
架构组成
HBase采用Master/Slave架构搭建集群,它隶属于Hadoop生态系统,由一下类型节点组成:HMaster节点、HRegionServer节点、ZooKeeper集群,而在底层,它将数据存储于HDFS中,因而涉及到HDFS的NameNode、DataNode等,总体结构如下:

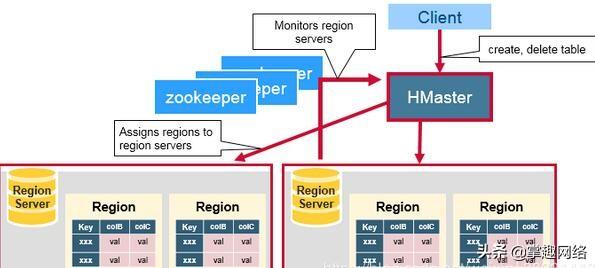
在物理上,HBase由master/slave类型体系结构中的三种服务器组成。RegionServer为读取和写入提供数据。访问数据时,Client直接与Region Server通信。Region的分配,DDL(创建,删除表)操作由HMaster处理。作为HDFS一部分的Zookeeper维护活动集群状态。 Hadoop DataNode存储Region Server正在管理的数据。所有HBase数据都存储在HDFS文件中。Region Server与HDFS数据节点并置,从而为Region Server提供的数据实现数据局部性。除了Region在Split的时候,Hbase写入不是本地的,但是在Hbase在完成compaction之后 HBase数据是基于Local写入的。NameNode维护构成文件的所有物理数据块的元数据信息。

山东掌趣网络科技
Regions
HBase表按RowKey范围水平划分为“Region”。一个Region包含表中该Region的开始键和结束键之间的所有行。将Region分配给群集中称为“Region Server”的节点,这些Region Server为读取和写入提供数据。Region Server可以服务大约1,000个区域。

山东掌趣网络科技
HBase HMaster
区Region分配,DDL(创建,删除表)操作由HBase Master处理。
HBase Master主要负责:
Coordinating the region servers
- Assigning regions on startup , re-assigning regions for recovery or load balancing
- Monitoring all RegionServer instances in the cluster (listens for notifications from zookeeper)
Admin functions
- Interface for creating, deleting, updating tables
山东掌趣网络科技
ZooKeeper
ZooKeeper为HBase集群提供协调服务,它管理着HMaster和HRegionServer的状态(available/alive等),并且会在它们宕机时通知给HMaster,从而HMaster可以实现HMaster之间的failover,或对宕机的HRegionServer中的HRegion集合的修复(将它们分配给其他的HRegionServer)。ZooKeeper集群本身使用一致性协议(PAXOS协议)保证每个节点状态的一致性。

山东掌趣网络科技
Zookeeper用于协调分布式系统成员的共享状态信息。Region Server和Active的HMaster通过与ZooKeeper的会话连接。 ZooKeeper通过心跳维护临时节点以进行活动会话。

山东掌趣网络科技
每个RegionServer都会创建一个临时节点。 HMaster监视这些节点以发现可用的Region Server,并且还监视这些节点的服务器故障。 HMasters试图创建一个临时节点。 Zookeeper确定第一个Master,并使用它来确保只有一个Master处于Active状态。活动的HMaster将心跳发送到Zookeeper,非活动的HMaster侦听活动的HMaster故障的通知。 如果Region Server或Active的HMaster无法发送心跳,则会话过期,并删除相应的临时节点。更新的侦听器将被通知已删除的节点。Active的HMaster侦听Region Sever,并在发生故障时恢复Region Server。非活动HMaster侦听活动的HMaster故障,如果Active的HMaster发生故障,则非活动的HMaster会变为活动状态。
HBase首先读取或写入
有一个称为META表的特殊HBase目录表,该表保存集群中Region的位置。 ZooKeeper存储META表的位置信息。
这是客户端第一次读取或写入HBase时发生的情况:
1、客户端从ZooKeeper获取托管META表的Region服务器。
2、客户端将查询.META。服务器以获取与要访问的行键相对应的区域服务器。客户端将该信息与META表位置一起缓存。
3、它将从相应的区域服务器获取行。
为了将来读取,客户端使用缓存来检索META位置和先前读取的行键。随着时间的流逝,它不需要查询META表,除非由于区域移动导致遗漏;然后它将重新查询并更新缓存。

