其实主要是手里面的跑openvpn服务器。因为并没有明文禁p2p(哎……想想那么多流量好像不跑点p2p也跑不完),所以造成有的时候如果有比较多人跑BT的话,会造成VPN速度急剧下降。
本文所面对的情况为:
高并发数
高延迟高丢包(典型的美国服务器)
值得注意的是,因为openvz的VPS权限比较低,能够修改的地方比较少,所以使用openvz的VPS作VPN服务器是非常不推荐的。
我们通过修改 /etc/sysctl.conf 来达到调整的目的,注意修改完以后记得使用:
sysctl -p
来使修改生效。
首先,针对高并发数,我们需要提高一些linux的默认限制:
fs.file-max = 51200
#提高整个系统的文件限制
net.ipv4.tcp_syncookies = 1
#表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
net.ipv4.tcp_tw_reuse = 1
#表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcp_tw_recycle = 0
#表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭;
#为了对NAT设备更友好,建议设置为0。
net.ipv4.tcp_fin_timeout = 30
#修改系統默认的 TIMEOUT 时间。
net.ipv4.tcp_keepalive_time = 1200
#表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时,改为20分钟。
net.ipv4.ip_local_port_range = 10000 65000 #表示用于向外连接的端口范围。缺省情况下很小:32768到61000,改为10000到65000。(注意:这里不要将最低值设的太低,否则可能会占用掉正常的端口!)
net.ipv4.tcp_max_syn_backlog = 8192
#表示SYN队列的长度,默认为1024,加大队列长度为8192,可以容纳更多等待连接的网络连接数。
net.ipv4.tcp_max_tw_buckets = 5000
#表示系统同时保持TIME_WAIT的最大数量,如果超过这个数字,TIME_WAIT将立刻被清除并打印警告信息。
#额外的,对于内核版本新于**3.7.1**的,我们可以开启tcp_fastopen:
net.ipv4.tcp_fastopen = 3
其次,针对大流量高丢包高延迟的情况,我们通过增大缓存来提高 TCP 性能,自己看E文注释吧……感觉我翻译出来各种味道不对 = =:

这里面涉及到一个 TCP 拥塞算法的问题,你可以用下面的命令查看本机提供的拥塞算法控制模块:
sysctl net.ipv4.tcp_available_congestion_control
如果没有下文提到的htcp,hybla算法,你可以尝试通过modprobe启用模块:
/sbin/modprobe tcp_htcp
/sbin/modprobe tcp_hybla
对于几种算法的分析,详情可以参考下: TCP拥塞控制算法 优缺点 适用环境 性能分析 ,但是这里面没有涉及到专门为卫星通讯设计的拥塞控制算法:Hybla。根据各位大神的实验,我们发现Hybla算法恰好是最适合美国服务器的 TCP 拥塞算法,而对于日本服务器,个人想当然的认为htcp算法应该可以比默认的cubic算法达到更好的效果。但是因为htcp算法恰好没有编入我们所使用的VPS中,所以没办法测试。
#设置 TCP 拥塞算法为 hybla
net.ipv4.tcp_congestion_control=hybla
根据Tcp的理论计算,Tcp最佳状态下传输是流水并行的,传输时间等于传输数据耗时+TTL,即千兆网卡的环境下
传输1MB数据需要: 1000ms/100MB*1MB+TTL=10ms+TTL,同机房传输1MB耗时10毫秒,跨机房理论耗时14毫秒
传输4MB数据需要: 1000ms/100MB*4MB+TTL=40ms+TTL,同机房传输4MB需要耗时40毫秒,跨机房理论耗时44毫秒
在我的生产环境,同机房的两个机器之间ping耗时0.15毫秒;两个机器之间读1MB数据和4MB的数据延时极度不稳定,在10毫秒~300毫秒之间波动。
另外一个跨机房使用了专线的环境,两台机器之间ping耗时4毫秒,但两个机器之间读1MB数据和4MB的数据延时也极度不稳定,在40毫秒~500毫秒之间波动。
这个现象看起来就像:网卡压力小时性能差,网卡压力大时性能反而好。
一开始怀疑是网卡驱动有问题,
