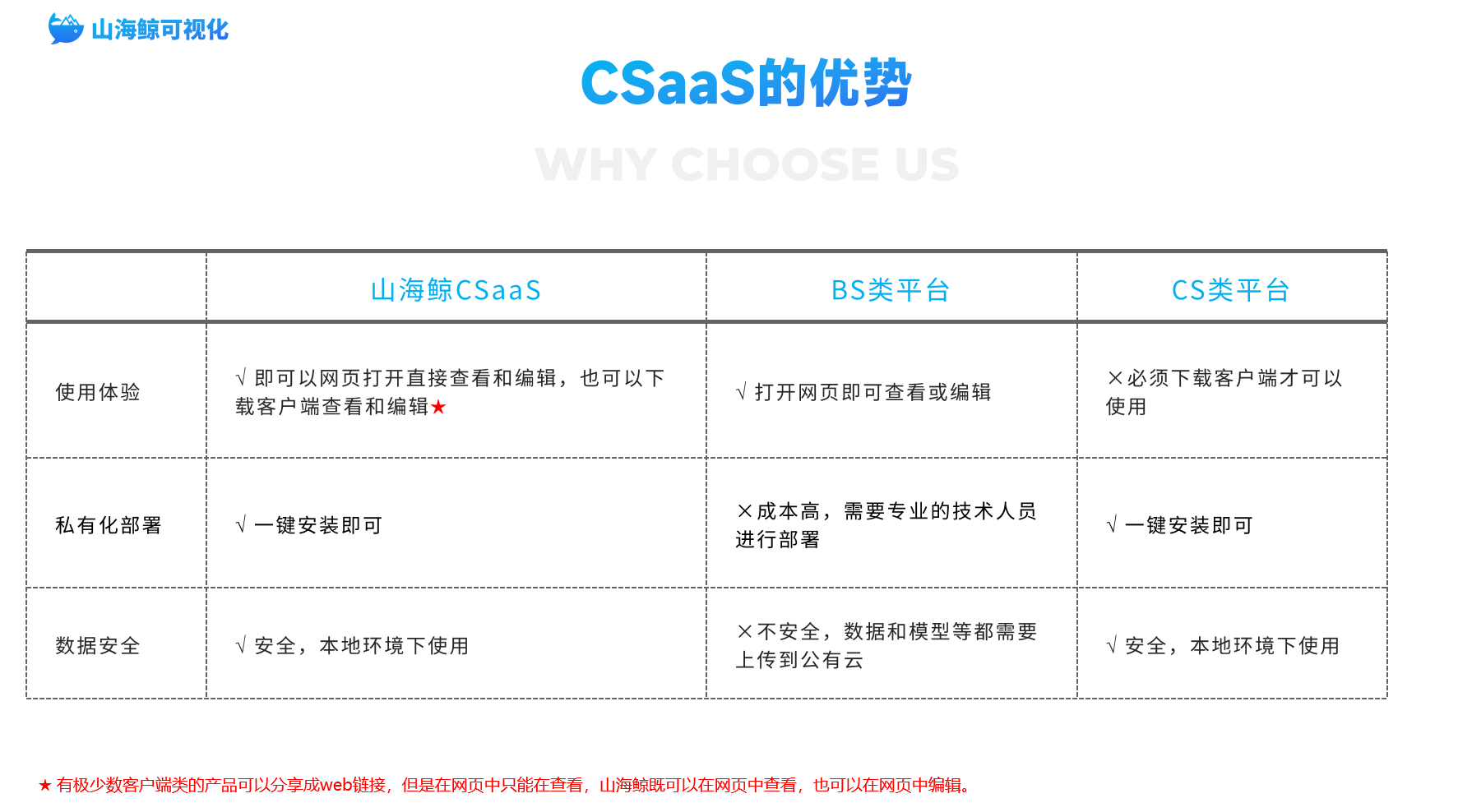
大家好!在本手册中,您将了解软件架构这一广阔而复杂的领域。
当我第一次开始编码之旅时,我发现这是一个既令人困惑又令人生畏的领域。所以我会尽量避免你的困惑。
在这本手册中,我将尝试为您提供一个简单、浅显、易于理解的软件架构介绍。
我们将讨论软件世界中的架构是什么,您应该了解的一些主要概念,以及当今使用最广泛的一些架构模式。
对于每个主题,我都会给出一个简短的理论介绍。然后我将分享一些代码示例,让您更清楚地了解它们是如何工作的。让我们开始吧!
目录
根据这个来源:
系统的软件架构代表与整个系统结构和行为相关的设计决策。
这很笼统,对吧?绝对地。在研究软件架构时,这正是让我非常困惑的地方。这是一个包含很多内容的主题,该术语用于谈论许多不同的事物。
我可以说的最简单的方式是,软件架构是指您在创建软件的过程中如何组织东西。而这里的“东西”可以指:
这是很多不同的选择和可能性。更复杂一点的是,在这 5 个部门中,可以组合不同的模式。这意味着,我可以拥有一个使用 REST 或 GraphQL 的单体 API,一个托管在本地或云上的基于微服务的应用程序,等等。
为了更好地解释这个混乱,首先我们要解释一些基本的通用概念。然后我们将介绍其中的一些部门,解释当今用于构建应用程序的最常见的架构模式或选择。
需要了解的重要软件架构概念什么是客户端-服务器模型?
客户端-服务器是一种在资源或服务提供者(服务器)与服务或资源请求者(客户端)之间构建应用程序任务或工作负载的模型。
简而言之,客户端是请求某种信息或执行动作的应用程序,而服务器是根据客户端所做的事情发送信息或执行动作的程序。
客户端通常由运行在 Web 或移动应用程序上的前端应用程序表示(尽管也存在其他平台,并且后端应用程序也可以充当客户端)。服务器通常是后端应用程序。
为了举例说明这一点,假设您正在进入您最喜欢的社交网络。当您在浏览器上输入 URL 并按 Enter 键时,您的浏览器将充当客户端应用程序并向社交网络服务器发送请求,该服务器通过向您发送网站内容来响应。
现在大多数应用程序都使用客户端-服务器模型。需要记住的最重要的概念是客户端请求服务器执行的资源或服务。
另一个需要了解的重要概念是客户端和服务器是同一系统的一部分,但每个都是独立的应用程序/程序。这意味着它们可以单独开发、托管和执行。
如果你不熟悉前端和后端的区别,这里有一篇很酷的文章来解释它。这是另一篇扩展客户端-服务器概念的文章。
什么是 API?
我们刚刚提到客户端和服务器是相互通信以请求事物和响应事物的实体。这两个部分通常通信的方式是通过 API(应用程序编程接口)。
API 只不过是一组定义的规则,用于确定应用程序如何与另一个应用程序通信。这就像两部分之间的合同,上面写着“如果您发送 A,我将始终响应 B。如果您发送 C,我将始终响应 D……”等等。
有了这组规则,客户端就可以准确地知道完成某项任务需要什么,而服务器也可以准确地知道客户端在必须执行某个操作时需要什么。
API 有多种实现方式。最常用的是 REST、SOAP 和 GraphQl。
关于 API 的通信方式,最常见的是使用 HTTP 协议,并以 JSON 或 XML 格式交换内容。但是其他协议和内容格式是完全可能的。
如果您想扩展此主题,这里有一篇不错的文章供您阅读。
什么是模块化?
当我们谈论软件架构中的“模块化”时,我们指的是把大的东西分成小块的做法。这种分解事物的做法是为了简化大型应用程序或代码库。
模块化具有以下优点:
我知道这听起来有点笼统,但是模块化或细分事物的实践是软件架构的重要组成部分。所以只要把这个概念放在你的脑海里——当我们通过一些例子时,它会变得更加清晰和明显。;)
如果您想了解有关此主题的更多信息,我最近写了一篇关于在 JS中使用模块的文章,您可能会发现它很有用。
您的基础设施是什么样的?
好的,现在让我们来看看好东西。我们将开始讨论组织软件应用程序的多种不同方式,首先是如何组织项目背后的基础设施。
为了让这一切不那么抽象,我们将使用一个名为 Notflix 的假设应用程序。
旁注:请记住,这个例子可能不是最现实的例子,我将假设/强制情况以呈现某些概念。这里的想法是通过示例帮助您理解核心架构概念,而不是执行现实世界的分析。
单体架构
所以 Notflix 将是一个典型的视频流应用程序,用户将能够在其中观看电影、连续剧、纪录片等。用户将能够在网络浏览器、移动应用程序和电视应用程序中使用该应用程序。
我们应用程序中包含的主要服务将是身份验证(因此人们可以创建帐户、登录等)、支付(因此人们可以订阅和访问内容......因为你不认为这一切都是免费的,对吧? )当然还有流媒体(这样人们就可以实际观看他们所支付的费用)。
我们的架构的快速草图可能如下所示:

经典的单体架构
在左侧,我们有三个不同的前端应用程序,它们将充当该系统中的客户端。例如,它们可能是使用 React 和 React-native 开发的。
我们有一个服务器,它将接收来自所有三个客户端应用程序的请求,在必要时与数据库通信,并相应地响应每个前端。比方说,后端可以使用 Node 和 Express 开发。
这种架构被称为单体架构,因为有一个服务器应用程序负责系统的所有功能。在我们的例子中,如果用户想要验证、支付我们或观看我们的一部电影,所有的请求都将被发送到同一个服务器应用程序。
单片设计的主要好处是它的简单性。它的功能和所需的设置简单易懂,这就是大多数应用程序以这种方式开始的原因。
微服务架构
事实证明,Notflix 完全摇摆不定。我们刚刚发布了最新一季的“Stranger thugs”,这是一部关于青少年说唱歌手的科幻系列,以及我们的电影“Agent 404”(关于一个秘密特工,他潜入一家模拟高级程序员的公司,但实际上并没有了解代码)正在打破所有记录......
我们每个月都会从世界各地获得数以万计的新用户,这对我们的业务来说非常好,但对于我们的单一应用程序来说却不是那么好。
最近我们一直在经历服务器响应时间的延迟,即使我们已经垂直扩展了服务器(将更多的 RAM 和 GPU 放入其中),可怜的东西似乎无法承受它所承受的负载。
此外,我们一直在为我们的系统开发新功能(例如,一个可以读取用户偏好并推荐适合用户个人资料的电影的推荐工具),我们的代码库开始看起来庞大且使用起来非常复杂。
深入分析这个问题,我们发现占用资源最多的功能是流媒体,而其他服务如身份验证和支付并不代表很大的负载。
为了解决这个问题,我们将实现一个看起来像这样的微服务架构:

我们的第一个微服务实现
因此,如果您不熟悉这一切,您可能会想“微服务到底是什么”,对吧?好吧,我们可以将其定义为将服务器端功能划分为许多只负责一个或几个特定功能的小型服务器的概念。
按照我们的示例,之前我们只有一个服务器负责所有功能(单体架构)。实现微服务后,我们将有一个服务器负责身份验证,另一个负责支付,另一个负责流式传输,最后一个负责推荐。
当用户想要登录时,客户端应用程序将与身份验证服务器通信,当用户想要支付时与支付服务器通信,当用户想要观看时与流媒体服务器通信。
所有这些通信都是通过 API 进行的,就像使用常规的单片服务器(或通过其他通信系统,如Kafka或RabbitMQ)一样。唯一的区别是,现在我们有不同的服务器负责不同的操作,而不是一个单独的服务器来完成所有操作。
这听起来有点复杂,确实如此,但微服务为我们提供了以下好处:
微服务是一种设置和管理更复杂的架构,这就是为什么它只对非常大的项目有意义。大多数项目将作为单体开始,仅在出于性能原因需要时迁移到微服务。
如果您想了解更多关于微服务的信息,这里有一个很好的解释。
什么是前端(BFF)的后端?
实现微服务时出现的一个问题是与前端应用程序的通信变得更加复杂。现在我们有许多服务器负责不同的事情,这意味着前端应用程序需要跟踪这些信息才能知道向谁发出请求。
通常这个问题可以通过在前端应用程序和微服务之间实现一个中间层来解决。这一层会接收所有的前端请求,重定向到对应的微服务,接收微服务响应,然后将响应重定向到对应的前端应用。
BFF 模式的好处是我们获得了微服务架构的好处,而不会使与前端应用程序的通信过于复杂。