山东掌趣网络科技
META表
hbase:meta表存储了所有用户HRegion的位置信息,它的RowKey是:tableName,regionStartKey,regionId,replicaId等,它只有info列族,这个列族包含三个列,他们分别是:
info:regioninfo:regionId,tableName,startKey,endKey,offline,split,replicaId;
info:server:HRegionServer对应的server:port;
info:serverstartcode:HRegionServer的启动时间戳。

山东掌趣网络科技
HRegion Server
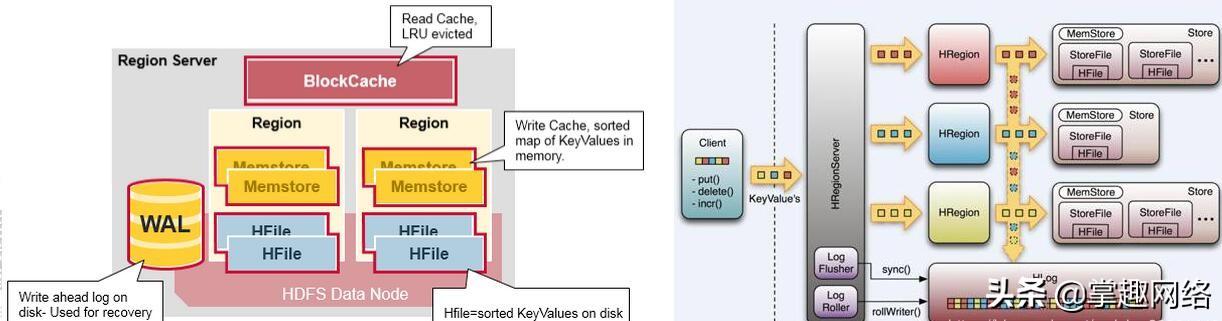
Region Server在HDFS数据节点上运行,并具有以下组件:
WAL: 预写日志是分布式文件系统上的文件。 WAL用于存储尚未持久存储的新数据。发生故障时用于恢复。
BlockCache:是读取缓存。它将经常读取的数据存储在内存中。满时将逐出最近最少使用的数据。
MemStore:是写缓存。它存储尚未写入磁盘的新数据。在写入磁盘之前先对其进行排序。每个区域的每个列族都有一个MemStore。
HRegion:一个Table可以有一个或多个Region,他们可以在一个相同的HRegionServer上,也可以分布在不同的HRegionServer上,一个HRegionServer可以有多个HRegion,他们分别属于不同的Table。HRegion由多个Store(HStore)构成,每个HStore对应了一个Table在这个HRegion中的一个Column Family,即每个Column Family就是一个集中的存储单元,因而最好将具有相近IO特性的Column存储在一个Column Family,以实现高效读取(数据局部性原理,可以提高缓存的命中率)。HStore是HBase中存储的核心,它实现了读写HDFS功能,一个HStore由一个MemStore 和0个或多个StoreFile组成
MemStore(In Memory Sorted Buffer),所有数据的写在完成WAL日志写后,会 写入MemStore中,由MemStore根据一定的算法将数据Flush到地层HDFS文件中(HFile),通常每个HRegion中的每个 Column Family有一个自己的MemStore。
HFile在HFile中的数据是按RowKey、Column Family、Column排序,对相同的Cell(即这三个值都一样),则按timestamp倒序排列。
山东掌趣网络科技
当客户端发起一个Put请求时,首先它从hbase:meta表中查出该Put数据最终需要去的HRegionServer。然后客户端将Put请求发送给相应的HRegionServer,在HRegionServer中它首先会将该Put操作写入WAL日志文件中(Flush到磁盘中)。

