作者:engleliu,腾讯 PCG 开发工程师
本文主要介绍 TCP 拥塞控制算法,内容多来自网上各个大佬的博客及《TCP/IP 详解》一书,在此基础上进行梳理总结,与大家分享。因水平有限,内容多有不足之处, 敬请谅解。
在了解 TCP 的拥塞控制之前,先来看看 TCP 的首部格式和一些基本概念。
TCP 头部标准长度是 20 字节。包含源端口、目的端口、序列号、确认号、数据偏移、保留位、控制位、窗口大小、校验和、紧急指针、选项等。

TCP 首部格式
该字段长 4 位,单位为 4 字节。表示为 TCP 首部的长度。所以 TCP 首部长度最多为 60 字节。
目前的 TCP 控制位如下,其中 CWR 和 ECE 用于拥塞控制,ACK、RST、SYN、FIN 用于连接管理及数据传输。
CWR:用于 IP 首部的 ECN 字段。ECE 为 1 时,则通知对方已将拥塞窗口缩小。
ECE:在收到数据包的 IP 首部中 ECN 为 1 时将 TCP 首部中的 ECE 设置为 1,表示从对方到这边的网络有拥塞。
URG:紧急模式
ACK:确认
PSH:推送,接收方应尽快给应用程序传送这个数据。没用到
RST:该位为 1 表示 TCP 连接中出现异常必须强制断开连接。
SYN:初始化一个连接的同步序列号
FIN:该位为 1 表示今后不会有数据发送,希望断开连接。
该字段长度位 16 位,即 TCP 数据包长度位 64KB。可以通过 Options 字段的 WSOPT 选项扩展到 1GB。
受 Data Offset 控制,长度最大为 40 字节。一般 Option 的格式为 TLV 结构:

常见的 TCP Options 有,SACK 字段就位于该选项中。:

TCP Options
SACK 包括了两个 TCP 选项,一个选项用于标识是否支持 SACK,是在 TCP 连接建立时发送;另一种选项则包含了具体的 SACK 信息。
TCP SACK-Permitted Option:
Kind: 4
Length: Variable
+----------+----------+
| Kind=4 | Length=2 |
+----------+----------+
TCP SACK Option:
Kind: 5
Length: Variable
+--------+--------+
| Kind=5 | Length |
+--------+--------+--------+--------+
| Left Edge Of lst Block |
+--------+--------+--------+--------+
| Right Edge Of lst Block |
+--------+--------+--------+--------+
| . . . |
+--------+--------+--------+--------+
| Left Edge Of nth Block |
+--------+--------+--------+--------+
| Right Edge Of nth Block |
+--------+--------+--------+--------+

SACK 的工作原理
为了解决可靠传输以及包乱序的问题,TCP 引入滑动窗口的概念。在传输过程中,client 和 server 协商接收窗口 rwnd,再结合拥塞控制窗口 cwnd 计算滑动窗口 swnd。在 linux 内核实现中,滑动窗口 cwnd 是以包为单位,所以在计算 swnd 时需要乘上 mss(最大分段大小)。

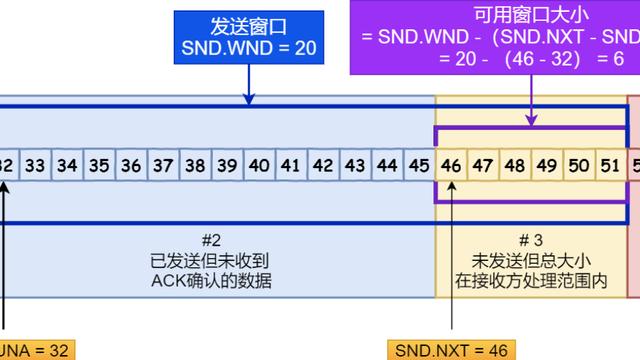
如下图所示滑动窗口包含 4 部分:

TCP滑动窗口
滑动后的示意图如下(收到 36 的 ack,并发出了 46-51 的数据):

TCP滑动后示意图

包守恒原则
TCP 维护一个发送窗口,估计当前网络链路上能容纳的数据包数量,希望在有数据可发的情况下,回来一个确认包就发出一个数据包,总是保持发送窗口那么多包在网络中流动。
传输的理想情况是要同时达到最大的吞吐量和最小的往返延迟,要达到这个目的,连接必须同时满足两个条件:
包守恒原则是拥塞控制的基础。
本文重点介绍 TCP 拥塞控制相关,传输流程不在该范围之内,有兴趣的同学可以查阅相关文档。不过 TCP 重传逻辑和拥塞控制中的快速重传有关,所以在真正介绍拥塞控制算法之前,先来了解下 TCP 重传逻辑。
RTT(Round Trip Time)由三部分组成:链路的传播时间(propagation delay)、末端系统的处理时间、路由器缓存中的排队和处理时间(queuing delay)。TCP 发送端得到了基于时间变化的 RTT 测量值,就能据此设置 RTO。

当一个重传报文段被再次重传时,则增大 RTO 的退避因子γ。通常情况下γ值为 1,多次重传γ加倍增长为 2,4,8 等。通常γ不能超过最大退避因子,Linux 下 RTO 不能超过 TCP_RTO_MAX(默认为 120s)。一旦收到相应的 ACK,γ重置为 1。
下面介绍几种常用的 RTT 算法。
3.1.1 rtt 经典算法 [RFC793]
1)首先,先采样 RTT,记下最近几次的 RTT 值。2)然后做平滑计算 SRTT( Smoothed RTT)。公式为:(其中的 α 取值在 0.8 到 0.9 之间,这个算法英文叫 Exponential weighted moving average,中文叫:加权移动平均)

3)开始计算 RTO。公式如下:

其中:
该算法的问题在于重传时,是用重传的时间还是第一次发数据的时间和 ACK 回来的时间计算 RTT 样本值,另外,delay ack 的存在也让 rtt 不能精确测量。
该算法 [RFC6298] 特点是引入了最新的 RTT 的采样