通过修改网卡驱动参数,关闭NAPI功能,同机房的传输延时有所提升,具体的操作:Disable掉NAPI功能 ,即更改 ethtool -C ethx rx-usecs 0 ,但这个方案有缺点:使得cpu中断请求变多。
另外一个方案:修改tcp的初始化拥塞窗口,强制将初始化拥塞窗口设置为3,即: ip route | while read p; do ip route change $p initcwnd 3;done
这两种方案可以将同机房的读延时至于理论计算水平。
但这两种方案,都无法解决跨机房的长延时问题。进一步追踪如下:
我们测试的延时高,是因为没有享受Tcp高速通道阶段甚至一直处于Tcp慢启动阶段。
我做了下面5步尝试,具体过程如下:
STEP1】 最开始的测试代码:
每次请求建立一个Tcp连接,读完4MB数据后关闭连接,测试的结果:平均延时174毫秒:每次都新建连接,都要经历慢启动阶段甚至还没享受高速阶段就结束了,所以延时高。
STEP2】 改进后的测试代码:
只建立一个Tcp连接,Client每隔10秒钟从Server读4MB数据,测试结果:平均延时102毫秒。
改进后延时还非常高,经过观察拥塞窗口发现每次读的时候拥塞窗口被重置,从一个较小值增加,tcp又从慢启动阶段开始了。
STEP3】改进后的测试代码+设置net.ipv4.tcp_slow_start_after_idle=0:
只建立一个Tcp连接,Client每隔10秒钟从Server读4MB数据,测试结果:平均延时43毫秒。
net.ipv4.tcp_slow_start_after_idle设置为0,一个tcp连接在空闲后不进入slow start阶段,即每次收发数据都直接使用高速通道,平均延时43毫秒,跟计算的理论时间一致。
STEP4】我们线上的业务使用了Sofa-Rpc网络框架,这个网络框架复用了Socket连接,每个EndPoint只打开一个Tcp连接。
我使用Sofa-Rpc写了一个简单的测试代码,Client每隔10秒钟Rpc调用从Server读4MB数据,
即:Sofa-Rpc只建立一个Tcp连接+未设置net.ipv4.tcp_slow_start_after_idle(默认为1),测试结果:延时高,跟理论耗时差距较大:transbuf配置为32KB时,平均延时93毫秒。
STEP5】
Sofa-Rpc只建立一个Tcp连接+设置net.ipv4.tcp_slow_start_after_idle为0,测试结果: transbuf配置为1KB时,平均延时124毫秒;transbuf配置为32KB时,平均延时61毫秒;transbuf配置为4MB时,平均延时55毫秒
使用Sofa-Rpc网络框架,在默认1KB的transbuf时延时124毫秒,不符合预期;
使用Sofa-Rpc网络框架,配置为32KB的transbuf达到较理想的延时61毫秒。32KB跟Sofa-Rpc官方最新版本推荐的transbuf值一致。
结论:
延时高是由于Tcp传输没享受高速通道阶段造成的,
1】需要禁止Tcp空闲后慢启动 :设置net.ipv4.tcp_slow_start_after_idle = 0
2】尽量复用Tcp socket连接,保持一直处于高速通道阶段
3】我们使用的Sofa-Rpc网络框架,需要把Transbuf设置为32KB以上
另附linux-2.6.32.71内核对tcp idle的定义:
从内核代码153行可见在idle时间icsk_rto后需要执行tcp_cwnd_restart()进入慢启动阶段,
Icsk_rto赋值为TCP_TIMEOUT_INIT,其定义为
#define TCP_TIMEOUT_INIT ((unsigned)(3*HZ)) /* RFC 1122 initial RTO value */
1. fs.file-max
最大可以打开的文件描述符数量,注意是整个系统。
在服务器中,我们知道每创建一个连接,系统就会打开一个文件描述符,所以,文件描述符打开的最大数量也决定了我们的最大连接数
select在高并发情况下被取代的原因也是文件描述符打开的最大值,虽然它可以修改但一般不建议这么做,详情可见unp select部分。
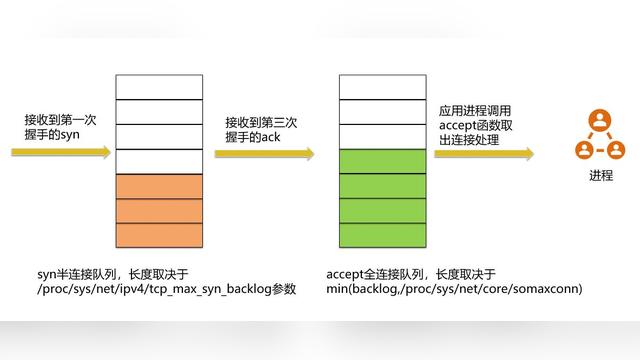
2.net.ipv4.tcp_max_syn_backlog
Tcp syn队列的最大长度,在进行系统调用connect时会发生Tcp的三次握手,server内核会为Tcp维护两个队列,Syn队列和Accept队列,Syn队列是指存放完成第一次握手的连接,Accept队列是存放完成整个Tcp三次握手的连接,修改net.ipv4.tcp_max_syn_backlog使之增大可以接受更多的网络连接。
注意此参数过大可能遭遇到Syn flood攻击,即对方发送多个Syn报文端填充满Syn队列,使server无法继续接受其他连接
可参考此文http://tech.uc.cn/?p=1790
