出品|搜狐科技
作者|郑松毅
谁能想到,被誉为“最大原创段子手孵化地”的弱智吧,最近竟摇身一变成了——最佳中文AI训练语料库?
由此受到启发,是否并不是训练AI的优质数据不够用,而是还有更多宝藏数据资源值得深挖?
近日,由中科院深圳先进技术研究院、中科院自动化研究所,滑铁卢大学等众多高校组成的联合研究团队,为推动中文AI的发展,前往各大中文社交媒体和论坛取材,经过严格筛选和细致处理,构建了一份高质量中文指令微调数据集“COIG-CQIA”,用于AI训练。

论文称,这份数据集中的数据来源于知乎、小红书、豆瓣、弱智吧等社交平台,旨在构建一个多样化的指令微调数据集,以提升大模型对中文指令的理解和响应能力。
在AI训练之余,研究人员也好奇地测验了下不同平台的数据质量,获得下图跑分。
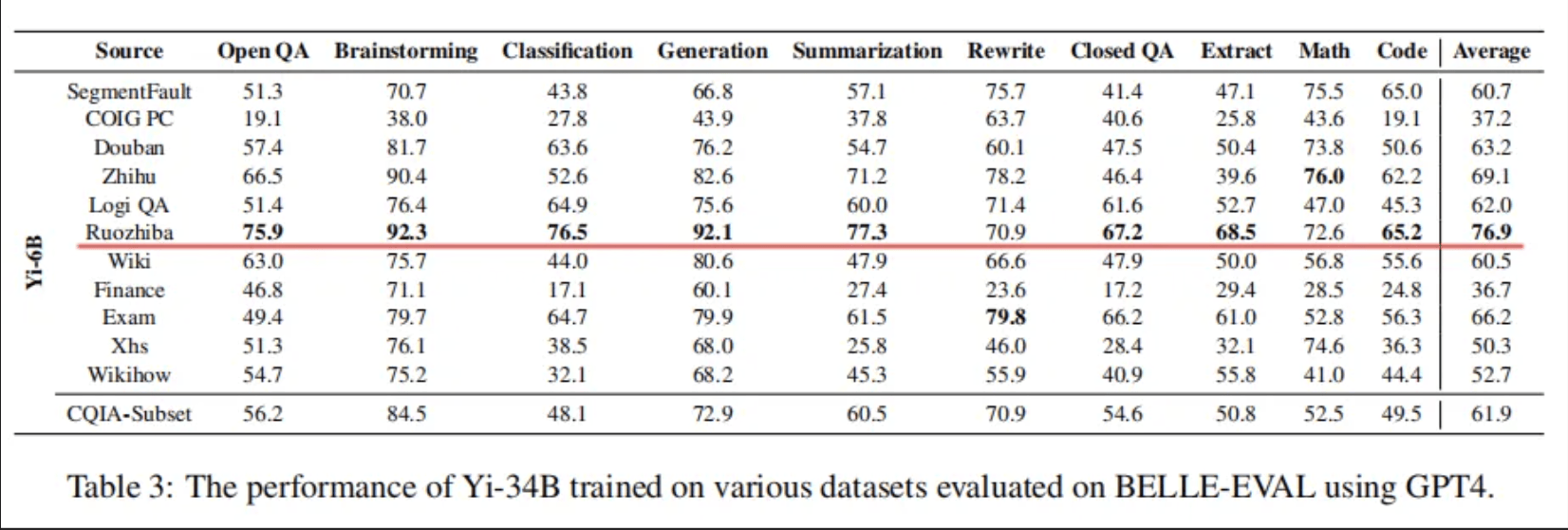
其中,“Ruozhiba(弱智吧)”数据集在头脑风暴、分类、生成、总结等八个评测项目中夺得最高分,且总评分稳居第一。
看到这,网友们调侃道,“人工智能取代一切,但无法取代弱智。”
“弱智吧”的数据究竟有啥特别之处?什么样的数据对AI来说是优质的?带着这些问题,搜狐科技对话了清华大学自动化系教授、中国人工智能学会常务理事陶建华。
什么样的数据是优质的?