和平滑过的

的差值做参数来计算。公式如下: 1.计算平滑 RTT

2.计算平滑 RTT 和真实的差距(加权移动平均)

3.计算 RTO

4.考虑到时钟粒度,给 RTO 设置一个下界。

这里G为计时器粒度,1000ms 为整个 RTO 的下届值。因此 RTO 至少为 1s。在 Linux 下,α = 0.125,β = 0.25, μ = 1,∂ = 4 ——这就是算法中的“调得一手好参数”,nobody knows why, it just works…)(Linux 的源代码在:tcp_rtt_estimator)。
5.在首个 SYN 交换前,TCP 无法设置 RTO 初始值。根据 [RFC6298],RTO 初始值为 1s,而初始 SYN 报文段采用的超时间隔为 3s。当计算出首个 RTT 测量结果 ,则按如下方法进行初始化:

3.1.3 Karn 算法
在 RTT 采样测量过程中,如果一个数据包初传后,RTO 超时重传,接着收到这个数据包的 ACK 报文,那么这个 ACK 报文是对应初传 TCP 报文还是对应重传 TCP 报文呢?这个问题就是重传二义性的问题。当没有使用 TSOPT 选项,单纯的 ACK 报文并不会指示对应初传包还是重传包,因此就会发生这个问题。TCP Karn 算法是对经典算法在重传二义性问题上的一种改进。该算法分两部分。1) 当出现超时重传,接收到重传数据的确认信息时不更新 RTT。即忽略了重传部分,避免重传二义性问题。2) 对该数据之后的包采取退避策略,仅当接收到未经重传的数据时,该 SRTT 才用于计算 RTO。
因为单纯忽略重传数据时,如果在某一时间,网络闪动,突然变慢了,产生了比较大的延时,这个延时导致要重转所有的包(因为之前的 RTO 很小),但因为重转的不算,RTO 就不会被更新,这是个灾难。而且一发生重传就对现有的 RTO 值翻倍的方式也很难估算出准确的 RTT。
3.1.4 TCP 时间戳选项(TSOPT)
根据 [RFC1323],TSOPT 主要有两个用途,一个是 RTTM(round-trip time measurement),即根据 ACK 报文中的这个选项测量往返时延;另外一个用途是 PAWS(protect against wrApped sequence numbers),即防止同一个连接的系列号重叠。另外还有一些其他的用途,如 SYN-cookie、Eifel Detection Algorithm 等等。TSOPT 为 Options 选项中一种,格式如下:
Kind: 8
Length: 10 bytes
+-------+-------+---------------------+---------------------+
Kind=8 | 10 | TS Value (TSval) |TS Echo Reply (TSecr)|
+-------+-------+---------------------+---------------------+
1 1 4 4
RTT 测量(RTTM)
当使用这个选项的时候,发送方在 TSval 处放置一个时间戳,接收方则会把这个时间通过 TSecr 返回来。因为接收端并不会处理这个 TSval 而只是直接从 TSecr 返回来,因此不需要双方时钟同步。这个时间戳一般是一个单调增的值,[RFC1323]建议这个时间戳每秒至少增加 1。其中在初始 SYN 包中因为发送方没有对方时间戳的信息,因此 TSecr 会以 0 填充,TSval 则填充自己的时间戳信息。
防回绕序列号(PAWS)
TCP 判断数据是新是旧的方法是检查数据的序列号是否位于 sun.una 到 sun.una + 的范围内,而序列号空间的总大小为 ,即约 4.29G。在万兆局域网中,4.29G 字节数据回绕只需几秒钟,这时 TCP 就无法准确判断数据的新旧。
PAWS 假设接收到的每个 TCP 包中的 TSval 都是随时间单调增的,基本思想就是如果接收到的一个 TCP 包中的 TSval 小于刚刚在这个连接上接收到的报文的 TSval,则可以认为这个报文是一个旧的重复包而丢掉。时间戳回绕的速度只与对端主机时钟频率有关。Linux 以本地时钟计数(jiffies)作为时间戳的值,假设时钟计数加 1 需要 1ms,则需要约 24.8 天才能回绕一半,只要报文的生存时间小于这个值的话判断新旧数据就不会出错。
SYN Cookie 的选项信息
TCP 开启 SYNCookie 功能时由于 Server 在收到 SYN 请求后不保存连接,故 SYN 包中携带的选项(WScale、SACK)无法保存,当 SYN Cookie 验证通过、新连接建立之后,这些选项都无法开启。
使用时间戳选项就可以解决上述问题。将 WScale 和 SACK 选项信息编码进 32 bit 的时间戳值中,建立连接时会收到 ACK 报文,将报文的时间戳选项的回显信息解码就可以还原 WScale 和 SACK 信息。
快速重传算法概括为:TCP 发送端在观测到至少 dupthresh(一般为 3) 个重复 ACK 后,即重传可能丢失的数据分组,而不需等待重传计时器超时。
如下图所示(绿色为已发送并且被 ack 的数据包,黄色表示已发送还未确认的数据包,浅绿色为被 Sack 确认的数据包,蓝色表示还未发送的数据包),设 dupthresh = 3,SACKed_count = 6,从 unAcked 包开始的 SACKed_count - dupthresh 个数据包,即 3 个数据包会被标记为 LOST。

拥塞窗口状态
记分板状态如下,红色表示该数据包丢失:

记分板状态
FACK 是 SACK 的一个激进版本,它拥有标准 SACK 算法的一切性质,除此之外,它假设网络不会使数据包乱序,因此收到最大的被 SACK 的数据包之前,FACK 均认为是丢失的。FACK 模式下,重传时机为 被 SACKed 的包数 + 空洞数 > dupthresh。
如下图所示,设 dupthresh = 3,FACKed_count = 12,从 unACKed 包开始的 FACKed_count