我们看下 man 手册上是如何说的:
The behavior of the backlog argument on TCP sockets changed with Linux 2.2. Now it specifies the queue length for com‐ pletely established sockets waiting to be accepted, instead of the number of incomplete connection requests. The maximum length of the queue for incomplete sockets can be set using /proc/sys/net/ipv4/tcp_max_syn_backlog. When syncookies are enabled there is no logical maximum length and this setting is ignored. See tcp(7) for more information. If the backlog argument is greater than the value in /proc/sys/net/core/somaxconn, then it is silently truncated to that value; the default value in this file is 128. In kernels before 2.4.25, this limit was a hard coded value, SOMAXCONN, with the value 128.
自 Linux 内核 2.2 版本以后,backlog 为已完成连接队列的最大值,未完成连接队列大小以 /proc/sys/net/ipv4/tcp_max_syn_backlog 确定,但是已连接队列大小受 SOMAXCONN 限制,为 min(backlog, SOMAXCONN)
3.net.ipv4.tcp_syncookies
修改此参数可以有效的防范上面所说的syn flood攻击
原理:在Tcp服务器收到Tcp Syn包并返回Tcp Syn+ack包时,不专门分配一个数据区,而是根据这个Syn包计算出一个cookie值。在收到Tcp ack包时,Tcp服务器在根据那个cookie值检查这个Tcp ack包的合法性。如果合法,再分配专门的数据区进行处理未来的TCP连接。
默认为0,1表示开启
4.net.ipv4.tcp_keepalive_time
Tcp keepalive心跳包机制,用于检测连接是否已断开,我们可以修改默认时间来间断心跳包发送的频率。
keepalive一般是服务器对客户端进行发送查看客户端是否在线,因为服务器为客户端分配一定的资源,但是Tcp 的keepalive机制很有争议,因为它们可耗费一定的带宽。
Tcp keepalive详情见Tcp/ip详解卷1 第23章
5.net.ipv4.tcp_tw_reuse
我的上一篇文章中写到了time_wait状态,大量处于time_wait状态是很浪费资源的,它们占用server的描述符等。
修改此参数,允许重用处于time_wait的socket。
默认为0,1表示开启
6.net.ipv4.tcp_tw_recycle
也是针对time_wait状态的,该参数表示快速回收处于time_wait的socket。
默认为0,1表示开启
7.net.ipv4.tcp_fin_timeout
修改time_wait状的存在时间,默认的2MSL
注意:time_wait存在且生存时间为2MSL是有原因的,见我上一篇博客为什么会有time_wait状态的存在,所以修改它有一定的风险,还是根据具体的情况来分析。
8.net.ipv4.tcp_max_tw_buckets
所允许存在time_wait状态的最大数值,超过则立刻被清楚并且警告。
9.net.ipv4.ip_local_port_range
表示对外连接的端口范围。
10.somaxconn
前面说了Syn队列的最大长度限制,somaxconn参数决定Accept队列长度,在listen函数调用时backlog参数即决定Accept队列的长度,该参数太小也会限制最大并发连接数,因为同一时间完成3次握手的连接数量太小,server处理连接速度也就越慢。服务器端调用accept函数实际上就是从已连接Accept队列中取走完成三次握手的连接。
Accept队列和Syn队列是listen函数完成创建维护的。
/proc/sys/net/core/somaxconn修改
上面每一个参数其实都够写一篇文章来分析了,这里我只是概述下部分参数,注意在修改Tcp参数时我们一定要根据自己的实际需求以及测试结果来决定。