我们的 BFF 实施
如果您想了解更多信息,这里有一个解释 BFF 模式的视频。
如何使用负载均衡器和水平扩展
因此,我们的流媒体应用程序以指数级的速度不断增长。我们在全球有数百万用户 24/7 全天候观看我们的电影,而且比我们预期的更快,我们再次开始遇到性能问题。
我们再次发现流媒体服务是压力最大的服务,我们已经尽我们所能垂直扩展了该服务器。将该服务进一步细分为更多的微服务是没有意义的,因此我们决定横向扩展该服务。
之前我们提到垂直扩展意味着向单个服务器/计算机添加更多资源(RAM、磁盘空间、GPU 等)。另一方面,水平扩展意味着设置更多的服务器来执行相同的任务。
我们现在将拥有三个服务器,而不是一个负责流式传输的服务器。然后客户端执行的请求将在这三台服务器之间进行平衡,以便所有服务器都能处理可接受的负载。
这种请求的分配通常由称为负载均衡器的东西执行。负载均衡器充当我们服务器的反向代理,在客户端请求到达服务器之前拦截它们并将该请求重定向到相应的服务器。
虽然典型的客户端-服务器连接可能如下所示:

这是我们之前的
使用负载均衡器,我们可以将客户端请求分发到多个服务器:

这就是我们现在想要的
您应该知道水平扩展也可以用于数据库,因为它可以用于服务器。实现这一点的一种方法是使用源-副本模型,其中一个特定的源 DB 将接收所有写入查询并将其数据沿一个或多个副本 DB 复制。副本数据库将接收并响应所有读取查询。
数据库复制的优点是:
因此,在实现负载均衡器、水平扩展和数据库复制之后,我们的架构可能如下所示:

我们的水平扩展架构
如果您有兴趣了解更多,这里有一个关于负载均衡器的精彩视频解释。
旁注:当我们谈论微服务、负载均衡器和扩展时,我们可能总是在谈论后端应用程序。对于前端应用程序,它们大多总是作为单体开发,尽管还有一个奇怪有趣的东西叫做微前端。
您的基础架构所在的位置
现在我们已经对如何组织应用程序基础架构有了基本的了解,接下来要考虑的是我们将把所有这些东西放在哪里。
正如我们将要看到的,在决定在何处以及如何托管应用程序时主要有三个选项:在本地、在传统服务器提供商上或在云上。
本地托管
内部部署意味着您拥有运行应用程序的硬件。在过去,这曾经是托管应用程序的最传统方式。公司曾经有专门的房间供服务器使用,并且有专门的团队负责硬件的设置和维护。
这个选项的好处是公司可以完全控制硬件。不好的是它需要空间、时间和金钱。
想象一下,如果您想横向扩展某台服务器,那将意味着购买更多设备,对其进行设置,不断对其进行监督,修复任何损坏的东西......如果您以后需要缩减该服务器,那么,通常你'这些东西买了就不能退了
对于大多数公司而言,拥有本地服务器意味着将大量资源用于与公司目标没有直接关系的任务。