拥塞窗口状态
记分板状态如下,红色表示该数据包丢失:

记分板状态
3.2.3 RACK 重传
基本思路 如果数据包 p1 在 p2 之前发送,没有收到 p1 的确认,当收到 p2 的 Sack 时,推断 p1 丢包。算法简介 每一个 skb 记录发送时间 xmit_time,传输控制块维护全局变量:rack.xmit_time,rack.reo_wnd。rack.xmit_time 是接收方已经收到的最新的那个 skb 的发送时间,rack.reo_wnd 是乱序的时间窗口大小。
1.每次收到新的 ACK 后,更新 reo_wnd,其中 rtt_min 为固定时间窗口的 rtt 最小值。

2.每当收到一个 ACK 或者 SACK 的时候,更新 rack.xmit_time。再去遍历发送队列上已经发送但还没有收到确认的数据包(skb),如果满足如下条件,那么标记这个数据包丢了。

3.如果没有收到确认,那么就用定时器每个一段时间看看有哪些包丢了,如果满足如下条件,那么把这个 skb 标记为已经丢了:

注:目前 linux 内核中只实现了第一种判断方法,定时器还没有实现,这样的话就还没有解决对于尾部包丢失的问题。
3.2.4 乱序检测
乱序检测的目的时探测网络是否发生重排导致的丢包,并以此来更新 dupthresh 值。只要能收到一个 ACK 或者 SACK,其序列号位于当前已经被 ACK 或 SACK 的数据包最大的序列号之前,就说明网络发生了重排造成了乱序,此时如果涉及的数据包大小大于当前能容忍的网络乱序值,即 dupthresh 值,就说明网络乱序加重了,此时应该更新 dupthresh 值。之所以保持 dupthresh 的值递增,是考虑其初始值 3 只是一个经验值,既然真实检测到乱序,如果其值比 3 小,并不能说明网络的乱序度估计偏大,同时 TCP 保守地递增乱序度,也是为了让快速重传的进入保持保守的姿态,从而增加友好性。

一旦发现 dupthresh 值更新的情形,FACK 的假设便不成立,必须在连接内永久禁用 FACK 算法。
要解决的问题: 当无法收到足够的 dupack 时,TCP 标准的 Fast Retransmit 机制无法被触发,只能等待 RTO 超时才能进行丢包的重传。而 RTO 超时不管是时间等待代价,还是性能损耗代价都很大。
解决方法: 检测出无法收到足够 dupack 的场景,进而降低 dupack threshold 来触发快速重传。从而避免等待 RTO 超时重传,对性能造成较大的损耗。
总结出现 dupack 不够的情况:a. cwnd 较小 b. 发送窗口里大量的数据包都被丢失了 c.在数据发送的尾端发生丢包时
但是,上面各种极端的 case 有共同的特点:m. 无法产生足够的 dupack n.没有新的数据包可以发送进入网络,ER 机制就是在判断条件 m 和 n 都成立后,选择降低触发 Fast Retransmit 的阈值,来避免只能通过 RTO 超时重传的问题。
ER 算法解决了 dupack 较少时无法触发快速重传的问题,但当发生尾丢包时,由于尾包后没有更多数据包,也就无法触发 dupack。TLP 算法通过发送一个 loss probe 包,以产生足够的 SACK/FACK 数据包来触发重传。TLP 算法会在 TCP 还是 Open 态时设置一个 Probetimeout(PTO),当链路中有未被确认的数据包,同时在 PTO 时间内未收到任何 ACK,则会触发 PTO 超时处理机制。TLP 会选择传输序号最大的一个数据包作为 tail loss probe 包,这个序号最大的包可能是一个可以发送的新的数据包,也可能是一个重传包。TLP 通过这样一个 tail loss probe 包,如果能够收到相应的 ACK,则会触发 FR 机制,而不是 RTO 机制。
在很多情况下,即使没有出现数据丢失也可能引发重传。这种不必要的重传称为伪重传,其主要造成原因是伪超时,即过早判定超时,其他因素如包失序、包重复,或 ACK 丢失也可能导致该现象。在实际 RTT 显著增长,超过当前 RTO 时,可能出现伪超时。在下层协议性能变化较大的环境中(如无线环境),这种情况出现得比较多。
TCP 为处理伪超时问题提出了许多方法。这些方法通常包含检测算法与响应算法。检测算法用于判断某个超时或基于计时器的重传是否真实,一旦认定出现伪超时则执行响应算法,用于撤销或减轻该超时带来的影响。检测算法包含 DSACK 、Eifel 检测算法、迁移 RTO 恢复算法(F-RTO) 三种。
DSACK 的主要目的是判断何时的重传是不必要的,并了解网络中的其他事项。通过 DSACK 发送端至少可以推断是否发生了包失序、 ACK 丢失、包重复或伪重传。D-SACK 使用了 SACK 的第一个段来做标志, a. 如果 SACK 的第一个段的范围被 ACK 所覆盖,那么就是 D-SACK。b.如果 SACK 的第一个段的范围被 SACK 的第二个段覆盖,那么就是 D-SACK。RFC2883]没有具体规定发送端对 DSACK 怎样处理。[RFC3708]给出了一种实验算法,利用 DSACK 来检测伪重传,响应算法可采用 Eifel 响应算法。
实验性的 Eifel 检测算法利用了 TCP 的 TSOPT 来检测伪重传。在发生超时重传后,Eifel 算法等待接收下一个 ACK,若为针对第一次传输(即原始传输)的确认,则判定该重传是伪重传。
与 DSACK 的比较:利用 Eifel 检测算法能比仅采用 DSACK更早检测到伪重传行为,因为它判断伪重传的 ACK 是在启动丢失恢复之前生成的。相反, DSACK 只有在重复报文段到达接收端后才能发送,并且在 DSACK 返回至发送端后才能有所响应。及早检测伪重传更为有利,它能使发送端有效避免“回退 N”行为。
前移 RTO 恢复(Forward-RTO Recovery,F-RTO)[RFC5682]是检测伪重传的标准算法。它不需要任何 TCP 选项,因此只要在发送端实现该方法后,即使针对不支持 TSOPT 的接收端也能有效地工作。该算法只检测由重传计时器超时引发的伪重传,对之前提到的其他原因引起的伪重传则无法判断。
F-RTO 的工作原理如下:1. F-RTO 会修改 TCP 的行为,在超时重传后收到第一个 ACK 时,TCP 会发送新(非重传)数据,之后再响应后一个到达的 ACK。2.如果其中有一个为重复 ACK,则认为此次重传没问题。3. 如果这两个都不是重复 ACK,则表示该重传是伪重传。4.重复 ACK 是在接收端收到失序的报文段产生的。这种方法比较直观。如果新数据的传输得到了相应的 ACK,就使得接收端窗口前移。如果新数据的发送导致了重复 ACK,那么接收端至少有一个或更多的空缺。这两种情况下,接收新数据都不会影响整体数据的传输性能。
TCP 通过拥塞状态机来决定收到 ACK 时 cwnd 的行为(增长或者降低)。TCP 拥塞状态机有 Open,Disorder,Recovery,Lost和CWR五种状态。

