Yeslab讲师 曹鑫磊
私有虚拟网络(VPN)是在公用网络基础之上建立的私有加密通信隧道网络,企业对于自管辖网络中个人使用VPN软件行为具有监管责任,但技术上却很难识别VPN的加密与通信方式,因此利用人工智能(AI)领域的神经网络技术从网络流量中识别VPN软件行为是一种全新的检测方法。这种方法完全跟VPN技术解耦,不论VPN软件使用的加密技术如何复杂,神经网络都可以站在VPN使用者的角度去识别VPN行为。在华为HCIA-AI与HCIP-AI认证中,神经网络在被描述为核心技能,本文就将讲解如何使用神经网络来识别VPN流量。
根据我国互联网相关法律,个人及企业在未备案前提下不允许私自建立与使用跨国际VPN线路与软件。但实际情况是企业难以管理个人利用企业网络使用各类VPN软件,甚至自己搭建VPN通道连接至境外服务器。随着VPN技术在不断进步,这类监管任务的难度也在不断提升。
网络行为是主机连接至网络后,向网关或对端发送网络数据包的行为,例如持续均等时间间隔的发包与发送一定流量后马上停止一段时间就被认为是两种不同的网络行为。基于这种方法,我们使用的数据集体现了此类发包规律的明显特征。
神经网络是人工智能领域的流行算法,利用神经网络模型与反向传播技术可以对神经网络进行基于数据的监督学习训练,完成训练的模型会对某些数据的拟合度提高一些。用神经网络搭建数据分类器是计算机视觉、自然语言处理等领域的常用方法,我们也使用这样的方法来处理网络行为数据。
数据
我们使用了公开的VPN流量数据集,该数据集由一家安全企业对近1000名员工的网络数据进行抓包截取,并固化为一些行为特征。这份数据分两个月抓取完成,第一个月由全体员工不连接任何VPN进行正常工作,其流量包含访问公司信箱、OA系统、即时聊天、视频网站、购物网站等。第二个月由全体员工按自己的方式连接VPN进行办公,流量仍包含上述站点。这样就抓取了两份不同标签的网络数据(VPN | NOVPN)
抓取的数据以数据流为基本单位进行了特征提取,提取出来的数据特征如下所示:
· FIAT指标: 向前发送两个数据包之间的时间(固化为四个指标:平均值,最大值,最小值,标准差)
· BIAT指标: 向后发送两个数据包之间的时间(固化为四个指标:平均值,最大值,最小值,标准差)
· FLOWIAT: 形成数据流的两个数据包之间的时间(固化为四个指标:平均值,最大值,最小值,标准差)
· ACTIVE: 时间量,在变成空闲之前的活跃时间
· IDLE: 时间量,在变成活跃之前的空闲时间
这份网络流量数据最终被制作为23个数据属性,1个标签属性,使用Pandas导入数据后如图1所示:
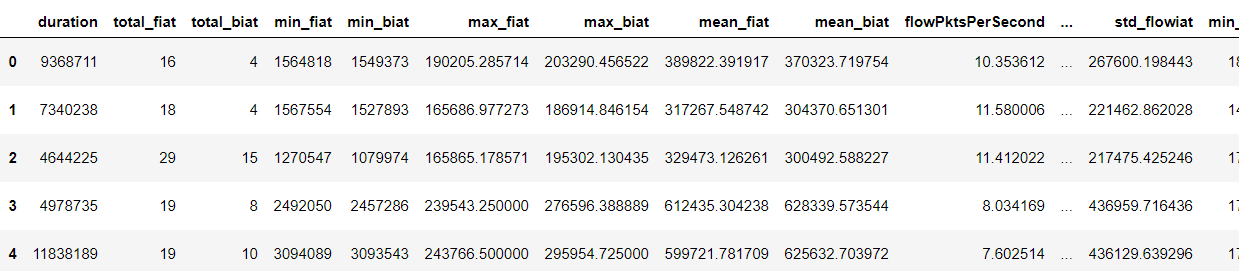
图1:示例数据展示
数据分布
通过观察数据在各个值域的分布情况,可以对数据的质量有所掌握,数据的质量问题会导致模型训练结果不太理想。例如某些数据可能存在部分值域数据非常多,而其他值域几乎没有数据的"一边倒"情况,我们需要通过对数据质量的考察,来决定是否需要做一些数据增强、数据筛选与特征工程。神经网络拥有非常庞大的参数空间,对特征工程的要求偏低。本文所使用的数据分布图如图2所示。