山东掌趣网络科技
写完WAL日志文件后,HRegionServer根据Put中的TableName和RowKey找到对应的HRegion,并根据Column Family找到对应的HStore,并将Put写入到该HStore的MemStore中。此时写成功,并返回通知客户端。MemStore是一个In Memory Sorted Buffer,在每个HStore中都有一个MemStore,即它是一个HRegion的一个Column Family对应一个实例。它的排列顺序以RowKey、Column Family、Column的顺序以及Timestamp的倒序,如下所示:

山东掌趣网络科技
每一次Put/Delete请求都是先写入到MemStore中,当MemStore满后会Flush成一个新的StoreFile(底层实现是HFile),即一个HStore(Column Family)可以有0个或多个StoreFile(HFile)。有以下三种情况可以触发MemStore的Flush动作,需要注意的是MemStore的最小Flush单元是HRegion而不是单个MemStore。
当一个HRegion中的所有MemStore的大小总和超过了
hbase.hregion.memstore.flush.size的大小,默认128MB。此时当前的HRegion中所有的MemStore会Flush到HDFS中。
当全局MemStore的大小超过了
hbase.regionserver.global.memstore.upperLimit的大小,默认40%的内存使用量。此时当前HRegionServer中所有HRegion中的MemStore都会Flush到HDFS中,Flush顺序是MemStore大小的倒序,直到总体的MemStore使用量低于
hbase.regionserver.global.memstore.lowerLimit,默认38%的内存使用量。
当前HRegionServer中WAL的大小超过了
hbase.regionserver.hlog.blocksize *
hbase.regionserver.max.logs的数量,当前HRegionServer中所有HRegion中的MemStore都会Flush到HDFS中,Flush使用时间顺序,最早的MemStore先Flush直到WAL的数量少于
hbase.regionserver.hlog.blocksize *
hbase.regionserver.max.logs
在MemStore Flush过程中,还会在尾部追加一些meta数据,其中就包括Flush时最大的WAL sequence值,以告诉HBase这个StoreFile写入的最新数据的序列,那么在Recover时就直到从哪里开始。在HRegion启动时,这个sequence会被读取,并取最大的作为下一次更新时的起始sequence。

山东掌趣网络科技
HFile里面的每个KeyValue对就是一个简单的byte数组。但是这个by
te数组里面包含了很多项,并且有固定的结构。我们来看看里面的具体结构:

山东掌趣网络科技
开始是两个固定长度的数值,分别表示Key的长度和Value的长度。紧接着是Key,开始是固定长度的数值,表示RowKey的长度,紧接着是 RowKey,然后是固定长度的数值,表示Family的长度,然后是Family,接着是Qualifier,然后是两个固定长度的数值,表示Time Stamp和Key Type(Put/Delete)。Value部分没有这么复杂的结构,就是纯粹的二进制数据了。
HBase读实现
通过上文的描述,我们知道在HBase写时,相同Cell(
RowKey/ColumnFamily/Column相同)并不保证在一起,甚至删除一个Cell也只是写入一个新的Cell,它含有Delete标记,而不一定将一个Cell真正删除了,因而这就引起了一个问题,如何实现读的问题?要解决这个问题,我们先来分析一下相同的Cell可能存在的位置:首先对新写入的Cell,它会存在于MemStore中;然后对之前已经Flush到HDFS中的Cell,它会存在于某个或某些StoreFile(HFile)中;最后,对刚读取过的Cell,它可能存在于BlockCache中。既然相同的Cell可能存储在三个地方,在读取的时候只需要扫瞄这三个地方,然后将结果合并即可(Merge Read),在HBase中扫瞄的顺序依次是:BlockCache、MemStore、StoreFile(HFile)。其中StoreFile的扫瞄先会使用Bloom Filter过滤那些不可能符合条件的HFile,然后使用Block Index快速定位Cell,并将其加载到BlockCache中,然后从BlockCache中读取。我们知道一个HStore可能存在多个StoreFile(HFile),此时需要扫瞄多个HFile,如果HFile过多又是会引起性能问题。

