机器之心整理
参与:蛋酱、小舟
一堂为期三小时的手把手 AI 开发教学课程,让开发者学到了什么?

2020 年,人工智能技术进入商业化落地的全新阶段。对于入门不久的初级开发者或者转型中小企业来说,如何最轻松、最高效地进行 AI 开发和部署?
2020 世界人工智能大会云端峰会是由上海市政府打造的国际顶级人工智能会议,于 7 月 9 日正式开幕。「开发者日」作为 WAIC 云端峰会主题论坛及特色活动,也是 WAIC 期间唯一面向 AI 开发者的专业活动。
在 7 月 11 日上午举行的 2020 WAIC「开发者日百度公开课」上,机器之心联合百度为开发者们提供了一堂 3 小时极致学习课程,来自百度 AI 的四位工程师为大家带来了从 NLP、CV 到零门槛 AI 开发平台 EasyDL 的实战经验分享。
本文对此次公开课的核心内容进行了整理,感兴趣的小伙伴可通过文后视频学习。
如何使用 UNIT 搭建智能对话系统
首先是百度资深研发工程师、UNIT 平台的技术负责人孙叔琦讲述「如何使用 UNIT 平台搭建智能对话系统」。
1.UNIT 平台技术与服务全景
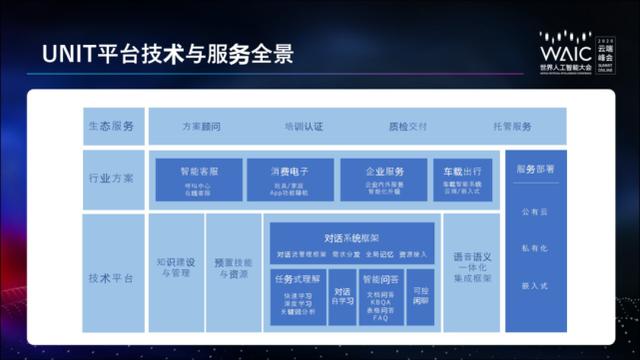
UNIT 平台技术与服务全景。
最底层的核心技术平台包含了知识建设与管理能力、预置技能与资源、核心任务式理解、对话系统框架层面的技术,以及语音和语义一体化集成技术。在基础平台之上,百度为智能客服、消费电子、企业服务、车载出行等常见的行业场景包装了复用度较高的场景方案、行业方案,这些技术和方案都支持公有云部署、私有化部署,在一些特定的场景下还可以支持嵌入式的部署。在技术和方案的上方,是人才方面的生态服务,包括技术方案的顾问服务、培训认证服务、质监交互服务以及托管研发服务。
2.UNIT 平台技术解析
孙叔琦首先进行了技术层面的讲解。使用 UNIT 最方便快捷的方法就是利用其预置技能,大概分为三类:
一类是开发者可以拿来直接用于服务的资源,也就是「开箱即用」,包括天气、智能问答等;
一类是为稍微有一些能力的开发者提供的高准确解析型对话技能,比如对话理解服务,开发者可以在对话理解的结果基础上对接自己的系统;
一类是针对特定领域的轻定制需求,在某些场景下,对话技能需要面向具体业务定制才能满足开发者的实际需要,UNIT 提供的这些技能,可供开发者进行小幅度修改以适配业务。