TCP拥塞控制状态机
当网络中没有发生丢包,也就不需要重传,sender 按照慢启动或者拥塞避免算法处理到来的 ACK。
当 sender 检测到 dupack 或者 SACK,将会转移到 Disorder 状态,当处在这个这个状态中时,cwnd 将维持不变。每收到一个 dupack 或 SACK,发送方将发送一个新包。
当 sender 收到 ACK 包含显示拥塞通知(ECN),这个 ECN 由路由器写在 IP 头中,告诉 TCP sender 网络拥塞,sender 不会立马降低 cwnd,而是根据快速恢复算法进行降窗,直到减为之前的一半。当 cwnd 正在减小 cwnd,网络中有没有重传包时,这个状态就叫 CWR,CWR 可以被 Recovery 或者 Loss 中断。
当 sender 因为快速重传机制触发丢包时,sender 会重传第一个未被 ACK 的包,并进入 Recovery 状态。在 Recovery 状态期间,cwnd 的处理同 CWR 大致一样,要么重传标记了 lost 的包,要么根据保守原则发送新包。直到网络中所有的包都被 ACK,才会退出 Recovery 进入 Open 状态,Recovery 状态可以被 loss 状态打断。

时退出 Recovery 状态。

Reno 模式退出Recovery状态
如上图,数据包 A、B、C 可能没有丢失只是被延迟接收,然而没有 SACK 机制下无法判断是 A、B、C 的重传触发的 3 次重复 ACK 还是新数据 1、2、3 丢失 1(或者 1、2 或者 1、2、3)导致的重复 ACK,两种情况均会马上把拥塞状态机带入到 Recovery 状态,然而前一种是不必要的。如果在 SND_UNA== SND_HIGH 即转为 Open 态,那么当发生上述 1、2、3 的延迟到达后,紧接着的 Recovery 状态会再次将拥塞窗口减半,最终降低到一个极低值。

时退出 Recovery 状态。 因为即使发生经典 Reno 模式下的 A、B、C 失序到达,由于存在 SACK 信息,状态机会将此三个重复 ACK 记为三个重复的 DSACK,在 SACK 模式下,判断是否进入 Recovery 状态的条件是被 SACK 的数据包数量大于 dupthresh,而 DSACK 不被计入到 SACKed 数量中。FACK 模式下只影响进入 Recovery 状态的时机,其核心仍建立在 SACK 之上,所以不影响退出的时机。

SACK/FACK模式退出Recovery状态
4.5 Loss
当 RTO 后,TCPsender 进入 Loss 状态,所有在网络中的包被标记为 lost,cwnd 重置为 1,通过 slow start 重新增加 cwnd。Loss 与 Recovery 状态的不同点在于,cwnd 会重置为 1,但是 Recovery 状态不会,Recovery 状态下拥塞控制通过快速恢复算法逐步降低 cwnd 至 sshthresh。Loss 状态不能被其它任何状态中断,只有当网络中所有的包被成功 ACK 后,才能重新进入 Open 状态。
拥塞的发生是因为路由器缓存溢出,拥塞会导致丢包,但丢包不一定触发拥塞。拥塞控制是快速传输的基础。一个拥塞控制算法一般包括慢启动算法、拥塞避免算法、快速重传算法、快速恢复算法四部分。

