Pine 发自 凹非寺
量子位 | 公众号 QbitAI
当你拍照片时,“模特不好好配合”怎么办?
没事!现在只用 一句话就能后期P图了,还是能改变动作、表情的那种!
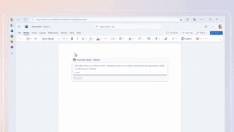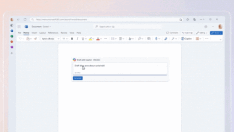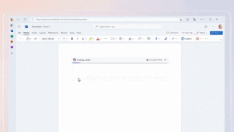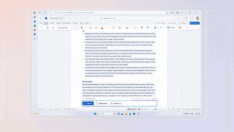
比如说你能轻松让鸟张开翅膀 (输入“张开翅膀的鸟”即可):

又或者说,想要让一只站立的狗蹲下:

看起来还真不赖!而这个新的“P图”方法呢,名叫 Imagic,是基于爆火的扩散模型 (Diffusion Model)来实现的。
是的,又是扩散模型,它的能耐想必也不用多介绍了吧 (那看那铺天盖地和它相关的论文就能佐证)。
那在扩散模型加持下的Imagic到底有何厉害之处,话不多说,一起来看看吧!
多达6种功能
据不完全统计,Imagic的功能就有 6种。
改变姿势、变换构图、切换滤镜、多个对象编辑、添加对象、更改颜色……
先来看看这个P图神器 改变姿势的效果,比如说输入一条站立的狗,通过变换提示文字,得到的效果是酱紫的~
或者说输入一个随意站立的人,输入口令,他就“乖乖听话,任你摆布” (手动狗头)了,甚至还能凭空出现一个水杯。
还没看够?那再来康康Imagic其他功能:改变颜色,或者增加对象,也可以多种功能同时使用。

总的来说,Imagic的厉害之处太多,这里就不一一详细展开了,效果可以看下图。

除了这么多功能之外,Imagic还有另外一个比较人性化的点,就是当你告诉它要如何“P图”后,它会随机生成几个不同的选项供你选择。

其实这种在真实图像上编辑的模型Imagic不是第一个,在此之前就已经有很多个类似的模型。
这时就会有网友问了,“Imagic有什么厉害的点呢?”
话不多说,直接上效果对比。
这里选取了比较常见的基于真实图像编辑的两个模型:SDEdit、Text2LIVE与Imagic作对比。

结果很显然,Imagic完成“P图指令”的效果很好,在细节上也丝毫不逊色其他模型。
(确实妙啊)
那Imagic是如何“击败”SDEdit、Text2LIVE,实现这样的效果呢?
是怎样实现的
千言万语汇成四个字: 扩散模型,在论文的标题上它都赫然在列。
具体到Imagic中,扩散模型的作用是如何发挥出来的,来看看详细的“P图”过程。
整体来说分为三大步。
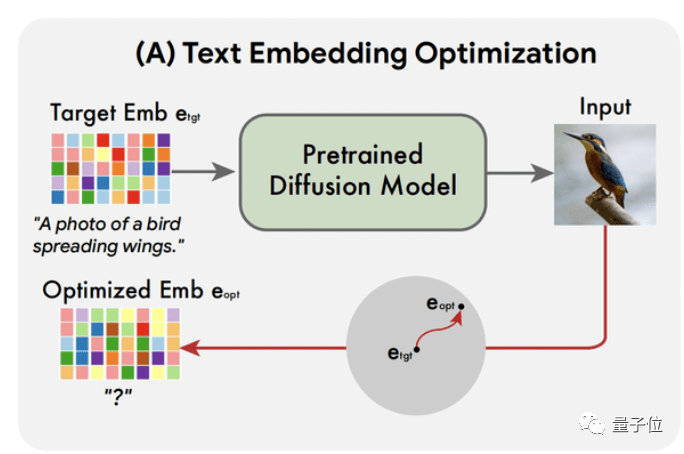
第一步是优化文本嵌入层。
具体来说,先给定输入的图像和目标文本,然后对目标文本进行编码,得到初始的嵌入层。
然后不断调整初始嵌入层,让其能够通过预先训练的扩散模型很好地重建输入图像。
这样一来,最终便会得到优化后的嵌入层 (能够很好地重建输入图像)。
第二步是对扩散模型进行微调,这时就要用到上一步已经优化之后的嵌入层,让嵌入层经过模型后重建输入图像。
在重建的过程,需要不断更改模型中损失函数的参数,以让模型适应优化后的输入层,直到能够很好地重建输入图像时为止,这样一来便得到了微调之后的模型。
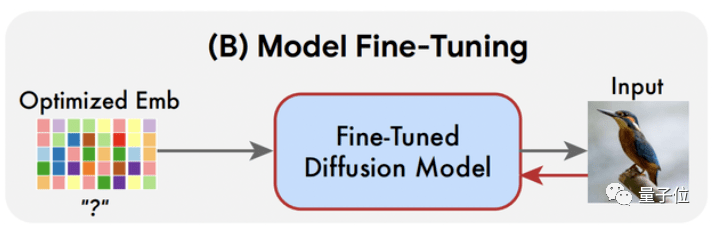
第三步就要开始正式P图了。
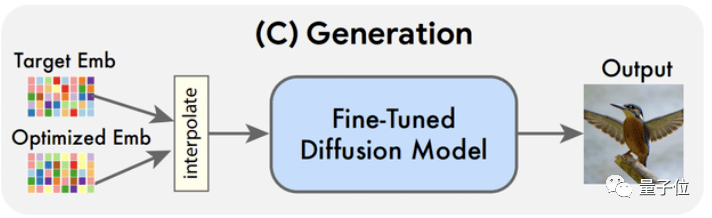
值得一提的是,这一步除了输入初始的目标嵌入层 (tgt)外,还会插入优化好的嵌入层 (opt),它们的关系如下图。
通过变换参数,实际的效果如下图。

如果你想更加详细地了解Imagic,可以戳文末链接阅读论文原文。
研究团队
Imagic的六位作者均来自google Research,论文有两位第一作者:Bahjat Kawar和Shiran Zada,均来自以色列。
值得一提的是,Bahjat Kawar还是一位以色列理工学院在读博士,他是在Google Research实习期间完成了这项研究。

而Shiran Zada今年5月刚加入Google Research,目前是计算机视觉研究员。
他曾在微软担任软件工程师以及技术主管的职务,主要负责网络安全相关的项目开发。

— 完—