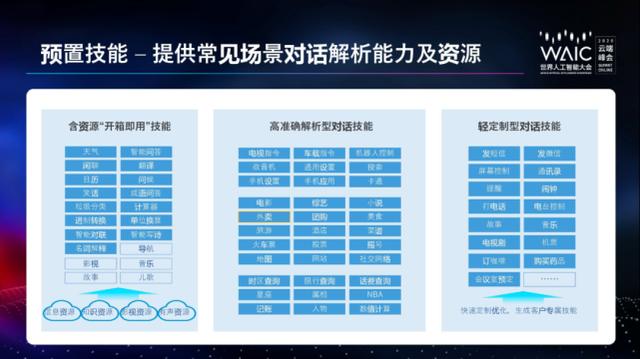
UNIT 的预置技能。
如果预置技能并不能够满足所有的需求,那么就需要开发者自己动手开发一些对话技能。下图是对话系统定制的一般过程。

开发者在平台上需要做的事情首先是定义对话任务,对话任务包括对话意图的定义以及对话规则的定义,并针对所定义的对话任务提供知识,包括意图的表述、意图里面关键词、词槽的一些资源词典以及对话规则里跟业务对接部分的一些资源提供进来,UNIT 平台会自动地通过训练机器学习的方法以及一些配套的机制去生成开发者业务上的对话系统。
对话系统可大致分为两类:任务式对话和问答对话。二者的区别是前者需要对对话的参数化进行精确的处理。任务式对话需要把一句话解析成意图和词槽这样的参数化的形式,而问答对话需要最后的答案。所以问答式对话更倾向于做常见的业务问题的解答。
任务式对话中有一个非常关键的技术「任务式对话理解」。任务式对话理解技术强调的有两点,首先是要提供专业的效果,第二是获取成本要足够低。对话理解技术可以把很长的请求解析成结构化的表达形式,包括意图、词槽以及词槽之间依赖关系,词槽的规范值等等。
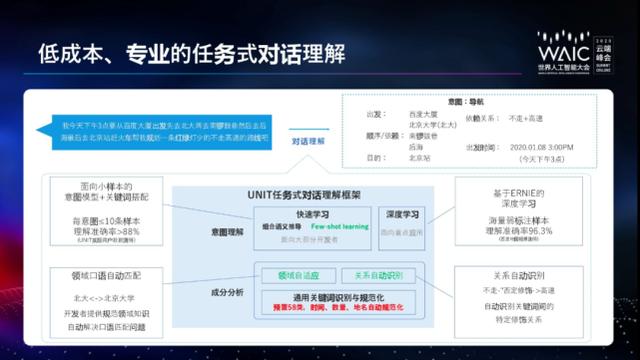
而开发中用到问答对话,是因为问答系统的接入门槛比较低,只需要提供简单的问答资源,系统就可以工作。在此,孙叔琦重点介绍了对话式文档问答和表格问答两种处理技术。
UNIT 整合了文档分析、整合了语义匹配、阅读理解等等技术,为开发者带来了端到端的对话式文档问答技术。开发者可以直接提供业务文档,经过该技术的处理,直接生成针对文档做问答的对话系统。该对话系统在无需整理 FAQ 的情况下,两轮对话之内即可解决 87% 的问题。
数据表格问答方面往往需要大量的预处理工作, UNIT 通过数据分析以及 NL2SQL 的技术,实现了结构化知识问答。开发者提供结构化数据表之后,即可针对数据表做问答,省去了整理数据库、整理数据表格的步骤,直接就可以实现表格问答。
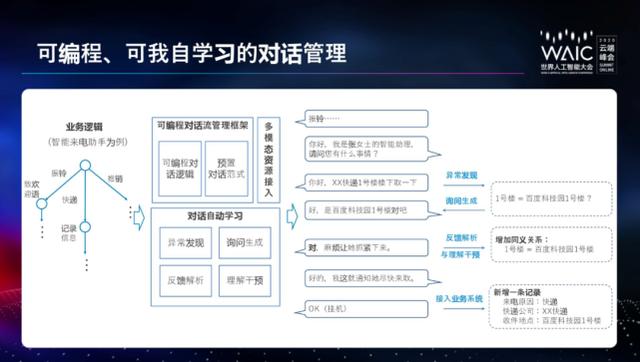
对话管理在开发者的业务中解决的是多轮对话的问题。在多轮对话问题中开发者的主要需求有几种:
对话逻辑要严格的可控;
在一些细小、微观逻辑上面需要尽量多的内置;
在对话过程中希望和业务资源做互动,把业务资源接入进来,让对话系统能够完成业务上的事情;
