针对客户(业务员、用户)输入的信息、上传的文件(后期),实现自动审核过滤,以达成尽可能少的人工参与!
通过程序中对文本对象进行检测,有效降低内容违规风险。但是不能彻底解决内容违规。
我们会将大部分的违规内容,通过前端js、后台服务自动处理,并返回处理结果;小部分违规内容,由人工参与处理,具体逻辑根据不同的业务场景提供不同的功能支持。
后期如需对图片、音视频文件进行内容检测,需要对接第三方接口实现。
内容审核自动化(半)
内容检测
内容检测方案
以上第三方支持直接针对网站内容进行检测判断。
1,违规词汇检测审核。
2,第三方接口检测审核。
3,人工审核。
1,第三方接口检测审核。
2,人工审核。
反垃圾算法
核心是通过前端结合后端程序,对信息进行违规检测,将大部分的违规信息,通过应用程序自动判定处理,并返回对应的处理结果。有效降低内容违规风险。
针对程序没有检测到的违规信息,通过人工审核的策略,下架或删除遗漏的违规信息。
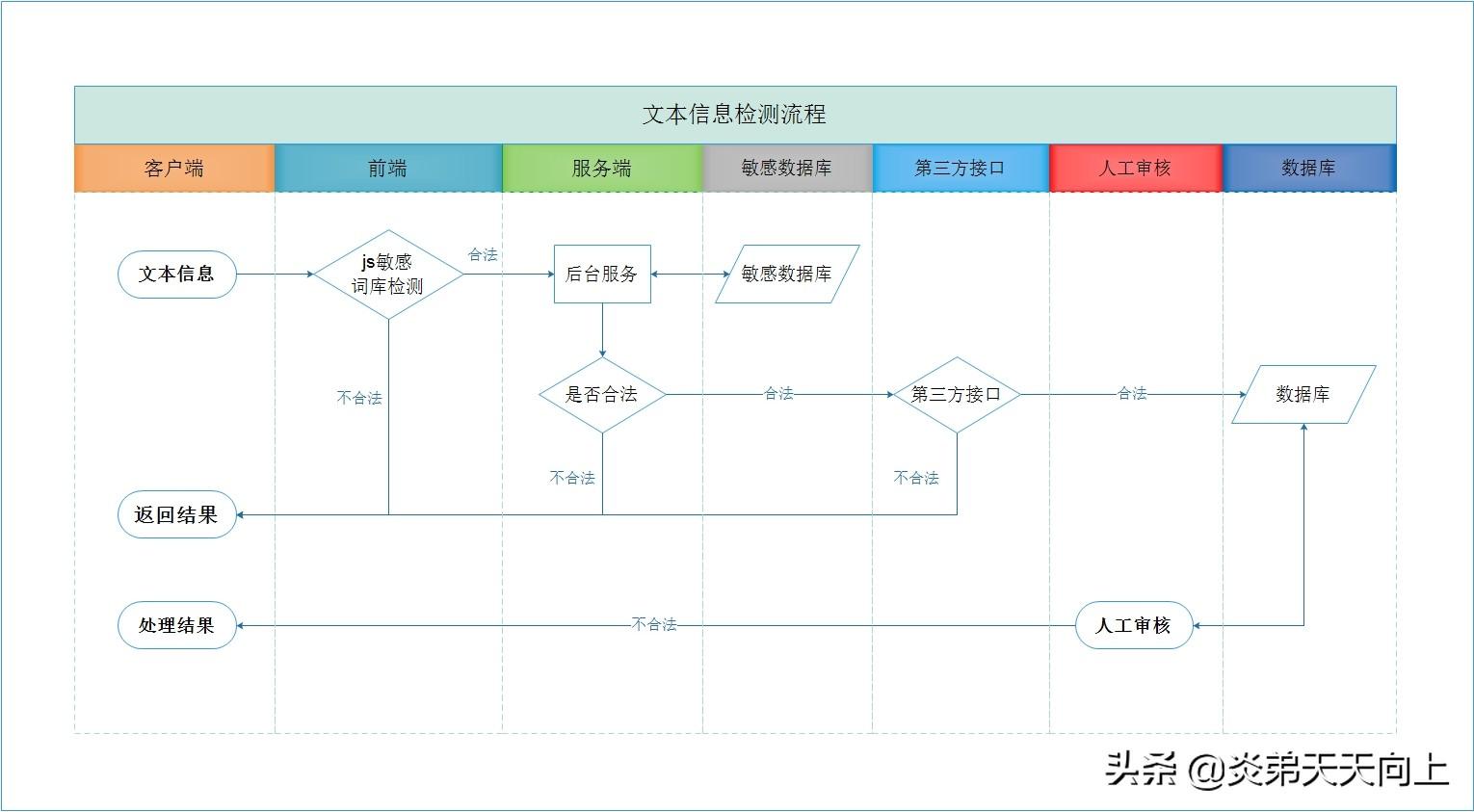
文本信息检测处理流程
信息检测流程概述:
1,用户输入文本信息,前端通过敏感词库进行JS校验判断,如果不合法,返回结果;合法,执行下一步;
2,服务端,通过敏感数据库对信息进行检测判断,如果不合法,返回结果;合法,执行下一步;
3,调用第三方接口,检测判断,如果不合法,返回结果;合法,保存到数据库中。【此步骤,前期可省略】
4,人工审核,功能包括:巡查审核、信息审核、禁言等操作。作为保全方案!(主要针对广告、刷屏、添加重复数据的情况)
注意:【词库大,需要注意检测方法执行时长,不影响业务的情况下,需控制在50ms以内;时长根据业务容错而定】
以上方案,对于文本内容检测程序会增加程序响应时间(尽量控制在10ms以内),从而会进一步影响整个应用的吞吐量。
前期:代码实现,优化方法执行逻辑,缩短程序执行时间。(测试方法执行时间)
后期可考虑应用集群。
针对违规信息处理方案,根据不同的场景,可考虑不同的落地设计方案:
1,弹框提示
2,接口信息提示
3,信息提示
4,频繁发送,限制
5,信息下架
6,账号锁定或禁用
前期主要针对文本信息进行检测处理。
后期如需对图片、音视频文件进行内容检测,需要对接第三方接口实现。
检测方法,可参考--DFA算法/AC自动机,可有效缩短检测方法时间。
大致是将敏感数据构建成树的结构,完成搜索命中,然后进行处理。
多模式匹配算法:在主串中查找多个模式串。(字典树+kmp算法+失配指针)
(原理todo)
针对客户输入的信息,采用js检测,判断是否会命中敏感词。
服务端:通过已有的敏感词数据表,查询判断。如果敏感词较多,可使用redis进行缓存处理。
数据库:敏感词数据表(后期可后台维护新增)
场景1:添加数据
结合人工审核,信息下架处理,网站不再显示。
对接第三方,todo