我们如何想象我们在 Notflix 的服务器机房

结局如何
本地服务器仍然有意义的一种情况是在处理非常微妙或私密的信息时。例如,想想运行发电厂的软件或私人银行信息。其中许多组织决定使用本地服务器作为完全控制其软件和硬件的一种方式。
传统服务器提供商
对于大多数公司来说,更舒适的选择是传统的服务器提供商。这些公司拥有自己的服务器,他们只是租用它们。你决定你的项目需要什么样的硬件,并按月支付费用(或根据其他条件支付一定的费用)。
此选项的优点在于您不再需要担心任何与硬件相关的事情。供应商会照顾它,作为一家软件公司,您只担心您的主要目标,即软件。
另一个很酷的事情是扩大或缩小规模很容易且无风险。如果您需要更多硬件,则需要付费。如果您不再需要它,您只需停止付款。
众所周知的服务器提供商的一个例子是托管程序。
托管在云端
如果您已经接触过技术一段时间,您可能不止一次听说过“云”这个词。起初,这听起来很抽象,有点神奇,但实际上它背后的东西只不过是亚马逊、谷歌和微软等公司拥有的巨大数据中心。
在某些时候,这些公司发现他们拥有并非一直在使用的 huuuuuuuuge 计算能力。由于所有这些硬件无论你是否使用它都代表着成本,明智的做法是将计算能力商业化给其他人。
这就是云计算。使用AWS(亚马逊网络服务)、谷歌云或 MicrosoftAzure等不同的服务,我们能够在这些公司的数据中心托管我们的应用程序,并利用所有这些计算能力。

“云”实际上可能是什么样子
在了解云服务时,重要的是要注意有许多不同的方式可以使用它们:
传统的
第一种方法是以与使用传统服务器提供商类似的方式使用它们。您可以选择所需的硬件类型并按月准确支付费用。
松紧带
第二种方法是利用大多数提供商提供的“弹性”计算。“弹性”意味着您的应用程序的硬件容量将根据您的应用程序的使用情况自动增长或缩小。
例如,您可以从具有 8gb 内存和 500gb 磁盘空间的服务器开始。如果您的服务器开始收到越来越多的请求并且这些容量不再足以提供良好的性能,系统可以自动执行垂直或水平扩展。
令人敬畏的是,您可以预先配置所有这些,而不必再担心它。随着服务器自动扩展和缩减,您只需为消耗的资源付费。
无服务器
使用云计算的另一种方式是使用无服务器架构。
按照这种模式,您将不会拥有一个接收所有请求并响应它们的服务器。相反,您会将单个函数映射到访问点(类似于 API 端点)。
这些函数将在每次收到请求时执行,并执行您为它们编写的任何操作(连接到数据库、执行 CRUD 操作或您可以在常规服务器中执行的任何其他操作)。
无服务器架构的好处在于您忘记了所有关于服务器维护和扩展的事情。您只有在需要时执行的功能,并且每个功能都会根据需要自动放大和缩小。
作为客户,您只需为函数执行的次数和每次执行持续的处理时间支付费用。
如果您想了解更多信息,这里是对无服务器模式的解释。
许多其他服务
您可能会看到弹性和无服务器服务如何为设置软件基础架构提供非常简单方便的替代方案。
除了与服务器相关的服务之外,云提供商还提供大量其他解决方案,例如关系和非关系数据库、文件存储服务、缓存服务、身份验证服务、机器学习和数据处理服务、监控和性能分析等等。一切都托管在云中。
通过Terraform或 AWS Cloud Formation 等工具,我们甚至可以将基础设施设置为代码。这意味着我们可以在几分钟内编写一个脚本,在云上设置服务器、数据库以及我们可能需要的任何其他内容。
从工程的角度来看,这是令人兴奋的,对于我们作为开发人员来说真的很方便。如今的云计算提供了一套非常完整的解决方案,可以轻松地从微小的小项目适应地球上最大的数字产品。这就是为什么现在越来越多的软件项目选择将其基础架构托管在云中的原因。
如前所述,最常用和知名的云提供商是AWS、谷歌云和Azure。尽管还有其他选择,例如IBM、DigitalOcean和Oracle。
这些提供商中的大多数都提供相同类型的服务,尽管它们可能有不同的名称。例如,无服务器函数在 AWS 上称为“lambdas”,在 google 云上称为“云函数”。
要了解的不同文件夹结构
好的,到目前为止,我们已经了解了架构如何指代基础设施组织和托管。现在让我们看看一些代码以及架构如何引用文件夹结构和代码模块化。
一站式文件夹结构
为了说明为什么文件夹结构很重要,让我们构建一个虚拟示例 API。我们将有一个兔子的模拟数据库,API 将对其执行CRUD操作。我们将使用 Node 和 Express 构建它。
这是我们的第一种方法,根本没有文件夹结构。我们的 repo 将由node modules文件夹、App.js、package-lock.json和package.json文件组成。