可能还有一些更高层次的需求,即让对话变得智能,可以自动地学习和成长。
针对这四项需求,对话管理的框架的整体设计如下图。
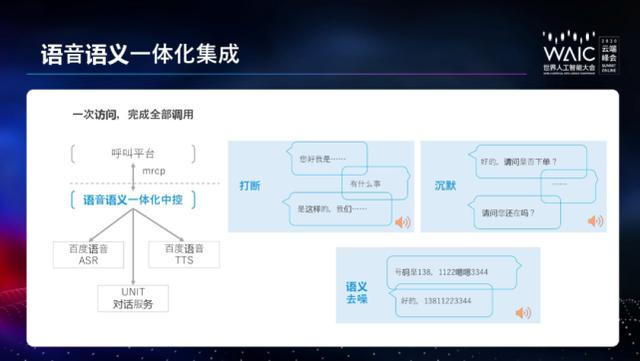
UNIT 设计了语音语义一体化的集成框架,通过语音语义一体化的中控,将百度的语音能力整合进来,在语音的接口上通过端到端地输入语音、输出语音。整合各项技术的同时,还针对语音场景所常见的异常情况提供一些预置处理。
3.UNIT 平台输出模式与生态服务
整个系统开发完成后,怎么和业务系统、和相关服务对接呢?下图展示了 UNIT 对外输出模式。
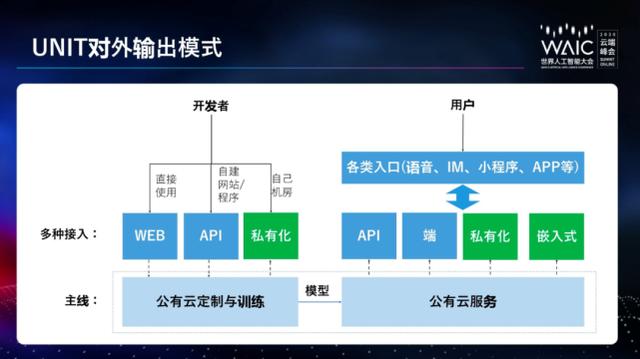
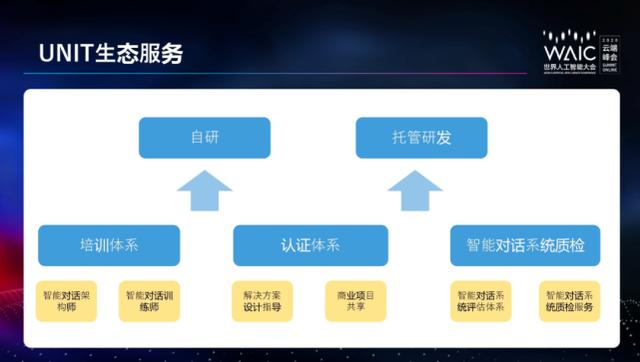
面向入门阶段的开发者,以及自研系统和需要托管研发的业务方,UNIT 都提供了一系列生态服务能力,包括培训、认证等,保证各式各样的开发者均可非常顺利完成对话系统。
4.UNIT 应用落地情况
UNIT 现在主要的应用落地情况,包括四个大的维度:
第一个维度是智能客服,即通过智能 IVR 的方式实现业务咨询、业务办理等需求;
第二个维度是消费电子,主要支持的是手机系统以及 App 里面的语音助手等服务;
第三个维度是车载出行;
第四个维度是企业服务,包括会议管理、智能 BI、智能 OA、服务机器人等。
飞桨视觉技术解析与应用
百度深度学习平台飞桨(PaddlePaddle)资深研发工程师杜宇宁主要介绍了飞桨视觉技术解析与应用。

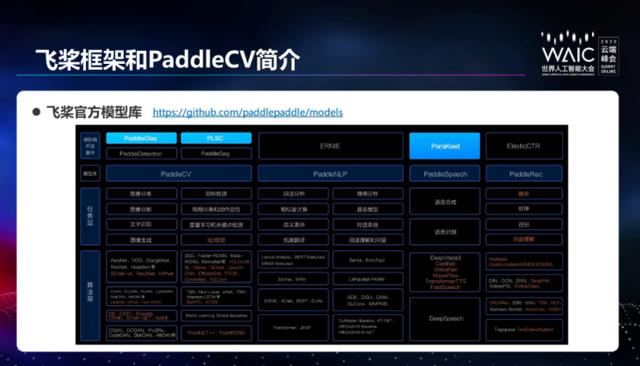
上图为飞桨平台的全景图,主要由飞桨的开源深度学习平台和飞桨企业版两部分组成。
飞桨开源深度学习平台主要包含四个部:核心框架、基础模型库、端到端的开发套件和工具组件。核心框架包括开发、训练和推理三部分,奠定了整个飞桨面向学术研究和产业应用的基础。基础模型库目前覆盖自然语言处理、计算机视觉、推荐、语音等多个方向,算法总数达到 146 个,旨在助力开发者二次开发。端到端的开发套件在基础模型库的升级,对于 AI 典型的任务,打通模型的训练到推理部署的全流程,有助于开发者落地应用 AI 技术。
