跑批通常指代的是我们应用程序针对某一批数据进行特定的处理
在金融业务中一般跑批的场景有分户日结、账务计提、欠款批扣、不良资产处理等等
具体举一个例子
客户在我司进行借款,并约定每月 10 号码还款,在客户自主授权银行卡签约后
在每月 10 号(通常是凌晨)我们会在客户签约的银行卡上进行扣款
然后可能会有一个客户、两个客户、三个客户、四个客户、好多个客户都需要进行扣款,所以这一“批” 所有数据,我们都要统一地进行扣款处理,即为我们“跑批”的意思
跑批任务是要通过定时地去处理这些数据,不能因为其中一条数据出现异常从而导致整批数据无法继续进行操作,所以它必须是健壮的;并且针对于异常数据我们后续可以进行补偿处理,所以它必须是可靠的;并且通常跑批任务要处理的数据量较大,我们不能让它处理的时间过于久,所以我们必须考虑其性能处理;总结一下,我们跑批处理的应用程序需要做到的要求如下
一些未接触过跑批业务的同学,可能会犯一些错误·
// 调用数据库查询需跑批数据
List<BizApplyDo> bizApplyDoList = this.listGetBizApply(businessDate);
// for 循环处理数据
for(BizApplyDo ba : bizApplyDoList) {
// 业务处理逻辑.. 省略
// 查询账户数据
List<BizAccountDo> bizAccountDoList = this.listGetBizAccount(ba.getbizApplyId());
for (BizAccountDo bic : bizAccountDoList){
// 账户处理逻辑.. 省略
}
... // 后续还会嵌套 for 循环
}
我们知道 Spring 中间的事务可分为编程性事务和声明式事务,具体二者的区别我们就不展开说明了
在开发过程中,就有可能同学不管三七二一,爽了就行,直接 @Trancational 覆盖住我们整个方法
一旦方法处理时间过久,这个大事务就给我们的代码埋下了雷
常用的有 Spring 定时框架、Quartz、elastic-job、xxl-job 等,框架无谓好坏,适合自己业务的才是最佳的
可针对自己业务进行技术选型,我们常使用的技术为 xxl-job,针对于我们上文中所说到的不同的跑批任务设置的时间不合理,我们即可利用 xxljob 的子任务特性进行嵌套的任务处理,在保费代扣任务完成后紧接着进行本息代扣任务
这一点其实没有什么好展开的,在对跑批任务进行开发的时候,一定要记住分片处理
一次性加载所有数据到内存里,无疑是自掘坟墓
那么,如何优雅分片呢?
这时候小张同学举手了:分片我会呀,比如像这种扣款的都是以时间维度来的,我直接 select * from t_repay_plan where repay_time <= "2022-04-10" limit 0,1000
那么,现在我们找个数据来看下这种深度分片的性能如何
我在数据库中插入了大概两百万条数据,把制造数据的过程也分享给你们
// 1、创建表
CREATE TABLE `t_repay_plan` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`repay_time` datetime DEFAULT NULL COMMENT '还款时间',
`str1` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3099998 DEFAULT CHARSET=utf8mb4
// 2、创建存储过程
delimiter $$
create procedure insert_repayPlan()
begin
declare n int default 1;
while n< 3000000
do