拥塞窗口示意图
不同拥塞算法慢启动的逻辑有所不同,经典的 NewReno 慢启动的算法如下:
Linux 3.0 后采用了 google 的论文《An Argument for Increasing TCP’s Initial Congestion Window》的建议——把 cwnd 初始化成了 10 个 MSS。而 Linux 3.0 以前,比如 2.6,Linux 采用了[RFC3390] 的建议,cwnd 跟 MSS 的值来变,如果 MSS < 1095,则 cwnd = 4;如果 MSS >2190,则 cwnd = 2;其它情况下,则是 3。
当 cwnd 增长到 sshthresh 时,就会进入“拥塞避免算法”。拥塞避免算法下 cwnd 成线性增长,即每经过一个往返时间 RTT 就把发送方的拥塞窗口 cwnd 加 1,而不是加倍。这样就可以避免拥塞窗口快速增长的问题。
每收到一个 ack 时 cwnd 的变化:
cwnd = cwnd + 1 / cwnd
快速重传算法主要用于丢包检测,以便能更快重传数据包,更早的调整拥塞状态机状态,从而达到持续升窗的目的。具体重传策略见第三节 重传机制。
当检测到丢包时,TCP 会触发快速重传并进入降窗状态。该状态下 cwnd 会通过快速恢复算法降至一个合理值。从历史发展来看,分为四个个阶段。
优点:在快速恢复期间,可以尽可能多的发送数据缺点:由于快速恢复未完成,尽可能多发送可能会加重拥塞。#### 5.4.2 [RFC3517]版本 1) 收到 3 次重复 ACK,ssthresh 设为 cwnd/2,cwnd = cwnd / 2 + 3; 2)每收到一个重复 ACK,窗口值加 1/cwnd; 3) 收到非重复 ACK,窗口设为 ssthresh,退出。
优点:在快速恢复期间,可以尽少量的发送数据(有利于拥塞恢复),且在快速恢复时间段的最后阶段,突发有利于抢带宽。
缺点:快速恢复末期的突发不利于公平性。
Linux 上并没有按照 [RFC3517] 标准实现,而是做了一些修改并运用到内核中。
1.收到 3 次重复 ACK,sshthresh 设置为 cwnd/2,窗口维持不变。2.每收到两个 ACK(不管是否重复),窗口值减 1:cwnd = cwnd - 1。3.新窗口值取 cwnd = MIN(cwnd, in_flight+1)。4.直到退出快速恢复状态,cwnd = MIN(cwnd, ssthresh)。
优点:在快速恢复期间,取消窗口陡降过程,可以更平滑的发送数据 缺点:降窗策略没有考虑 PIPE 的容量特征,考虑一下两点:
a.如果快速恢复没有完成,窗口将持续下降下去 b.如果一次性 ACK/SACK 了大量数据,in_flight 会陡然减少,窗口还是会陡降,这不符合算法预期。
PRR 算法是最新 Linux 默认推荐的快速恢复算法。prr 算法是一种按比例降窗的算法,其最终效果是:
1.在快速恢复过程中,拥塞窗口非常平滑地向 ssthresh 收敛;2.在快速恢复结束后,拥塞窗口处在 ssthresh 附近
PRR 降窗算法实时监控以下的变量:in_flight:它是窗口的一个度量,in_flight 的值任何时候都不能大于拥塞窗口的大小。
prr_delivered:本次收到 ACK 进入降窗函数的时候,一共被 ACK 或者 SACK 的数据段数量。它度量了本次从网络中清空了哪些数据段,从而影响 in_flight。
prr_out:进入快速恢复状态后已经被发送了多少数据包。在 transmit 例程和 retransmit 例程中递增。
to_be_out:当前还可以再发多少数据包。
算法原理根据数据包守恒原则,能够发送的数据包总量是本次接收到的 ACK 中确认的数据包的总量,然而处在拥塞状态要执行的并不是这个守恒发送的过程,而是降窗的过程,因此需要在被 ACK 的数据包数量和可以发送的数据包数量之间打一个折扣,PRR 希望达到的目标是:

以此来将目标窗口收敛于 ssthresh。刚进入快速恢复的时候的时候,窗口尚未下降,在收敛结束之前,下面的不等式是成立的:

这意味着在收敛结束前,我们可以多发送 extra 这么多的数据包。
降窗流程 根据上述原理可以得到 prr 算法降窗流程如下:
1.收到多次(默认为 3)重复 ACK,根据回调函数更新 ssthresh (reno 算法为 cwnd/2),窗口维持不变;
2.每收到 ACK(不管是否重复),按上述算法计算 Extra; 3. 新窗口值取 cwnd = in_flight + Extra; 4. 直到退出快速恢复,cwnd = ssthresh;
优点:在快速恢复期间,取消了窗口陡降过程,可以更平滑发送数据,且降窗速率与 PIPE 容量相关。缺点:不利于在拥塞恢复到正常时突发流量的发送。
记分板算法是为了统计网络中正在传输的包数量,即tcp_packets_in_flight。只有当 cwnd > tcp_packets_in_flight 时,TCP 才允许发送重传包或者新数据包到网络中。tcp_packets_in_flight和packets_out, sacked_out, retrans_out,lost_out有关。其中packets_out表示发出去的包数量,sacked_out为sack的包数量,retrans_out为重传的包数量,lost_out为loss的包数量,这里的loss包含rto,FR和RACK等机制判断出来的丢失包。

为了可以正确统计这些数据,内核给每个 tcp 包(tcp_skb_cb)添加了sacked字段标记该数据包当前的状态。
__u8 sacked; /* State flags for SACK. */
#define TCPCB_SACKED_ACKED 0x01 /* SKB ACK'd by a SACK block */
#define TCPCB_SACKED_RETRANS 0x02 /* SKB retransmitted */
#define TCPCB_LOST 0x04 /* SKB is lost */
#define TCPCB_TAGBITS 0x07 /* All tag bits */
#define TCPCB_REPAIRED 0x10 /* SKB repaired (no skb_mstamp_ns) */
#define TCPCB_EVER_RETRANS 0x80 /* Ever retransmitted frame */
#define TCPCB_RETRANS (TCPCB_SACKED_RETRANS|TCPCB_EVER_RETRANS|
TCPCB_REPAIRED)
需要在意的有TCPCB_SACKED_ACKED(被 SACK 块 ACK'd),TCPCB_SACKED_RETRANS(重传),TCPCB_LOST(丢包),其状态转换图如下:

sack 处理记分板
记分板状态转换逻辑如下:
在 [RFC2861] 中,区分了 TCP 连接数据传输的三种状态:
cwnd 代表了对网络拥塞状态的一个评估,拥塞控制要根据 ACK 来更新 cwnd 的前提条件是,当前的数据发送速率真实的反映了 cwnd 的状况,也就是说当前传输状态是 network-limited。假如 tcp 隔了很长时间没有发送数据包,即进入 idle,那么当前真实的网络拥塞状态很可能就会与 cwnd 反映的网络状况有差距。另外在 application-limited 的场景下,受限数据的 ACK 报文还可能把 cwnd 增长到一个异常大的值,显然是不合理的。基于上面提到的两个问题,[RFC2861]引入了拥塞窗口校验(CWV,Congestion Window Validation)算法。
算法如下:当需要发送新数据时,首先看距离上次发送操作是否超过一个 RTO,如果超过,则 1. 更新 sshthresh 值,设为 max(ssthresh, (3/4) * cwnd)。2.每经过一个空闲 RTT 时间,cwnd 值减半,但不小于 1 SMSS。
对于应用受限阶段(非空闲阶段),执行相似的操作:1. 已使用的窗口大小记为W used 。2. 更新 ssthresh 值,设为 max(ssthresh, (3/4) * cwnd)。
上述操作均减小了 cwnd,但 ssthresh 维护了 cwnd 的先前值。避免空闲阶段可能发生的大数据量注入,可以减轻对有限的路由缓存的压力,从而减少丢包情况的产生。注意 CWV 减小了 cwnd 值,但没有减小 ssthresh,因此采用这种算法的通常结果是,在长时间发送暂停后,发送方会进入慢启动阶段。Linux TCP 实现了 CWV 算法并默认启用。
New Reno 算法包含第五节中介绍的慢启动算法、拥塞避免算法、快速重传算法和 prr 算法。在此就不赘述。

Reno cwnd 图
CUBIC 算法和 Reno 算法区别主要在于慢启动和拥塞避免两个阶段。因为 Reno 算法进入拥塞避免后每经过一个 RTT 窗口才加 1,拥塞窗口增长太慢,导致在高速网络下不能充分利用网络带宽。所以为了解决这个问题,BIC 和 CUBIC 算法逐步被提了出来。
(BIC 算法基于二分查找,实现复杂,不看了。)
cubic 算法源码见 tcp_cubic 文件。

cubic 窗口增长函数
CUBIC 的窗口增长函数是一个三次函数,非常类似于 BIC-TCP 的窗口增长函数。CUBIC 的详细运行过程如下,当出现丢包事件时,CUBIC 同 BIC-TCP 一样,会记录这时的拥塞窗口大小作为 W max,接着通过因子 执行拥塞窗口的乘法减小,这里β是一个窗口降低常数,并进行正常的 TCP 快速恢复和重传。从快速恢复阶段进入拥塞避免后,使用三次函数的凹轮廓增加窗口。三次函数被设置在 W max 处达到稳定点,然后使用三次函数的凸轮廓开始探索新的最大窗口。
CUBIC 的窗口增长函数公式如下所示:

其中,*W(t)*代表在时刻 t 的窗口大小,C 是一个 CUBIC 的常量参数,t 是从上次丢包后到现在的时间,以秒为单位。K 是上述函数在没有进一步丢包的情况下将 W 增加到 W max
经历的时间,其计算公式如下:

其中β 也是常量(默认为 0.2)。

static inline void bictcp_update(struct bictcp *ca, u32 cwnd, u32 acked)
{
// ...
if (ca->epoch_start == 0) { //丢包后,开启一个新的时段
ca->epoch_start = tcp_jiffies32; /* record beginning */
ca->ack_cnt = acked; /* start counting */
ca->tcp_cwnd = cwnd; /* syn with cubic */
//取max(last_max_cwnd , cwnd)作为当前Wmax饱和点
if (ca->last_max_cwnd <= cwnd) {
ca->bic_K = 0;
ca->bic_origin_point = cwnd;
} else {
/* Compute new K based on
* (wmax-cwnd) * (srtt>>3 / HZ) / c * 2^(3*bictcp_HZ)
*/
ca->bic_K = cubic_root(cube_factor
* (ca->last_max_cwnd - cwnd));
ca->bic_origin_point = ca->last_max_cwnd;
}
}
//...
}
标准的慢启动在 BDP 网络环境下表现不好,不好的原因主要有两个:
总结这些原因都是因为慢启动过程过于盲目,不能及时的预测拥塞,导致了大量丢包,所以混合慢启动机制的主要作用是在慢启动阶段试图找到“合理”的退出慢启动进入拥塞避免状态点(safe exit point)。
Hystart 算法通过 ACK train 信息判断一个 Safe Exit Point for Slow Start.同时为了避免计算带宽,通过一个巧妙的转换(具体建议看论文),只要判断时间差是否超过 Forward one-way delay()来决定是否退出慢启动。
Hystart 算法通过以下两个条件来判断是否应该退出慢启动 1.一个窗口内的数据包的总传输间隔是否超过 2. 数据包的 RTT sample(默认 8 个样本)是否出现较大幅度的增长。如果前面 8 个样本中的最小 rtt 大于全局最小 rtt 与阈值的和,那么表示网络出现了拥塞,应立马进入拥塞避免阶段
6.3 BBR 算法
BBR 全称 bottleneck bandwidth and round-trip propagation time。基于包丢失检测的 Reno、NewReno 或者 cubic 为代表,其主要问题有 Buffer bloat 和长肥管道两种。和这些算法不同,bbr 算法会时间窗口内的最大带宽 max_bw 和最小 RTT min_rtt,并以此计算发送速率和拥塞窗口。
如下图所示,当没有足够的数据来填满管道时,RTprop 决定了流的行为;当有足够的数据填满时,那就变成了 BtlBw 来决定。这两条约束交汇在点 inflight =BtlBw*RTprop,也就是管道的 BDP(带宽与时延的乘积)。当管道被填满时,那些超过的部分(inflight-BDP)就会在瓶颈链路中制造了一个队列,从而导致了 RTT 的增大。当数据继续增加直到填满了缓存时,多余的报文就会被丢弃了。拥塞就是发生在 BDP 点的右边,而拥塞控制算法就是来控制流的平均工作点离 BDP 点有多远。