杜宇宁重点分享了 PaddleCV 模型库以及几个典型的端到端开发套件。PaddleCV 是飞桨针对计算机视觉领域打造的一个模型库,覆盖了图像分类和目标检测、图像分割、视频分类和动作定位、文本识别、度量学习、关键点检测、图像生成、3D 视觉以及模型压缩这些方面。提供了我们常见的这些场景的模型训练方法和使用的预训练模型。在上述基础上又打造了一系列端到端的开发套件,包括 PaddleClas 的图像分类套件、PaddleDetection 目标检测套件、PaddleOCR 的文本识别套件等等。
飞桨近期推出的 PaddleClas 图像分类套件是面向工业界和学术界的图像分类任务工具集。PaddleClas 的模型库非常丰富,包括了 23 个系列的分类网络以及训练配置,提供了 117 个模型在 ImageNet 数据集上的预训练模型和性能评估,这也是目前所知的业界丰富度最高的分类代码库。
此外 PaddleClas 还提供了一个 SSLD 蒸馏方案以及 8 种数据增广方法,帮助使用者提升图像分类的效果。SSLD 蒸馏方案已将 ResNet 50 系列模型的精度提升到了 82.4%,是目前开源里面精度最高的 ResNet50 模型。最新的代码库中,该模型的精度已经进一步从 82.4% 提升到 83%。
PaddleClas 的 github 地址:https://github.com/PaddlePaddle/PaddleClas

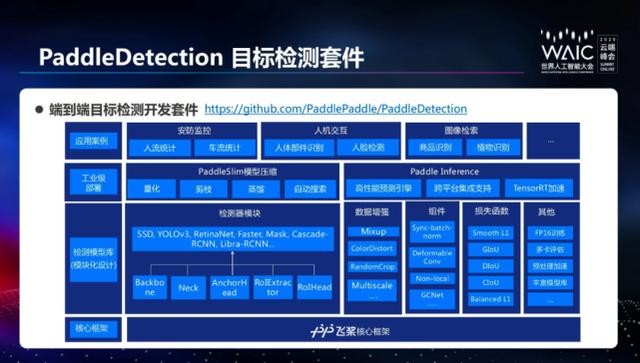
PaddleDetection 套件则提供了多种模块化设计的检测性模块,预置了多种数据增强方式、组件以及损失函数,可与产业应用无缝衔接。在该套件中,对 YOLOv3 模型进行深度优化,精度提升至 43.6%,与原作比,提升 10.6%。此外,针对移动端,嵌入式这些端侧应用,提供了基于 SSD(骁龙 845 预测耗时 41ms,mAP 16.6%)、YoloV3(骁龙 845 预测耗时 110ms,mAP 25.9%)、Faster RCNN(骁龙 845 预测耗时 376ms,mAP 30.2%)的不同优化方案,以满足不同场景对速度和精度的要求。此外它提供了 PaddleSlim 模型压缩和 Paddle Inference 的集成,让检测任务实现在企业中轻松部署,可支撑当前工业质检、遥感图像检测、无人巡检等多方面的产业应用。
PaddleDetection 的 github 地址:https://github.com/PaddlePaddle/PaddleDetection