“弱智吧”还真不是顾名思义,它是百度贴吧上的一个子版块。在弱智吧,吧友是段子手、是诗人、是哲学家,唯独不是弱智。
话不多说,先展示一些吧友整理的经典语录供大家细品:
“为什么要感到伤心,难道你的生活还不够可笑吗?”
“被门夹过的核桃,还能补脑吗?”
“每天吃一粒感冒药,还会感冒吗?”
“我买了一斤藕,为什么半斤都是空的?”
“变形金刚买保险是买车险还是人险?”
“去自首的路上被抓了还算自首吗?”
“每个人都在赚钱,那么谁在亏钱?”
可以看出,在弱智吧,深层次的幽默和思想常以无厘头的风格藏在字里行间。话说回来,把这样“奇葩”的数据喂给AI模型有什么作用呢?
陶建华向搜狐科技介绍,“弱智吧中的帖子有不少脑筋急转弯和双关语,包含更复杂的逻辑,并且表达简洁干练,数据较为干净,属于一种高质量数据。用这样的数据训练出的大模型,在部分场景的确会让人感觉逻辑推理能力更强。”
但他强调,“大模型的训练数据更应追求平衡性,弱智吧这样的数据的确会对逻辑推理能力有一定帮助,但在解决实际问题时,往往需要更广泛的覆盖不同场景和类型的数据。”
相信很多人会问,究竟什么样的数据属于优质数据,是大家追求的?
陶建华认为,优质的数据应具备以下3个特点:多样性、干净合理、及时性。
多样性主要指的是数据应该具有多种不同的来源,涉及不同领域、主题、风格的内容,覆盖面要广,甚至包括不同语言,并且不同领域的数据数量要均衡。这种多样性使得大模型能够更全面地理解和处理各种场景和任务。
干净合理是指数据要干净、无噪声,数据应该尽量减少错误与不合理的内容,确保数据的正确性。
及时性是指数据可以随着时间推移持续扩充与更新。
他表示,在一些专业领域,往往也需要一些带有对齐语义标签的数据。带有标签的数据能够明确指示数据样本与其对应属性或类别之间的关系。这种对应关系对于监督学习等机器学习算法至关重要,以便进行准确的预测和分类。
此外,在多模态大模型构建过程中,大规模也经常需要具有语义对齐的多模态数据,对模型的构建也是非常重要的。这些数据能够使大模型学习到不同模态(如图片和文字)之间的映射关系,从而能够实现“以图生文”、“以文生图”等性能。
2026年数据预言是真是假?
数据,是人工智能赖以发展的核心资源。如何解决“数据瓶颈”是未来一段时期我们即将面临或已经面临的挑战。
据业内人士分析,GPT-3于2020年推出,使用了3000亿的token;去年上线的GPT-4使用了12万亿token;如果遵循当前的增长轨迹,GPT-5可能会需要 60 万亿到 100 万亿的token。
根据去年 Epoch AI人工智能预测组织的一项研究,AI公司可能在 2026 年前耗尽高质量文本训练数据,而低质量文本和图像数据的枯竭时间可能介于 2030 年至 2060 年之间。这意味着,“数据瓶颈”或成为制约AI发展的关键因素。
陶建华则认为,随着数据针对不同领域、主题、类别等方面的覆盖逐渐丰富,高质量数据的增长趋势的确会在一定程度上放缓,但在数字化快速发展的时代,每天都会生成大量的数据,尤其是会不断产生新的应用领域(包括专业领域),高质量数据依然会继续增长。
“当然在算力受限的情况下,数据量大,不一定代表模型就能处理的过来,因为算力的制约,导致大模型的参数规模无法迅速扩大,必然也会影响对更大规模数据的处理能力。”
陶建华介绍,在某些领域,数据还会存在稀疏不够的情况,有时采用“合成数据”也是一种弥补数据短缺的方法,即利用仿真技术或者AIGC技术生成数据,来扩充数据的规模,在很多情况下,也能取得很好的模型训练和应用效果。