图2:每项属性的数据分布,大多数属性存在上述"一边倒"问题,也是在真实世界中捕获网络流量数据的正常现象
神经网络模型
本文使用的神经网络为多层感知器模型,通过前向传播的线性计算与非线性激活来完成推理过程,推理结果与标签计算获得误差,使用误差通过反向传播的偏微分计算获得残差并最终转化为梯度来更新神经网络的可学习参数。其数学过程不在这里详细讲解,这类知识可以在华为HCIA-AI认证、HCIP-AI认证与华为人才在线平台中获取。
模型结构
本文使用的神经网络模型结构如下:
· 输入层:(None, 23) 维度的数据输入
· 第一个隐含层:32个神经元,激活函数为"ReLU"
· 第二个隐含层:32个神经元,激活函数为"ReLU"
· 第三个隐含层:16个神经元,激活函数为"ReLU"
· 输出层:使用"Sigmoid"激活和函数做 (0-1) 范围的单值输出
· 误差计算使用二值交叉熵
· 优化算法使用"Adam"
· 学习速率:0.0007
神经网络结构图如图3所示,模型参数如图4所示。

图3:本文使用的神经网络架构,这种"先胖后瘦"的结构可以对信息特征的表达空间先做扩充,然后再进行压缩,适用于小型数据集

图4:模型参数
激活函数
激活函数是为神经网络提供非线性输出能力的关键因素,许多著名的神经网络模型(如AlexNet与ResNet等)都非常考究激活函数的选择过程。本文所描述的模型对于所有隐含层均使用ReLU作为激活函数,其函数曲线如图5所示。输出层则使用Sigmoid作为激活输出,其函数曲线如图6所示。

图5:ReLU函数曲线
图6:Sigmoid函数曲线
训练过程
训练数据样本数量为16758,测试数据样本数量为2000,训练时先打乱训练数据,并划分出验证数据集,完成全部训练样本数据的过程记为1次训练,共训练500次,其训练误差与验证误差曲线如图7所示:
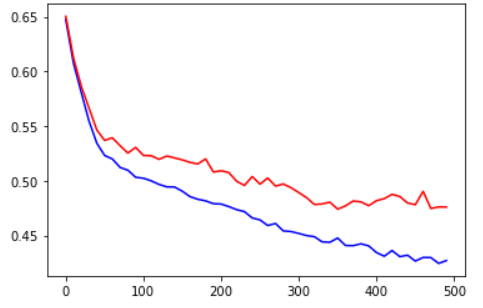
图7:X轴为训练次数,Y轴为误差值,蓝色曲线为训练误差,红色曲线为验证误差
实验结果
最终对测试数据的2000个样本推理准确率为85.56%,本实验的出发点为检测企业中的VPN流量行为,在该人工智能模型支持下,配合人力二次检测,可以有效发现企业中VPN软件的使用情况,让企业不用再耗费高成本采购专业监管设备或服务。
从深度上讲,如果能收集更多的数据,使用神经网络来检测VPN流量就会更加准确,从广度上讲,我们可以使用同类方法检测异常流量、区分个性化应用流量以及预分类恶意流量等。华为的网络人工智能 (NAIE智能体) 就包含了许多利用人工智能来协助运维人员完成问题检测、指标固化、信号强度计算等许多复杂的案例。相信在不远的未来,我们所使用的计算机网络必定能够依靠人工智能技术向每一个人提供更加个性化、差异化的服务。
作者简介:
曹鑫磊,在华为授权合作伙伴(HALP)Yeslab负责华为人工智能和网络自动化方向课程开发和授课,对华为认证有着独到的见解,深受学员好评。