PaddleOCR 套件是百度推出的旨在打造丰富领先实用的文本识别模型的工具库。目前 PaddleOCR 主要开源包括了两种业界领先的检测算法「EAST」和「DB」,以及包括 CRNN 在内的四种文本识别算法。此外还打造一个大小仅为 8.6M 的超轻量级中文 OCR 识别模型,和一款效果更好的通用中文 OCR 模型。目前,百度自研的检测算法 SAST 以及识别算法 SRN 也在适配过程中,近期也将在 PaddleOCR 内开源。
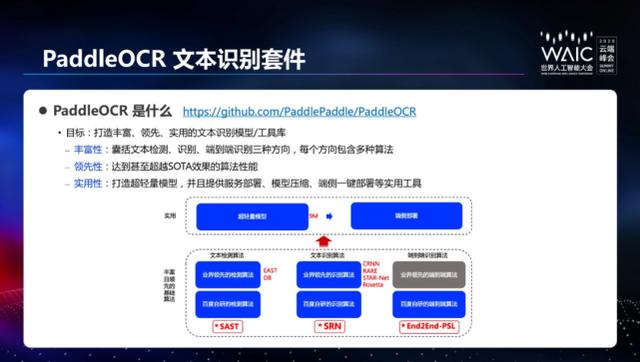
下面介绍了一下 8.6M 超轻量级中文 OCR 模型。超轻量模型的特点就是运行时显存 / 内存占用更小,计算量更少,从而使用更加方便。

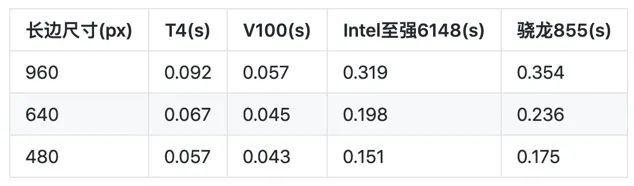
上面表格的预测耗时没有包括预处理时间,近期 PaddleOCR 项目给出最新的超轻量中文模型(8.6M)在各平台的预测部署方案以及预测耗时 benchmark 如下:
当然超轻量模型,模型本身小的话,效果上面不是非常的理想。所以开发者又进一步发布了基于 ResNet 系列通用中文 OCR 识别模型,这个模型是比超轻量级模型有更好的效果。
PaddleOCR 的 github 地址:https://github.com/PaddlePaddle/PaddleOCR
接下来简要介绍一下飞桨在其他视觉任务上的套件。首先看一下图像分割套件,PaddleSeg。和 PaddleDetection 一样,PaddleSeg 从数据算法的支持,包括训练优化等方面其实是非常完备的,包括工业级部署,到一些实际案例等,都提供了很多的支持。通过这个图可以看到和 PaddleDetection 一样,有强大的部署能力。

针对模型压缩飞桨推出了 PaddleSlim 的模型压缩库,它支持模型的裁剪、量化、蒸馏、搜索等多个方向。其主要特色包括三点:
在百度业务中有大量的使用;
用户自己定义的一些模型可以方便地使用它的工具进行模型压缩,
在一些标准的,像图像分类、目标检测等这些问题上做了一些比较全的验证。

PaddleSeg 的 github 地址:https://github.com/PaddlePaddle/PaddleSeg