在我们的 app.js 文件中,我们将拥有我们的微型服务器、我们的模拟数据库和两个端点:
// App.js const express = require('express'); const app = express() const port = 7070 // Mock DB const db = [ { id: 1, name: 'John' }, { id: 2, name: 'Jane' }, { id: 3, name: 'Joe' }, { id: 4, name: 'Jack' }, { id: 5, name: 'Jill' }, { id: 6, name: 'Jak' }, { id: 7, name: 'Jana' }, { id: 8, name: 'Jan' }, { id: 9, name: 'Jas' }, { id: 10, name: 'Jasmine' }, ] /* Routes */ app.get('/rabbits', (req, res) => { res.json(db) }) app.get('/rabbits/:idx', (req, res) => { res.json(db[req.params.idx]) }) app.listen(port, () => console.log(`⚡️[server]: Server is running at http://localhost:${port}`))
如果我们测试端点,我们会发现它们工作得很好:
http://localhost:7070/rabbits # [ # { # "id": 1, # "name": "John" # }, # { # "id": 2, # "name": "Jane" # }, # { # "id": 3, # "name": "Joe" # }, # .... # ] ### http://localhost:7070/rabbits/1 # { # "id": 2, # "name": "Jane" # }
那么这有什么问题呢?没什么,实际上,它工作得很好。只有当代码库变得更大、更复杂并且我们开始向 API 添加新功能时,才会出现问题。
与我们之前在解释单体架构时所讨论的类似,将所有东西放在一个地方一开始很好也很容易。但是当事情开始变得更大更复杂时,这是一种令人困惑且难以遵循的方法。
遵循模块化原则,更好的想法是为我们需要执行的不同职责和操作设置不同的文件夹和文件。
为了更好地说明这一点,让我们向我们的 API 添加新功能,看看我们如何在层架构的帮助下采用模块化方法。
图层文件夹结构
分层架构是将关注点和职责划分到不同的文件夹和文件中,并且只允许在某些文件夹和文件之间进行直接通信。
你的项目应该有多少层,每个层应该有什么名称,以及它应该处理什么动作都是讨论的问题。因此,让我们看看我认为对于我们的示例来说是一个好的方法。
我们的应用程序将有五个不同的层,它们将以这种方式排序:

应用层
您可以看到这种方法更加结构化,并且具有明确的关注点划分。这听起来像是很多样板。但是在设置好之后,这个架构将让我们清楚地知道每个东西在哪里,以及哪些文件夹和文件负责我们的应用程序执行的每个操作。
要记住的重要一点是,在这类架构中,必须遵循层之间定义的通信流才能使其有意义。
这意味着请求首先必须通过第一层,然后是第二层,然后是第三层,依此类推。任何请求都不应该跳过层,因为这会破坏架构的逻辑以及它给我们带来的组织和模块化的好处。