发送速率和RTT vs inflight
RTProp : round-trip propagation time BtlBW : bottleneck bandwidth
基于丢包的拥塞控制算法工作在 bandwidth-limited 区域的右边界区域,尽管这种算法可以达到最大的传输速率,但是它是以高延迟和高丢包率作为代价的。在存储介质较为小的时候,缓存大小只比 BDP 大一点,此时这种算法的时延并不会很高。然而,当存储介质变得便宜之后,交换机的缓存大小已经是 ISP 链路 BDP 的很多很多倍了,这导致了 bufferbloat,从而导致了 RTT 从毫秒级升到了秒级。
当一个连接满足以下两个条件时,它可以在达到最高的吞吐量的同时保持最低时延:
1)速率平衡:瓶颈带宽的数据到达速率与 BtlBw 相等;
2)填满管道:所有的在外数据(inflight data)与 BDP(带宽与时延的乘积)相等
bbr 算法关于拥塞窗口的核心就是计算 BtlBW 和 RTprop,根据这两者值计算 BDP。BtlBw 和 RTprop 可能是动态变化的,所以需要实时地对它们进行估计。
计算 RTprop
目前 TCP 为了检测丢包,必须实时地跟踪 RTT 的大小。在任意的时间 t,

表示“噪音”。造成噪声的因素主要有:链路队列,接收方的时延 ACK 配置,ACK 聚合等因素等待。RTprop 是路径的物理特性,并且只有路径变化才会改变。由于一般来说路径变化的时间尺度远远大于 RTprop,所以 RTprop 可以由以下公式进行估计:

即,在一个时间窗口中对 RTT 取最小值。一般将该窗口大小设置为几十秒至几分钟。
计算 BtlBW
bottleneck bandwidth 的估计不像 RTT 那样方便,没有一种 TCPspec 要求实现算法来跟踪估计 bottleneck 带宽,但是,可以通过跟踪发送速率来估计 bottleneck 带宽。当发送方收到一个 ACK 报文时,它可以计算出该报文的 RTT,并且从发出报文到收到 ack 报文这段时间的 data Inflight。这段时间内的平均发送速率就可以以此计算出来:

这个计算出的速率必定小于 bottleneck 速率(因为 delta delivered 是确定的,但是 deltat 会较大)。因此,BtlBw 可以根据以下公式进行估计。

其中,时间窗口大小的值一般为 6~10 个 RTT。
TCP 必须记录每个报文的离开时间从而计算 RTT。BBR 必须额外记录已经发送的数据大小,使得在收到每一个 ACK 之后,计算 RTT 及发送速率的值,最后得到 RTprop 和 BtlBw 的估计值。
bbr 算法输出 pacing_rate 和 cwnd 两个数据。pacing_rate 决定发包速率,cwnd 为窗口大小。每一次 ACK 都会根据当前的模式计算 pacing_rate 和 cwnd。注意在计算 pacing_rate 和 cwnd 时有 pacing_gain 和 cwnd_gain 两个参数,
bottleneck_bandwidth = windowed_max(delivered / elapsed, 10 round trips)
min_rtt = windowed_min(rtt, 10 seconds)
pacing_rate = pacing_gain * bottleneck_bandwidth
cwnd = max(cwnd_gain * bottleneck_bandwidth * min_rtt, 4)
BBR 和 Pacing rate
BBR 算法也是基于状态机。状态机有STARTUP、DRAIN、PROBE_BW、PROBE_RTT四种状态。不同状态下pacing_gain 和 cwnd_gain 的取值会有所不同。

bbr 状态机
STARTUP:初始状态,该状态下类似于传统拥塞控制的慢启动阶段。该状态下pacing_gain和cwnd_gain为2/ln(2)+1。因为这是最小的能够达到 Reno 或者 CUBIC 算法启动速度的值。
/* We use a high_gain value of 2/ln(2) because it's the smallest pacing gain
* that will allow a smoothly increasing pacing rate that will double each RTT
* and send the same number of packets per RTT that an un-paced, slow-starting
* Reno or CUBIC flow would:
*/
static const int bbr_high_gain = BBR_UNIT * 2885 / 1000 + 1;
DRAIN:该状态为排除状态。在STARTUP状态下三轮没有涨幅超过 25%时会进入该状态。该状态下BtlBw会根据bbr_drain_gain逐渐降低,直到 inflight 降到 BDP 为止。
/* The pacing gain of 1/high_gain in BBR_DRAIN is calculated to typically drain
* the queue created in BBR_STARTUP in a single round:
*/
static const int bbr_drain_gain = BBR_UNIT * 1000 / 2885;
PROBE_BW:该状态下会照常计算当前的 bw,即瞬时带宽。然而在计算 pacing rate 以及 cwnd 时,并不会像在 STARTUP 状态时那样用一个很大的增益系数去扩张 pacing rate 和 cwnd,而是顺序的在[5/4,3/4,1,1,1,1,1,1]中选一个,感官上 bw 就在其停止增长的地方上下徘徊了。
/* The gain for deriving steady-state cwnd tolerates delayed/stretched ACKs: */
static const int bbr_cwnd_gain = BBR_UNIT * 2;
/* The pacing_gain values for the PROBE_BW gain cycle, to discover/share bw: */
static const int bbr_pacing_gain[] = {
BBR_UNIT * 5 / 4, /* probe for more available bw */
BBR_UNIT * 3 / 4, /* drain queue and/or yield bw to other flows */
BBR_UNIT, BBR_UNIT, BBR_UNIT, /* cruise at 1.0*bw to utilize pipe, */
BBR_UNIT, BBR_UNIT, BBR_UNIT /* without creating excess queue... */
};
PROBE_RTT:当 PROBE_BW 检测到连续 10s 没有更新 min rtt 时就会进入该状态。该状态的目标是保持 BBR 的公平性并定期排空瓶颈队列,以收敛到真实的 min_rtt。进入该模式时,BBR 会将 cwnd 的上限设置为 4 个数据包。在 flight pkg <= 4 后开始进行 rtt 探测,探测时间为 200ms,探测结束后 BBR 便会记录 min rtt,并离开 PROBE_RTT 进入相应的模式。代码见bbr_update_min_rtt函数。
Q:为什么 PROBE_BW 阶段 bbr_cwnd_gain 为 2? 保证极端情况下,按照 pacing_rate 发送的数据包全部丢包时也有数据继续发送,不会产生空窗期。
Q:为什么在探测最小 RTT 的时候最少要保持 4 个数据包4 个包的窗口是合理的,infilght 分别是:刚发出的包,已经到达接收端等待延迟应答的包,马上到达的应答了 2 个包的 ACK。一共 4 个,只有 1 个在链路上,另外 1 个在对端主机里,另外 2 个在 ACK 里。路上只有 1 个包。
BBR 将它的大部分时间的在外发送数据都保持为一个 BDP 大小,并且发送速率保持在估计得 BtlBw 值,这将会最小化时延。但是这会把网络中的瓶颈链路移动到 BBR 发送方本身,所以 BBR 无法察觉 BtlBw 是否上升了。所以,BBR 周期性的在一个 RTprop 时间内将 pacing_gain 设为一个大于 1 的值,这将会增加发送速率和在外报文。如果 BtlBw 没有改变,那么这意味着 BBR 在网络中制造了队列,增大了 RTT,而 deliveryRate 仍然没有改变。(这个队列将会在下个 RTprop 周期被 BBR 使用小于 1 的 pacing_gain 来消除)。如果 BtlBw 增大了,那么 deliveryRate 增大了,并且 BBR 会立即更新 BtlBw 的估计值,从而增大了发送速率。通过这种机制,BBR 可以以指数速度非常快地收敛到瓶颈链路。
如下图所示,在 1 条 10Mbps,40ms 的流在 20s 稳定运行之后将 BtlBw 提高了 1 倍(20Mbps),然后在第 40s 又将 BtlBw 恢复至 20Mbps。

