
一. 时间序列基础知识
社会经济现象总是随着时间的推移而变迁,呈现动态性。一个或一组变量x(t)进行观测,将在一系列时刻t1、t2、...、tn得到离散数字组成的序列集合,称之为时间序列。通过时间序列算法,我们对事物进行动态的研究。
时间序列表示按时间先后顺序排列的数列,通常X轴为时间要素,Y轴为数据要素,比如1986-2000年的人均GDP为y1、y2、...、yn,再如下图所示太阳黑子运动规律。
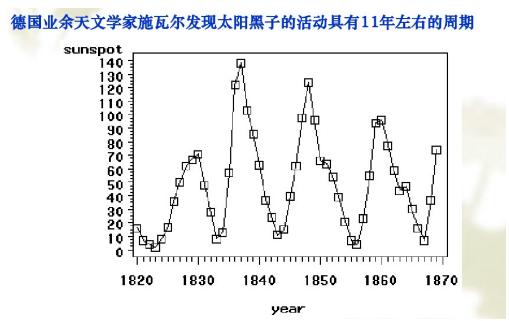
指标通常包括时期指标(年度、月度)和时点指标(时刻)。时间序列分为以下三类:
1.随机性时间序列:各指标变动受随机因素影响
2.平稳时间序列:基本稳定在某个水平附近波动
3.非平稳时间序列:存在某种规律性变动,比如趋势性、季节性
时间序列常用的特征统计量如下所示:

二. 金融时间序列-Pandas库
该部分是作者学习《Python金融大数据分析》书籍第6章的内容,仅供大家学习:
金融学中最重要的数据类型之一是金融时间序列,以日期时间作为索引的数据,例如股票、GDP、汇率等。Python处理时间序列主要使用Pandas库,其DataFrame和Series等基本类灵感来源于R语言。Pandas库允许从Web上读取数据,比如雅虎财经、谷歌财经等,也可以读取csv文件(逗号分割)。下面详细介绍Pandas库的用法:
1.DataFrame类
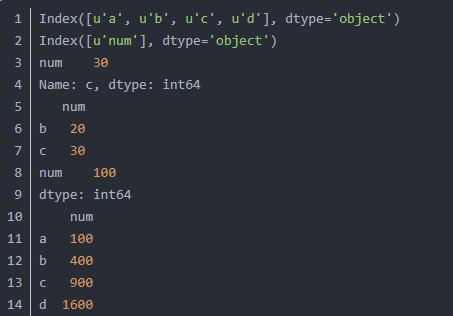
首先我们通过DataFrame定义数据,包括数据、标签和索引三部分,其中数据包括列表、元组、字典、ndarray等类型,索引包括数值、字符串和时间等。示例代码如下:

输出结果如下所示,包括输出索引、标签值,获取“c”对应数值等,通过df.sum()对数据进行求和、df.mean()求平均值、df.Apply(lambda x:x**2)实现数值平方计算。
DataFrame对象总体上比较方便、高效,相比ndarray对象更专业化。下面代码是进维度扩增,增加了一个float类型。

输出结果如下所示:

接下来再增加一个维度,通过索引进行对应。代码如下:
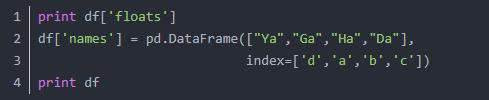
输出结果如下:

2.DatetimeIndex类
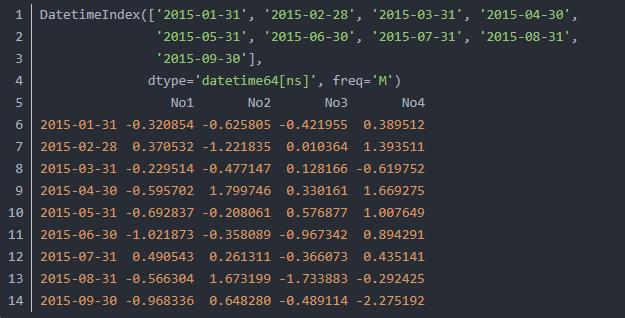
接下来我们讲解DatetimeIndex类,通过它定义时间。首先调用numpy.random函数 生成一个9*4的标准正态分布伪随机数,然后定义列标签,代码如下:

输出结果如下,如果需要进行访问则调用df['No2'][3]实现。

为高效处理金融事件序列数据,必须很好地处理时间索引,接下来通过date_range()函数对9行数据对应上时间,从2015-1-1开始,代码如下:
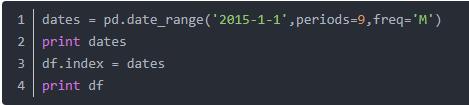
输出结果如下所示,可以看到每行数据对应一个年份,其中freq参数表示频率参数,常见的值包括:
B-交易日 D-日 W-每周 M-每月底 MS-月初 BM-每月最后一个交易日 A-每年底 H-每小时
3.绘图操作接着我们进行绘图操作,Pandas提供了Matplotlib的一个封装器,专门为Dataframe对象设计。代码如下:

主要调用plot方法,参数包括x、y、title、grid(表格线)、ax、legend、kind(图形类型,kde/line/bar/barh)、logx、yticks(刻度)、xlim(界限)、rot(旋转度)等,绘制图形如下所示:

4.Series类从DataFrame对象中选择一列时,则得到一个Series对象,代码如下:
输出结果如下:
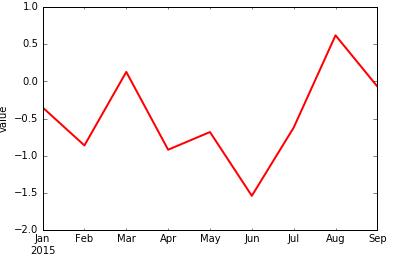
仅仅获取了"No1"数据并绘制如下图所示图形:
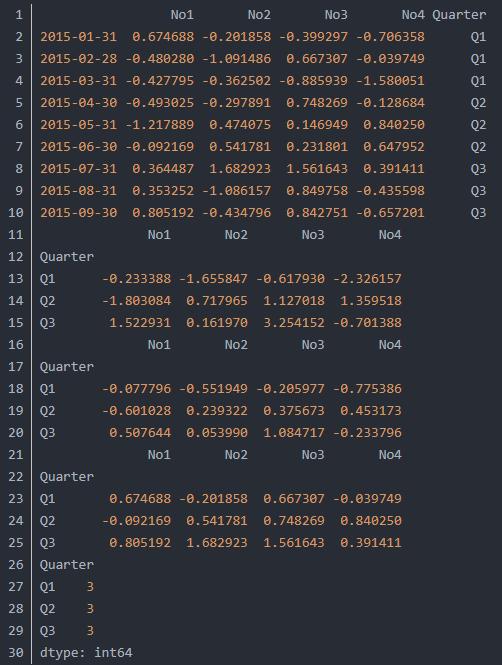
5.Groupby操作Pandas具有灵活分组功能,工作方式类似于SQL中分组和Excel透视表,为进行分组,我们添加一组索引对应季度表,代码如下:

输出结果如下所示:
三. 时间序列算法-ARIMA
作者本来想通过下面代码导入雅虎财经数据,但是没有成功,最终选择自定义数据进行ARIMA算法实验。
时间序列是通过曲线拟合和参数估计来建立 数学模型的理论方法,基本步骤如下:
(1).获取被观测系统时间序列数据;
(2).对数据绘图观测是否为平稳时间序列、非平稳d阶差分;
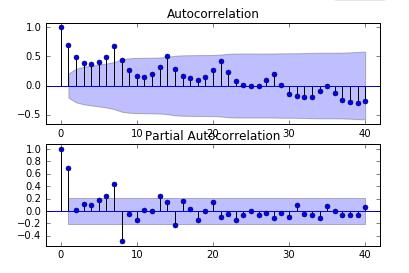
(3).得平稳时间序列,求其自相关系数ACF和偏自相关系数PACF,通过自相关和偏相关图分析,得到最佳阶层p和结束q;
(4).由d、q、p得到ARIMA模型,然后进行检验。
1.获取数据导入库
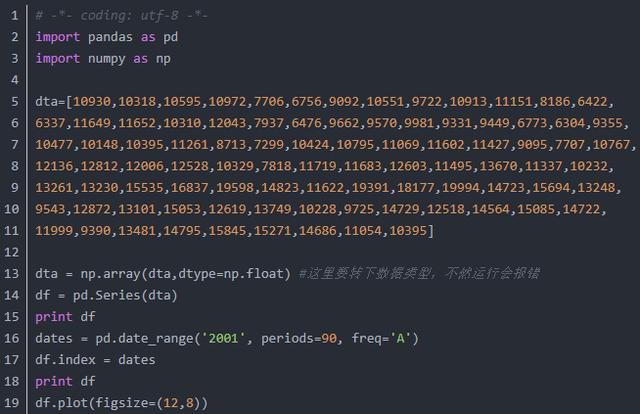
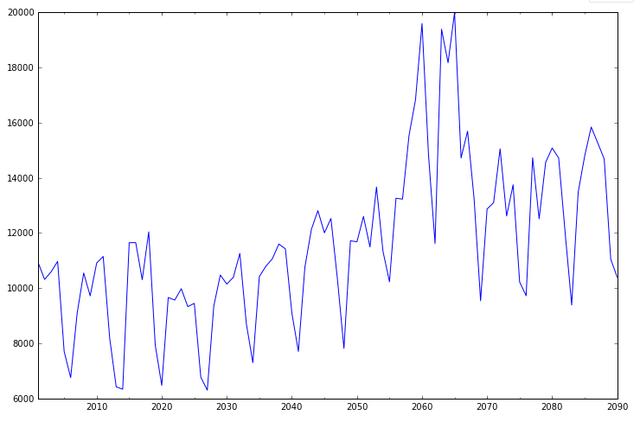
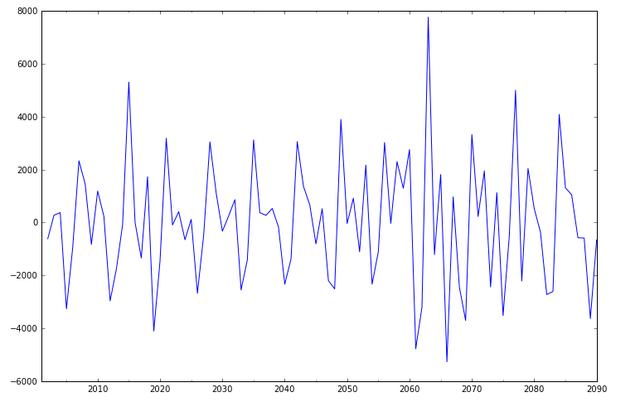
代码从2001年到2090年共有90组数据,然后按照年份进行时间序列统计(freq='A'年份),输出结果如下所示:

绘制图形如下:
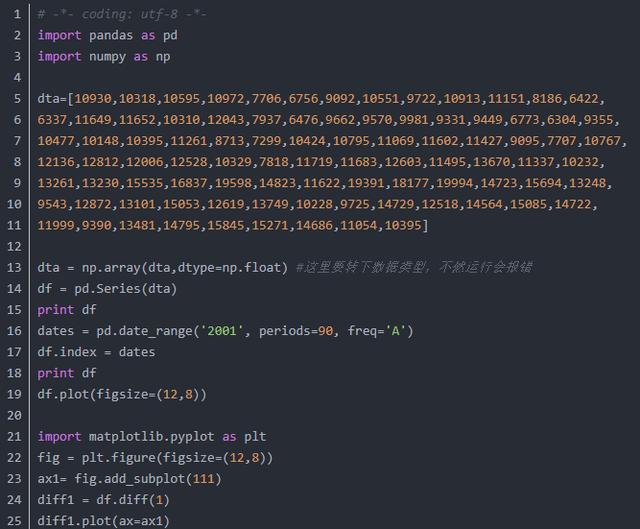
2.时间序列差分d
ARIMA模型要求是平稳型,如果是非平稳型的时间序列需要先做时间序列的差分,得到一个平稳的时间序列。如果时间序列做d次差分才能得到一个平稳序列,则可使用ARIMA(p,d,q)模型,其中d表示差分次数。代码如下:
主要调用df.diff(1)实现一阶差分的效果,此数据一阶和二阶差分的结果类似,均值和方差基本问题,这里的差分d值就取1。
得到的平稳图形如下图所示:
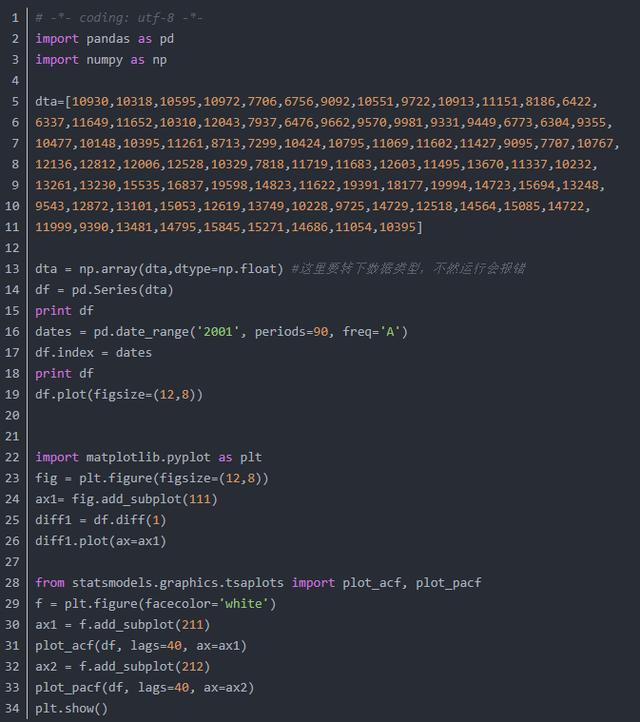
3.合适的q和p值
得到一个平稳的时间序列后,需要选择合适的ARIMA模型,即ARIMA模型中的p和q值。
注意:这里需要调用"pip install statsmodels"安装统计数学分析的包,有时您的版本过低会导致错误(尤其是Anaconda 2.7版本),则需要调用"pip install --upgrade statsmodels"升级包至0.8版本。
代码如下:
输出结果如下所示,主要 调用plot_acf和plot_pacf函数。
最后给出选择ARIMA(8,0)模型对未来10年数据进行的代码。代码如下:


输出相关ARIMA(8,0)系数和预测的2090-2100年结果如下所示:

输出图形如下所示,可以看到后面绿色部分为预测值,根据前面的波动规律近似得到。



