描绘我们的架构的另一种方式
现在让我们看一些代码。使用层架构,我们的文件夹结构可能如下所示:

// App.js const express = require('express'); const rabbitRoutes = require('./rabbits/routes/rabbits.routes') const app = express() const port = 7070 /* Routes */ app.use('/rabbits', rabbitRoutes) app.listen(port, () => console.log(`⚡️[server]: Server is running at http://localhost:${port}`))
// rabbits.routes.js const express = require('express') const bodyParser = require('body-parser') const jsonParser = bodyParser.json() const { listRabbits, getRabbit, editRabbit, addRabbit, deleteRabbit } = require('../controllers/rabbits.controllers') const router = express.Router() router.get('/', listRabbits) router.get('/:id', getRabbit) router.put('/:id', jsonParser, editRabbit) router.post('/', jsonParser, addRabbit) router.delete('/:id', deleteRabbit) module.exports = router
// rabbits.controllers.js const { getAllItems, getItem, editItem, addItem, deleteItem } = require('../models/rabbits.models') const listRabbits = (req, res) => { try { const resp = getAllItems() res.status(200).send(resp) } catch (err) { res.status(500).send(err) } } const getRabbit = (req, res) => { try { const resp = getItem(parseInt(req.params.id)) res.status(200).send(resp) } catch (err) { res.status(500).send(err) } } const editRabbit = (req, res) => { try { const resp = editItem(req.params.id, req.body.item) res.status(200).send(resp) } catch (err) { res.status(500).send(err) } } const addRabbit = (req, res) => { try { console.log( req.body.item ) const resp = addItem(req.body.item) res.status(200).send(resp) } catch (err) { res.status(500).send(err) } } const deleteRabbit = (req, res) => { try { const resp = deleteItem(req.params.idx) res.status(200).send(resp) } catch (err) { res.status(500).send(err) } } module.exports = { listRabbits, getRabbit, editRabbit, addRabbit, deleteRabbit }
// rabbits.models.js const db = require('../../db/db') const getAllItems = () => { try { return db } catch (err) { console.error("getAllItems error", err) } } const getItem = id => { try { return db.filter(item => item.id === id)[0] } catch (err) { console.error("getItem error", err) } } const editItem = (id, item) => { try { const index = db.findIndex(item => item.id === id) db[index] = item return db[index] } catch (err) { console.error("editItem error", err) } } const addItem = item => { try { db.push(item) return db } catch (err) { console.error("addItem error", err) } } const deleteItem = id => { try { const index = db.findIndex(item => item.id === id) db.splice(index, 1) return db return db } catch (err) { console.error("deleteItem error", err) } } module.exports = { getAllItems, getItem, editItem, addItem, deleteItem }
// db.js const db = [ { id: 1, name: 'John' }, { id: 2, name: 'Jane' }, { id: 3, name: 'Joe' }, { id: 4, name: 'Jack' }, { id: 5, name: 'Jill' }, { id: 6, name: 'Jak' }, { id: 7, name: 'Jana' }, { id: 8, name: 'Jan' }, { id: 9, name: 'Jas' }, { id: 10, name: 'Jasmine' }, ] module.exports = db
正如我们所看到的,在这种架构下还有更多的文件夹和文件。但因此,我们的代码库更加结构化和组织清晰。一切都有自己的位置,不同文件之间的通信被明确定义。
这种组织方式极大地方便了新功能的添加、代码修改和错误修复。
一旦您熟悉了文件夹结构并知道在哪里可以找到每个东西,您会发现使用这些越来越小的文件非常方便,而不必滚动浏览一个或两个将所有内容放在一起的大文件。
我还支持为您的应用程序中的每个主要实体(在我们的例子中是兔子)创建一个文件夹。这样可以更清楚地了解每个文件的相关内容。
假设我们现在也想添加新功能来添加/编辑/删除猫和狗。我们将为它们中的每一个创建新文件夹,并且每个文件夹都有自己的路由、控制器和模型文件。我们的想法是分离关注点并将每件事放在自己的位置。
MVC 文件夹结构
MVC 是一种架构模式,代表Model View Controller。我们可以说 MVC 架构就像是层架构的简化,也包含了应用程序的前端 (UI)。
在这种架构下,我们将只有三个主要层:

和以前一样,每一层只与下一层交互,所以我们有一个明确定义的通信流。

描绘我们架构的另一种方式
有许多框架允许您开箱即用地实现 MVC 架构(例如Django或Ruby on RAIls)。要使用 Node 和 Express 做到这一点,我们需要像EJS这样的模板引擎。
如果您不熟悉模板引擎,它们只是一种轻松呈现 html 的方式,同时利用变量、循环、条件等编程特性(非常类似于我们在 React 中使用 JSX 所做的) .
正如我们将在几秒钟内看到的那样,我们将为我们想要呈现的每种页面创建 EJS 文件,并且从每个控制器我们将呈现这些文件作为我们的响应,并将相应的响应传递给它们作为变量。
我们的文件夹结构将如下所示:

// App.js const express = require("express"); var path = require('path'); const rabbitControllers = require("./rabbits/controllers/rabbits.controllers") const app = express() const port = 7070 // Ejs config app.set("view engine", "ejs") app.set('views', path.join(__dirname, './rabbits/views')) /* Controllers */ app.use("/rabbits", rabbitControllers) app.listen(port, () => console.log(`⚡️[server]: Server is running at http://localhost:${port}`))
// rabbits.controllers.js const express = require('express') const bodyParser = require('body-parser') const jsonParser = bodyParser.json() const { getAllItems, getItem, editItem, addItem, deleteItem } = require('../models/rabbits.models') const router = express.Router() router.get('/', (req, res) => { try { const resp = getAllItems() res.render('rabbits', { rabbits: resp }) } catch (err) { res.status(500).send(err) } }) router.get('/:id', (req, res) => { try { const resp = getItem(parseInt(req.params.id)) res.render('rabbit', { rabbit: resp }) } catch (err) { res.status(500).send(err) } }) router.put('/:id', jsonParser, (req, res) => { try { const resp = editItem(req.params.id, req.body.item) res.render('editRabbit', { rabbit: resp }) } catch (err) { res.status(500).send(err) } }) router.post('/', jsonParser, (req, res) => { try { const resp = addItem(req.body.item) res.render('addRabbit', { rabbits: resp }) } catch (err) { res.status(500).send(err) } }) router.delete('/:id', (req, res) => { try { const resp = deleteItem(req.params.idx) res.render('deleteRabbit', { rabbits: resp }) } catch (err) { res.status(500).send(err) } }) module.exports = router
All rabbits
<% rabbits.forEach(function(rabbit) { %>Id: <%= rabbit.id %> Name: <%= rabbit.name %>Rabbit view
Id: <%= rabbit.id %> Name: <%= rabbit.name %>
现在我们可以进入我们的浏览器,点击http://localhost:7070/rabbits并获取:

或者http://localhost:7070/rabbits/2得到:

这就是 MVC!
结论
当我们在软件世界中提到“架构”时,我希望所有这些示例都能帮助您理解我们所谈论的内容。
正如我在开始时所说,这是一个庞大而复杂的主题,通常包含许多不同的事物。
在这里,我们介绍了基础架构模式和系统、托管选项和云提供商,最后介绍了一些您可以在项目中使用的常见且有用的文件夹结构。
我们已经了解了垂直和水平扩展、单体应用程序和微服务、弹性和无服务器云计算……很多东西。但这只是冰山一角!因此,请继续学习和自己进行研究。