PaddleSlim 的 github 地址:https://github.com/PaddlePaddle/PaddleSlim
飞桨模型库的 github 地址:https://github.com/PaddlePaddle/models
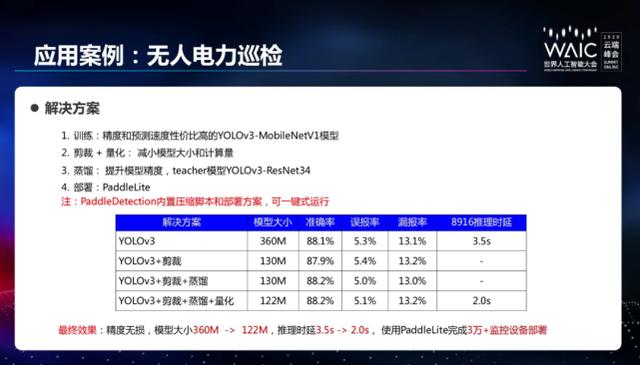
最后,杜宇宁简单介绍了应用案例:无人电力巡检项目。

飞桨零门槛 AI 开发平台 EasyDL
接下来,百度 AI 技术生态部高级产品经理子季和百度 AI 与数据平台部资深研发工程师赵云进行了零门槛 AI 开发平台 EasyDL 的技术实践分享。
随着人工智能技术在各行各业的落地应用,AI 模型的定制开发需求也越来越普遍。一个定制模型的开发,往往涉及由诸多模块组成的复杂机器学习系统,包括从数据采集、数据标注、特征提取、模型训练,到训练资源的管理、流程管理工具、模型效果评估等等,最终还包括预测服务的部署、预测服务监控等。EasyDL 定位为零门槛 AI 开发平台,就是为了解决各行各业在 AI 落地应用中的此类问题。
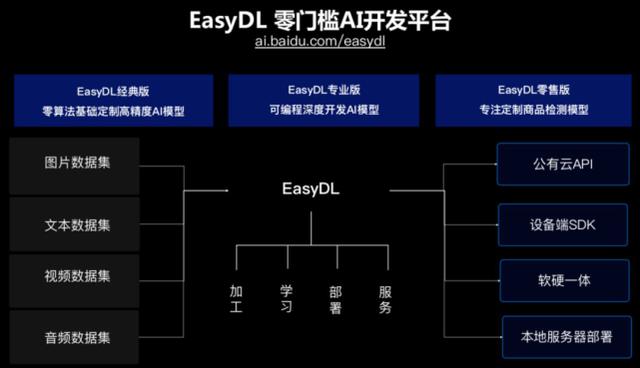
EasyDL 整体思路与产品架构。
上图展示了 EasyDL 的整体思路与产品架构:在「输入部分」,企业开发者能够输入图片、文本、视频、音频各类数据集,通过 EasyDL 平台进行加工、学习、部署和服务之后,即可完成最终所需的 AI 预测服务输出,比如公有云 API 的形式、设备端 SDK 的形式、软硬一体的形式或者本地服务器部署的形式。在这样的大框架里面,EasyDL 把最复杂的模块封装在一个简单的系统操作平台上,让 AI 落地应用的门槛变得更低。
面向不同 AI 基础的用户、不同行业的用户,EasyDL 也推出了不同的版本。算法基础较为薄弱的 AI 初学者,可使用 EasyDL 经典版,其定位为零算法基础定制高精度 AI 模型,能够实现快速落地应用;专业的算法工程师、开发者,可使用 EasyDL 专业版,专业版是一个可编程、深度开发 AI 模型的开发平台,能满足进一步调参需求;同时为了解决行业里面的难题,EasyDL 也推出了行业版本,比如目前的 EasyDL 零售版。
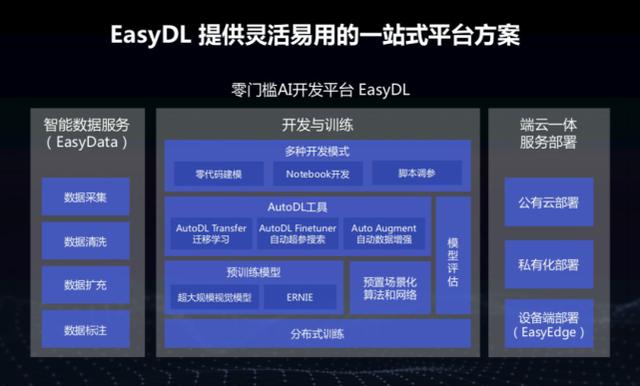
EasyDL 全景图。