insert into t_repay_plan(repay_time,str1) values(concat( CONCAT(FLOOR(2015 + (RAND() * 1)),'-',LPAD(FLOOR(10 + (RAND() * 2)),2,0),'-',LPAD(FLOOR(1 + (RAND() * 25)),2,0))),n);
set n = n+1;
end while;
end
// 3、执行存储过程
call insert_repayPlan();
随着逐渐的数据偏移,数据耗时逐渐增加。因为这种深度分页是将数据全部查询出来,并且抛弃掉,效果自然不是那么尽如人意
其实我们分片还有一种方法,那就是利用到我们的 id 来进行分页处理(当然是你的 id 是需要保证业务增长,并且结合具体的业务场景来进行分析)
我们同样来试一下怎么利用 id ,进行分片的耗时情况

我们可以看到效果很明显,利用 id 进行分片,效果是优于我们的这个还款时间字段的
当然关于跑批过程中 「覆盖索引的使用、尽量不去 select * 等、批量进行插入」 等 sql 常见点不和大家一一展开说明了
我们再写一个简单的反例
// 调用数据库查询需跑批数据
List<BizApplyDo> bizApplyDoList = this.listGetBizApply(businessDate);
// for 循环处理数据
for(BizApplyDo ba : bizApplyDoList) {
// 查询账户数据
BizAccountDo bizAccountDo = this.getBizAccount(ba.getbizApplyId());
// 账户处理逻辑.. 省略
// 查询扣款人数据
CustDo custDo = this.getCust(ba.getUserId);
// 扣款人处理逻辑.. 省略
}
我们可以这样进行改造(伪代码、忽略判空处理)
// 调用数据库查询需跑批数据
List<BizApplyDo> bizApplyDoList = this.listGetBizApply(businessDate);
// 构建业务申请编号集合
List<String> bizApplyIdList = bizApplyDoList.parallelStream().map(BizApplyDo::getbizApplyId()).collect(Collectors.toList());
// 批量进行账户查询
List<BizAccountDo> bizAccountDoList = this.listGetBizAccount(bizApplyIdList);
// 构建账户 Map
Map<String, BizAccountDo> accountMap = bizAccountDoList.parallelStream().collect(Collectors.toMap(BizAccountDo::getBizApplyId(), Function.identity()))
// 扣款人数据同样处理
for(BizApplyDo ba : bizApplyDoList) {
account = accountMap.get(ba.getbizApplyId())
// 账户处理逻辑.. 省略
}
尽可能减少 for 循环的嵌套,减少数据库频繁连接和销毁
一旦我们使用了@Trancation进行管理事务,那么就要求组内开发人员在开发过程中需要瞪大眼睛去注意事务的控制范围
因为 @Trancation 是在第一个 sql 方法执行的时候就开启了事务,在方法未结束之前都不会进行提交,有些同学接手改造这个方法的时候,没有注意到这个方法是被@Trancation覆盖,那么在这个方法里加入一些RPC的远程调用、消息发送、文件写入、缓存更新等操作
1、这些操作自身是无法回滚的,这就会导致数据的不一致。可能RPC调用成功了,但是本地事务回滚了,可是PRC调用无法回滚了。
2、在事务中有远程调用,就会拉长整个事务。那么久会导致本事务的数据库连接一直被占用,那么如果类似操作过多,就会导致数据库连接池耗尽或者单个链接超时
我曾经就见过一个方法,经过多人之手后,从而因为大事务导致数据库连接被强行销毁的悲剧
所以「我们可以有选择性的去使用编程性事务去处理」我们的业务逻辑,让接手的同学可以明确看到什么时候开启了事务,什么时候提交了事务,也尽可能将我们的事务粒度的范围缩小
分享此条优化之前,先大致介绍一下我们的业务背景
保费代扣的跑批任务中,我们是会借助流程编排这个框架,去异步发起我们的代扣,你可以理解为一笔代扣申请就是一个异步线程,代扣的数据全部在流程编排中进行传递
在我们进行优化完毕的时候,准备在UAT环境进行优化测试的时候,发现仅20w条保费数据,处理时间就非常的不尽入人意
监控系统环境,发现系统频频在进行 GC,我的第一反应,不会是发生内存泄露了吧,在准备 dump 文件的时候
我意外的发现,大部分申请都是卡在了对外扣费的这个节点,经过日志观察,发现下游接口给的响应时间过久,甚至部分出现了超时情况
那么这个GC就合理了,由于我们的代扣申请生成的速度非常快,并且是异步的线程调度,线程还未死亡,一直在尝试对外请求扣费,就导致所有的数据都堆在内存里,就导致了频繁GC
在和下游接口方进行核实之后,的确针对于该接口没有进行限流处理(太坑了)
优化的思路也很简单了,在业务可接受的情况,我们采取的是去发送 mq 请求后,就挂起流程编排(该线程会死亡),然后让消费者进行处理调用成功后唤醒流程进行后续处理即可,当然使用固定的线程池直接调外也是可以的,目的都是防止过多的线程处于 RUNNING,从而导致内存一直的堆积
还有一种对外调用的万金油处理方式,就是在业务可接受的情况下,采取一种 fast success 方式,举个例子,在进行保费扣费的时候,我们调用支付公司的接口之前,直接将我们的扣费状态更改为扣费中,然后直接挂起我们的业务,然后用定时任务去查证我们的扣费结果,收到扣费结果后,在继续我们扣费后的操作
针对于生产上面的机器我们通常不会是单机部署,那么如何可以尽可能去压榨我们服务器的资源呢
那就是利用xxl-job的 「分片广播」 和 「动态分片」 功能
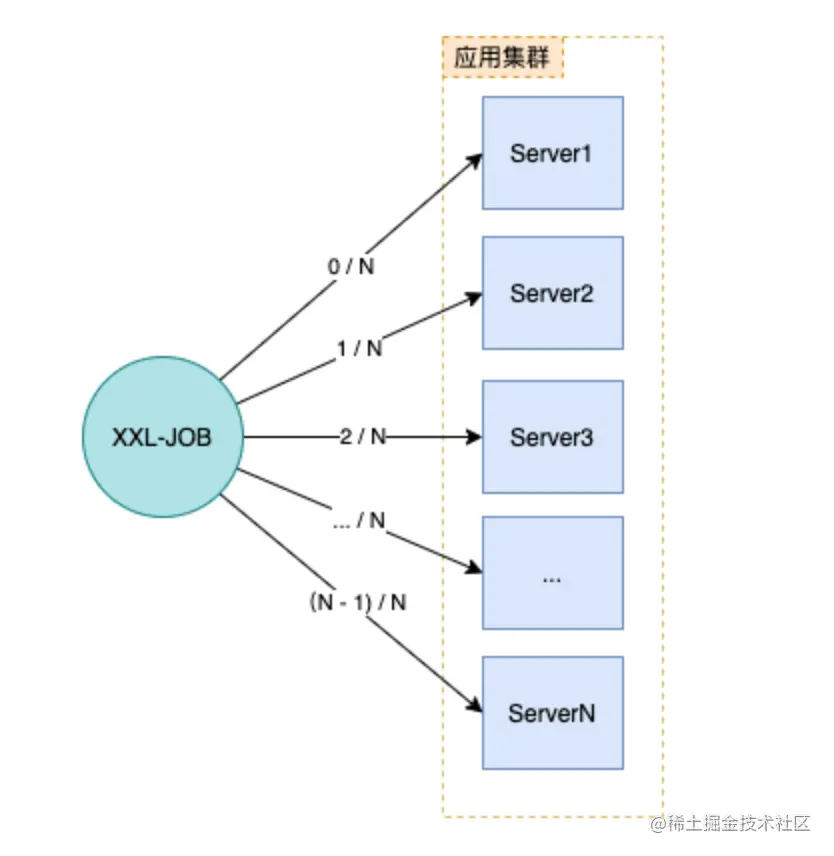
执行器集群部署时,任务路由策略选择”分片广播”情况下,一次任务调度将会广播触发对应集群中所有执行器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
“分片广播” 以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度。
“分片广播” 和普通任务开发流程一致,不同之处在于可以获取分片参数,获取分片参数进行分片业务处理。
// 可参考Sample示例执行器中的示例任务"ShardingJobHandler"了解试用
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
具体举个例子,比如我们做分户日结的时候,可以根据商户的编号对机器进行取模处理,然后每台机器只执行某些特定商户的数据
那么这边留一个问题给大家:如果发生数据倾斜,你会如何处理,即某个商户的数据量特别大, 导致这台机器执行的任务非常的重,要是你,你会如何处理这种场景?
今天针对于大数据量的跑批,在项目中实践思考就到此结束了。
文章介绍了我们常见跑批任务中可能出现的风险和比较常用通用的一些优化思路进行了分享
关于线程池和缓存的运用我未在文章中提及,这两点也对我们的高效跑批具有极大的帮助,小伙伴们可以加以利用
当然文章只是引起大家针对于跑批任务的思考,更多的优化还需结合任务具体情况和项目本身环境进行处理