山东掌趣网络科技
MemStore每次Flush会创建新的HFile,而过多的HFile会引起读的性能问题,那么如何解决这个问题呢?HBase采用Compaction机制来解决这个问题在HBase中Compaction分为两种:Minor Compaction和Major Compaction。
Minor Compaction是指选取一些小的、相邻的StoreFile将他们合并成一个更大的StoreFile,在这个过程中不会处理已经Deleted或Expired的Cell。一次Minor Compaction的结果是更少并且更大的StoreFile。
Major Compaction是指将所有的StoreFile合并成一个StoreFile,在这个过程中,标记为Deleted的Cell会被删除,而那些已经Expired的Cell会被丢弃,那些已经超过最多版本数的Cell会被丢弃。一次Major Compaction的结果是一个HStore只有一个StoreFile存在。Major Compaction可以手动或自动触发,然而由于它会引起很多的IO操作而引起性能问题,因而它一般会被安排在周末、凌晨等集群比较闲的时间。

山东掌趣网络科技
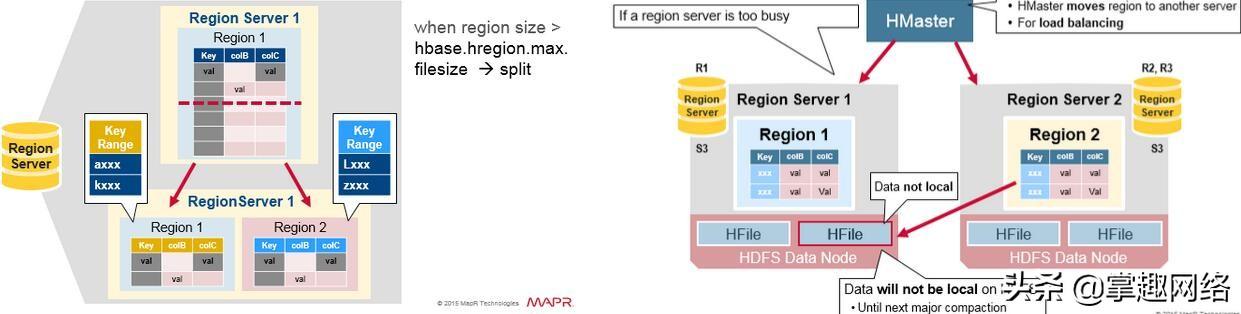
HRegion Split
最初,一个Table只有一个HRegion,随着数据写入增加,如果一个HRegion到达一定的大小,就需要Split成两个HRegion,这个大小由
hbase.hregion.max.filesize指定,默认为10GB。当split时,两个新的HRegion会在同一个HRegionServer中创建,它们各自包含父HRegion一半的数据,当Split完成后,父HRegion会下线,而新的两个子HRegion会向HMaster注册上线,处于负载均衡的考虑,这两个新的HRegion可能会被HMaster分配到其他的HRegionServer中。
山东掌趣网络科技
在HRegion Split后,两个新的HRegion最初会和之前的父HRegion在相同的HRegionServer上,出于负载均衡的考虑,HMaster可能会将其中的一个甚至两个重新分配的其他的HRegionServer中,此时会引起有些HRegionServer处理的数据在其他节点上,直到下一次Major Compaction将数据从远端的节点移动到本地节点。
HRegionServer Recovery
当一台HRegionServer宕机时,由于它不再发送Heartbeat给ZooKeeper而被监测到,此时ZooKeeper会通知HMaster,HMaster会检测到哪台HRegionServer宕机,它将宕机的HRegionServer中的HRegion重新分配给其他的HRegionServer,同时HMaster会把宕机的HRegionServer相关的WAL拆分分配给相应的HRegionServer(将拆分出的WAL文件写入对应的目的HRegionServer的WAL目录中,并并写入对应的DataNode中),从而这些HRegionServer可以Replay分到的WAL来重建MemStore。

山东掌趣网络科技
山东掌趣网络科技















