,它既没有类似于缓存的自动预取,又不与PPE的存储单元共享地址空间。如果要协调好PPE与SPE的工作,除非程序的工作模式是固定的。这样的结果就是处理器理论性能很高,但是实际程序优化起来并不容易,很多程序仅仅能够使用一个类似于PowerPC的PPE。没有多少廉价程序员能够理解如此繁杂的体系结构,愿意在上面做开发。这可能就是Cell最终被IBM停止开发的原因吧。
Intel是最能理解编程的简易性对于一个处理器生命的至关重要性,在当年以x86为代表的CISC和以MIPS、SPARC为代表RISC结构出现争端的时候,Intel为了保证程序的兼容性,保持了x86指令向下兼容。尽管牺牲了一定性能却赢得了软件开发者和客户的认可,而随着半导体技术的推进这些性能牺牲被历史所抹平。针对RAW和Cell都面临的问题,Intel推出了一个保持存储一致性和x86指令集的多核设计:Larabee,作为未来GPGPU时代众核编程的抬头兵。不过这个设计从2008年透出风声到2009年底就被宣布第一代产品难产了。
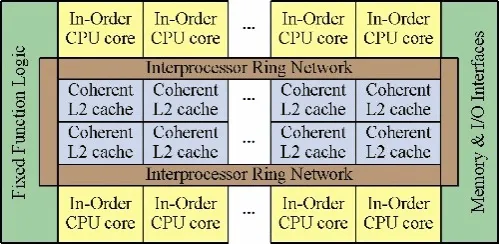
Larabee的设计野心就是编程的容易性,16(甚至32)个x86的处理器核通过一个环形的片上网络连接在一起,分布式的的片上缓存保持完全的一致性,没有任何特殊的专用硬件单元来增加编程的难度。大部分的优化可以通过软件来完成。完成这样一个设计难度在于两个方面:
在摩尔定律的作用下,任何的耽搁都会导致产品的流产,Larabee开发的艰巨性决定了其性能跟不上摩尔定律,从而其第一代产品被迫下线。
在本文的结尾总结一下所探讨的这些多核乃至众核处理器,可以看到其中的挑战其实并不是在处理器设计本身,而在互连与编程这个两个方面。一个未来会成功的众核处理器提供给开发者一个向下兼容的简单编程模型,并且尽量将互连的影响尽可能的化解。这个目标并不容易实现,很有可能人们不得不最终放弃传统的编程模型,而直接面对众核处理器的互连和编程挑战。本文的续篇中,我们试图分别探讨一下,在互连和编程上研究者们做出的努力。