bbr 带宽变化
下图展示了 1 个 10Mbps,40ms 的 BBR 流在一开始的 1 秒内,发送方(绿线)和接收方(蓝线)的过程。红线表示的是同样条件下的 CUBIC 发送。垂直的灰线表示了 BBR 状态的转换。下方图片展示了两种连接的 RTT 在这段时间的变化。注意,只有收到了 ACK(蓝线)之后才能确定出 RTT,所以在时间上有点偏移。图中标注了 BBR 何时学习到 RTT 和如何反应。

10Mbps、40ms链路上BBR流的第一秒
下图展示了在上图中展示的 BBR 和 CUBIC 流在开始 8 秒的行为。CUBIC(红线)填满了缓存之后,周期性地在 70%~100%的带宽范围内波动。然而 BBR(绿线)在启动过程结束后,就非常稳定地运行,并且不会产生任何队列。

在10Mbps、40ms链路上的BBR流和CUBIC流的前8秒对比
下图展示了在一条 100Mbps,100ms 的链路上,BBR 和 CUBIC 在 60 秒内的吞吐量与随机丢包率(从 0.001%~50%)的关系。在丢包率只有 0.1%的时候,CUBIC 的吞吐量就已经下降了 10 倍,并且在丢包率为 1%的时候就几乎炸了。而理论上的最大吞吐量是链路速率乘以(1-丢包率)。BBR 在丢包率为 5%以下时还能基本维持在最大吞吐量附近,在 15%丢包率的时候虽然有所下降但还是不错。

BBC和CUBIC的吞吐量与丢包率的关系
TCP Westwood 算法简称 TCPW,和 bbr 算法类似是基于带宽估计的一种拥塞控制算法。TCPW 采用和 Reno 相同的慢启动算法、拥塞避免算法。区别在于当检测到丢包时,根据带宽值来设置拥塞窗口、慢启动阈值。
和 bbr 算法不同,tcpw 带宽计算相当粗糙。tcpw 每经过一个 RTT 测量一次带宽。假设经过时间为 delta,该时间内发送完成的数据量为 bk,则采样值为 bk / delta。然后和 rtt 一样,带宽采样值会经过一个平滑处理算出最终的带宽值。

6.4.2 如何确认单位时间的发送量 bk
tcpw 采用一种粗糙的估算方式。在收到回包后,会根据当前的 snd_una 和之前的 snd_una 之间的差值来估算被 ACK 的字节数,即关于 SACK 的信息会被丢失。具体逻辑见westwood_acked_count函数。
static inline u32 westwood_acked_count(struct sock *sk)
{
const struct tcp_sock *tp = tcp_sk(sk);
struct westwood *w = inet_csk_ca(sk);
w->cumul_ack = tp->snd_una - w->snd_una;
/* If cumul_ack is 0 this is a dupack since it's not moving
* tp->snd_una.
*/
if (!w->cumul_ack) {
w->accounted += tp->mss_cache;
w->cumul_ack = tp->mss_cache;
}
if (w->cumul_ack > tp->mss_cache) {
/* Partial or delayed ack */
if (w->accounted >= w->cumul_ack) {
w->accounted -= w->cumul_ack;
w->cumul_ack = tp->mss_cache;
} else {
w->cumul_ack -= w->accounted;
w->accounted = 0;
}
}
w->snd_una = tp->snd_una;
return w->cumul_ack;
}
计算 ssthresh 公式很简单:

源码如下:
/*
* TCP Westwood
* Here limit is evaluated as Bw estimation*RTTmin (for obtaining it
* in packets we use mss_cache). Rttmin is guaranteed to be >= 2
* so avoids ever returning 0.
*/
static u32 tcp_westwood_bw_rttmin(const struct sock *sk)
{
const struct tcp_sock *tp = tcp_sk(sk);
const struct westwood *w = inet_csk_ca(sk);
return max_t(u32, (w->bw_est * w->rtt_min) / tp->mss_cache, 2);
}