EasyDL 是一个端到端一站式 AI 开发平台,集成了核心智能数据服务、开发与训练、端云一体服务部署三大模块。
1、核心智能数据服务
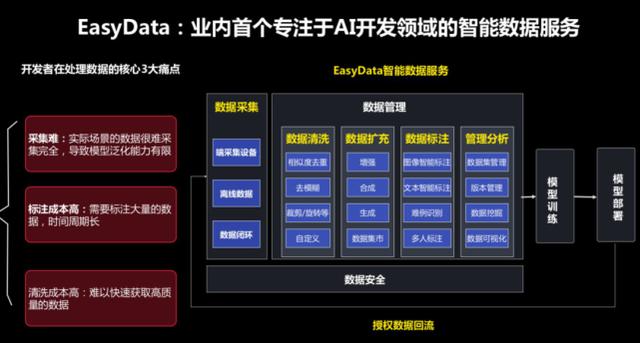
智能数据服务 EasyData 是百度在 2020 年 4 月份正式推出的业界首个专注于 AI 开发领域智能数据的服务,包含数据采集、数据清洗、数据标注和数据扩充几项功能模块。
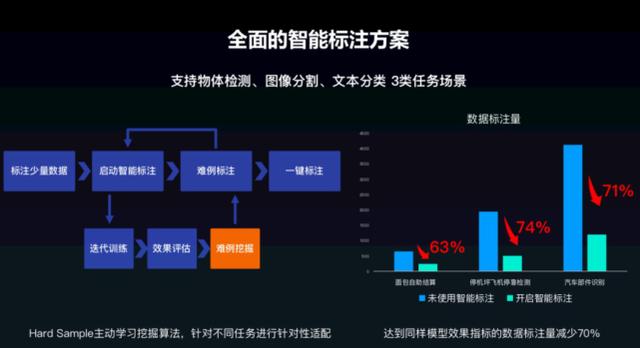
智能标注是该服务中的一项重点功能,目前支持物体检测、图像分割、文本分类这三类常见任务的场景。整体流程为:标注少量数据、启动智能标注、难例标注,完成一键标注。此外,EasyDL 利用百度独创的 Hard Sample 主动学习挖掘算法,可以针对不同任务进行针对性适配,从而解决检测、分割、文本等多场景的难例挖掘的问题。从效果上看,可使用户在仅标注数据集大概 30% 左右数据量的条件下,即可训练出标注全量数据同等效果的模型。
2、开发与训练模块
开发与训练模块预置了百度自有的超大规模视觉预训练模型和 ERNIE NLP 预训练模型,集成了自动超参搜索、自动数据增强等多种先进训练机制和多种场景化算法和网络,同时提供了丰富的、完善的模型评估方案,并且支持数据闭环和持续训练。
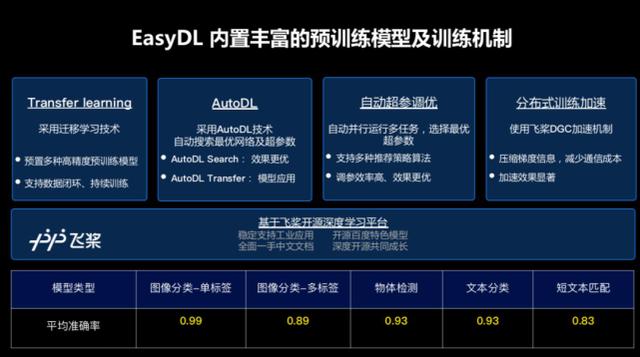
在这个工具的基础之上,EasyDL 也提供了多种灵活的开发方式,如零代码建模、Notebook 开发、脚本调参等开发方式,方便各类开发者基于 EasyDL 快速完成 AI 服务的模型训练和服务获取。
3、端云一体服务部署
目前 EasyDL 整体支持公有云 API、本地服务器部署、设备端 SDK 和软硬一体产品这四种服务部署形态。

实际上,EasyDL 目前已经成为应用和落地最为广泛的 AI 开发平台,覆盖了工业、农业、交通运输、政务、互联网等各行业的落地应用。更多落地应用案例可以在 EasyDL 官网 ai.baidu.com/easydl 找到。
多年来,百度深入布局人工智能技术各领域,开发者也一直是百度极为重视的力量。目前,百度飞桨累积开发者数量已超过 194 万,服务企业数量达到 84000 家,发布模型数量已超过 23 万个。面对正在到来的人工智能全面落地期,百度将持续开放更多 AI 能力,助力企业和开发者进行更加便捷高效的人工智能开发。