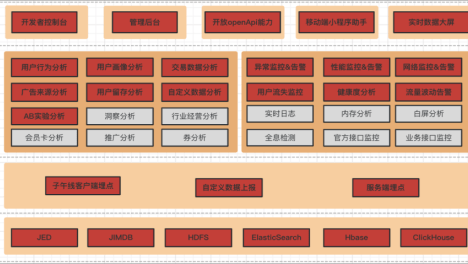
面对大数据挑战而扩展其传统基础设施的企业应考虑使用专门构建的软件产品和服务来构建大数据堆栈架构。
大数据堆栈是一套互补的软件技术,用于管理和分析对于传统技术来说太大或太复杂的数据集。大数据堆栈技术——最常用于分析——是专门为应对数据大小、速度和种类的增长而设计的。大数据产品和服务通常用于管理数据管道中的数据,以提供及时高效的业务洞察。
企业可以考虑几个流行的大数据堆栈,每个堆栈都有一套技术和开源替代方案,无论他们是选择套装堆栈还是构建自己的堆栈,大数据堆栈都已成为现代数据架构的主要组成部分。
大数据通常被描述为规模和复杂性,这带来了独特的挑战,称为三个V:
传统软件技术无法处理的三种情况中的任何一种都被认为是大数据。
要应对大数据的挑战,企业必须将目光投向传统数据处理基础设施以外的领域,求助的一个领域是特殊用途的大数据软件技术,当配合使用时,大数据技术可以克服大数据面临的挑战。
以下6层是成功的大数据堆栈架构的关键:
大数据堆栈架构的第一步是数据收集。数据采集可以从各种内部和外部数据源进行推送或拉取。数据源的一些示例包括交易系统、物联网设备、社交媒体和静态日志文件。
大数据摄取软件处理大型静态数据集、小型实时数据集以及每个数据集的各种数据格式。大的数据集到达得很慢,小的数据集到达得很快。将模式和质量验证推迟到管道中的更远有助于更高的吞吐量。
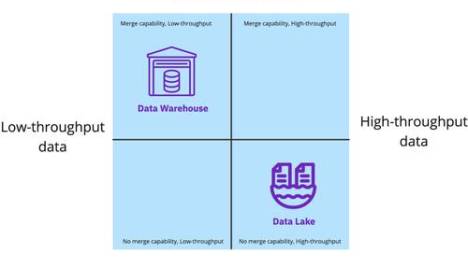
一旦收集,原始数据通常以文件的形式存储在数据湖中,该数据湖针对将数据输入分析管道进行了优化。原生格式存储库既是批量数据的着陆区,也是时间敏感型探索性查询的沙盒。
大数据存储软件存储各种格式的大文件和小文件,通常采用对象存储等分布式文件系统的形式。非瞬时数据可以在较长的保留期内持续存在,并且需要在数据的整个生命周期中使用自动分层的软件。
处理包括准备静态的批量数据集和流动的动态数据以供分析。数据管理可以包括清理、整合、丰富、集成、过滤、聚合和以其他方式准备用于分析的数据。
大数据处理软件运行在大批量数据上,延迟更高,计算更复杂,需要长时间运行的高效率计算。使用分布式处理软件对较小的分区数据片段进行操作可以实现这一点。
大数据处理软件也可以处理高速的流数据,延迟更低,计算相对简单。流数据处理需要通过持续可用的流服务实现有保证的耐用性、订购和交付。
通过软件并行性、就地处理和读取时架构实现批处理和流性能。关键的大数据堆栈策略包括将数据和处理划分为同时执行的小单元,以及在分析存储加载期间最大限度地减少模式验证。
分析数据存储处理或提炼数据以供分析。数据存储的示例包括基于SQL的多维数据仓库、NoSQL技术和具有抽象层的分布式数据存储,该抽象层用于通过接口访问各种数据类型。
大数据分析商店支持多种存储方法和技术,称为多语言持久性。专用单一模型数据库通过优化数据存储和处理特定数据类型来提供性能和可扩展性。基本策略包括数据处理、并行执行和数据分区。
分析检查分析数据存储和原始存储,处于交互环境中的人类用户使用BI工具通过可视化获得洞察力,先进的分析工具处理数据以提取情报,机器学习使用人工智能直接处理数据来自我学习。
大数据分析软件处理从简单的即席查询到复杂的预测分析和机器学习操作的查询。用户范围包括临时分析师、数据科学家和机器。由于数据通常是分散的,就地分析是必不可少的,因此软件应该通过数据交换矩阵的虚拟化向用户呈现数据生态系统的统一视图。
大数据堆栈通常使用工作流技术来管理源数据收集、原始数据存储和数据处理等数据操作,运营还包括将精炼数据移动到分析数据存储,以及将洞察力直接推送到商业智能应用程序,如报告和仪表板。
大数据协调软件可自动化数据管道,从而最大限度地减少延迟并缩短实现价值的时间。工作流软件提供了易于使用的管理界面和架构组件之间的无缝集成。
在选择大数据技术或堆栈之前,企业应量化其当前和未来的数据挑战,了解传统软件的局限性,并注意大数据行业趋势。他们应该定期重新评估自己的评估,因为大数据和技术演变是不断变化的目标。
重要的是要确保技术选择是模块化的和松散耦合的,以允许即插即用策略中的更改,而对其他堆栈软件的影响最小或没有影响。专注于专门为解决体系结构中的独特挑战而设计的软件,而不是多用途软件。
数据驱动型企业了解处理大数据是一项核心能力。专用大数据软件可以应对规模性和复杂性的数据挑战。与传统数据软件一起,大数据堆栈有助于管理数据并提供及时的业务洞察。