问题描述
场景:JAVA的client和server,使用socket通信。server使用NIO。
1.间歇性得出现client向server建立连接三次握手已经完成,但server的selector没有响应到这连接。
2.出问题的时间点,会同时有很多连接出现这个问题。
3.selector没有销毁重建,一直用的都是一个。
4.程序刚启动的时候必会出现一些,之后会间歇性出现。
分析问题
正常TCP建连接三次握手过程:
第一步:client 发送 syn 到server 发起握手;
第二步:server 收到 syn后回复syn+ack给client;
第三步:client 收到syn+ack后,回复server一个ack表示收到了server的syn+ack(此时client的56911端口的连接已经是established)。
从问题的描述来看,有点像TCP建连接的时候全连接队列(accept队列,后面具体讲)满了,尤其是症状2、4. 为了证明是这个原因,马上通过 netstat -s | egrep "listen" 去看队列的溢出统计数据:
反复看了几次之后发现这个overflowed 一直在增加,那么可以明确的是server上全连接队列一定溢出了。
接着查看溢出后,OS怎么处理:
tcp_abort_on_overflow 为0表示如果三次握手第三步的时候全连接队列满了那么server扔掉client 发过来的ack(在server端认为连接还没建立起来)
为了证明客户端应用代码的异常跟全连接队列满有关系,我先把tcp_abort_on_overflow修改成 1,1表示第三步的时候如果全连接队列满了,server发送一个reset包给client,表示废掉这个握手过程和这个连接(本来在server端这个连接就还没建立起来)。
接着测试,这时在客户端异常中可以看到很多connection reset by peer的错误,到此证明客户端错误是这个原因导致的(逻辑严谨、快速证明问题的关键点所在)。
于是开发同学翻看java 源代码发现socket 默认的backlog(这个值控制全连接队列的大小,后面再详述)是50,于是改大重新跑,经过12个小时以上的压测,这个错误一次都没出现了,同时观察到 overflowed 也不再增加了。
到此问题解决,简单来说TCP三次握手后有个accept队列,进到这个队列才能从Listen变成accept,默认backlog 值是50,很容易就满了。满了之后握手第三步的时候server就忽略了client发过来的ack包(隔一段时间server重发握手第二步的syn+ack包给client),如果这个连接一直排不上队就异常了。
但是不能只是满足问题的解决,而是要去复盘解决过程,中间涉及到了哪些知识点是我所缺失或者理解不到位的;这个问题除了上面的异常信息表现出来之外,还有没有更明确地指征来查看和确认这个问题。
深入理解TCP握手过程中建连接的流程和队列

如上图所示,这里有两个队列:syns queue(半连接队列);accept queue(全连接队列)。
三次握手中,在第一步server收到client的syn后,把这个连接信息放到半连接队列中,同时回复syn+ack给client(第二步);
第三步的时候server收到client的ack,如果这时全连接队列没满,那么从半连接队列拿出这个连接的信息放入到全连接队列中,否则按tcp_abort_on_overflow指示的执行。
这时如果全连接队列满了并且tcp_abort_on_overflow是0的话,server过一段时间再次发送syn+ack给client(也就是重新走握手的第二步),如果client超时等待比较短,client就很容易异常了。
在我们的os中retry 第二步的默认次数是2(centos默认是5次)

如果TCP连接队列溢出,有哪些指标可以看呢?
上述解决过程有点绕,听起来懵,那么下次再出现类似问题有什么更快更明确的手段来确认这个问题呢?(通过具体的、感性的东西来强化我们对知识点的理解和吸收。)
netstat -s

比如上面看到的 667399 times ,表示全连接队列溢出的次数,隔几秒钟执行下,如果这个数字一直在增加的话肯定全连接队列偶尔满了。
ss 命令

上面看到的第二列Send-Q 值是50,表示第三列的listen端口上的全连接队列最大为50,第一列Recv-Q为全连接队列当前使用了多少。
全连接队列的大小取决于:min(backlog, somaxconn) . backlog是在socket创建的时候传入的,somaxconn是一个os级别的系统参数。
这个时候可以跟我们的代码建立联系了,比如Java创建ServerSocket的时候会让你传入backlog的值: