这篇博文中提出的建议并不新鲜。事实上许多组织已经投入了数年时间和昂贵的数据工程团队的工作,以慢慢构建这种架构的某个版本。我知道这一点,因为我以前在Uber和LinkedIn做过这样的工程师。我还与数百个组织合作,在开源社区中构建它并朝着类似的目标迈进。
早在 2011 年 LinkedIn 上,我们就开始使用专有数据仓库[1]。随着像“你可能认识的人[2]”这样的数据科学/机器学习应用程序的构建,我们稳步转向Apache Avro上的数据湖[3],Apache Pig可以访问MapReduce作为分析、报告、机器学习和数据应用程序的事实来源。几年后,我们在Uber[4]也面临着同样的挑战,这一次是交易数据和真正的实时业务,天气或交通可以立即影响定价或预计到达时间。我们通过构建 Apache Hudi 构建了一个事务性数据湖,作为 Parquet、Presto、Spark、Flink 和 Hive 上所有数据的入口点,然后它甚至在那个术语被创造出来之前就提供了世界上第一个数据湖仓一体。
如今企业面临的架构挑战不是选择一种正确的格式或计算引擎。主要的格式和引擎可能会随着时间的推移而变化,但这种底层数据架构经受住了时间的考验,因为它在各种用例中具有通用性,允许用户为每个用例选择正确的选择。这篇博文敦促读者主动考虑将这种不可避免的架构作为组织数据战略的基础。
云数据架构被打破
根据我的经验,一个组织的云数据之旅遵循今天熟悉的情节。奖章架构[5]提供了一种很好的方法来概念化这一点,因为数据会针对不同的用例进行转换。典型的“现代数据栈”是通过使用点对点数据集成工具将操作数据复制到云数据仓库上的“青铜”层而诞生的。然后这些数据随后被清理,质量审核,并准备成“银”层。然后,一组批处理 ETL 作业将这些银数据转换为事实、维度和其他模型,最终创建一个“黄金”数据层,为分析和报告提供支持。
组织也在探索新的用例,例如机器学习、数据科学和新兴的 AI/LLM应用程序。这些用例通常需要大量数据,因此团队将添加新的数据源,如事件流(例如点击流事件、GPS 日志等),其规模是现有数据库复制规模的 10-100 倍。
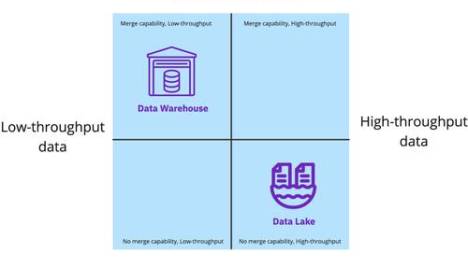
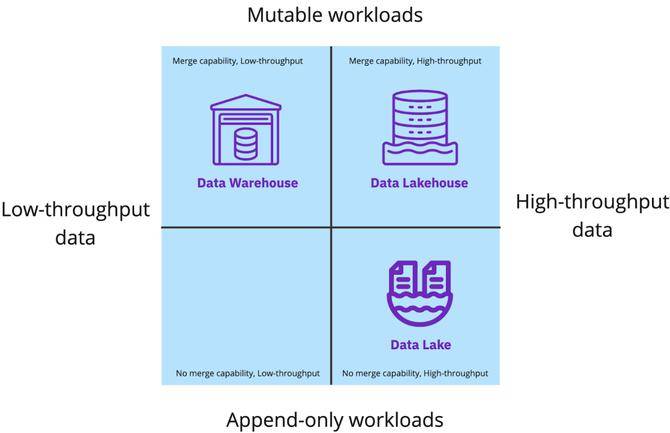
支持高吞吐量事件数据引入了对廉价云存储和数据湖的大规模水平计算可扩展性的需求。但是,虽然数据湖支持仅追加工作负载(无合并),但它几乎不支持处理数据库复制。当涉及到高吞吐量的可变数据流(如 NoSQL 存储、文档存储或新时代的关系数据库)时,当前的数据基础架构系统都没有足够的支持。
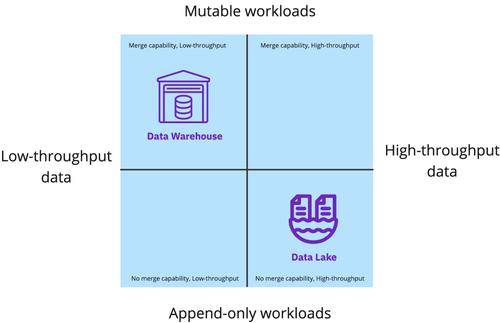
由于每种方法都有特定于某些工作负载类型的优势,因此组织最终会同时维护数据仓库和数据湖。为了在源之间整合数据,它们将定期在数据仓库和数据湖之间复制数据。数据仓库具有快速查询功能,可服务于商业智能 (BI) 和报告用例,而数据湖支持非结构化存储和低成本计算,可服务于数据工程、数据科学和机器学习用例。
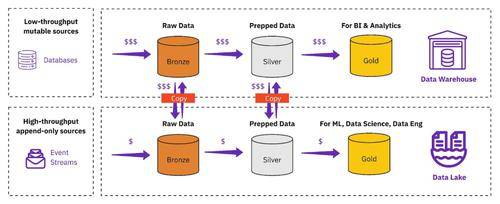
维持如图 2 所示的架构具有挑战性、成本高昂且容易出错。在湖和仓库之间定期复制数据会导致数据过时且不一致。治理成为所有相关人员头疼的问题,因为访问控制在系统之间是分散的,并且必须在数据的多个副本上管理数据删除(GDPR)。更不用说团队对这些不同的管道中的每一个都处于困境,所有权很快就会变得模糊不清。这给组织带来了以下挑战:
o• 供应商锁定:高价值运营数据的真实来源通常是专有数据仓库,这会创建锁定点。
o• 昂贵的引入和数据准备:虽然数据仓库为可变数据提供了合并功能,但对于上游数据库或流数据的快速增量数据引入,它们的性能很差。仓库中针对黄金层计算进行了优化的昂贵高级计算引擎,例如针对星型架构优化的 SQL 引擎,甚至用于青铜层(数据引入)层和银牌(数据准备)层,它们不会增加价值。随着组织规模的扩大,这通常会导致青铜层和银层的成本不断膨胀。
o• 浪费的数据复制:随着新用例的出现,组织会重复他们的工作,在用例中跨冗余的铜牌和银牌层浪费存储和计算资源。例如,引入/复制相同的数据一次用于分析,一次用于数据科学,浪费了工程和云资源。考虑到组织还预配多个环境(如开发、暂存和生产),整个基础架构的复合成本可能令人震惊。此外,GDPR、CCPA 和数据优化等合规性法规的执行成本在通过不同入口点流入的相同数据的多个副本中多次产生。
o• 数据质量差:单个团队经常重新设计基础数据基础架构,以便以零碎的方式摄取、优化和准备数据。由于缺乏资源,这些努力令人沮丧地减慢了投资回报率或完全失败,使整个组织的数据质量面临风险,因为数据质量的强弱取决于最薄弱的数据管道。
数据湖仓一体兴起
在我领导 Uber 数据平台团队期间亲身感受到了这种破碎架构的痛苦。在湖和仓库之间复制数据的大型、缓慢的批处理作业将数据延迟到 24 小时以上,这减慢了我们的整个业务速度。最终随着业务的增长,架构无法有效扩展,我们需要一个更好的解决方案,可以增量处理数据。
2016 年,我和我的团队创建了 Apache Hudi,它最终使我们能够将数据湖的低成本、高吞吐量存储和计算与仓库的合并功能相结合。数据湖仓一体(或我们当时称之为事务性数据湖)诞生了。
数据湖仓一体为云存储中的数据湖添加了事务层,使其具有类似于数据仓库的功能,同时保持了数据湖的可扩展性和成本状况。现在可以使用强大的功能,例如支持使用主键的更新插入和删除的可变数据、ACID 事务、通过数据聚类和小文件处理进行快速读取的优化、表回滚等。
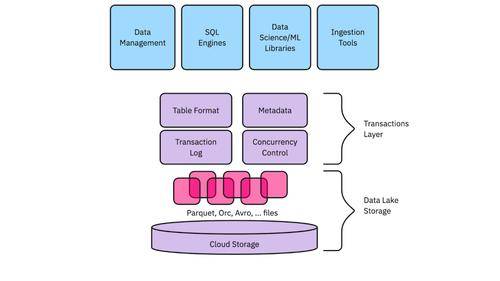
最重要的是它最终使将所有数据存储在一个中心层中成为可能。数据湖仓一体能够存储以前存在于仓库和湖中的所有数据,无需维护多个数据副本。在Uber这意味着我们可以毫不拖延地运行欺诈模型,实现当日向司机付款。我们可以跟踪最新的交通情况,甚至天气模式,以实时更新预计到达时间的预测。
然而实现如此强大的结果不仅仅是选择表格格式或编写作业或 SQL 的练习;它需要一个平衡良好、经过深思熟虑的数据架构模式,并考虑到未来。我将这种架构称为“通用数据湖仓一体”。
通用数据湖仓一体架构
通用数据湖仓一体架构将数据湖仓一体置于数据基础架构的中心提供快速、开放且易于管理的商业智能、数据科学等事实来源。
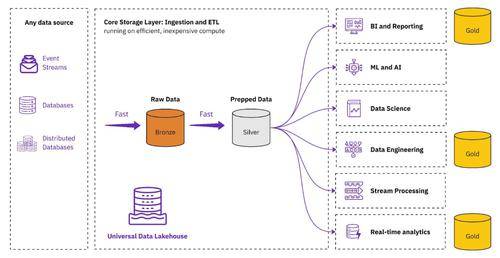
通过采用通用数据湖仓一体架构,组织可以克服以前无法克服的脱节架构的挑战,该架构在湖和仓库之间不断复制数据。数以千计同时使用数据湖和数据仓库的组织可以通过采用此架构获得以下好处:
统一数据
通用数据湖仓一体体系结构使用数据湖仓一体作为组织云帐户中的事实来源,并以开源格式存储数据。此外湖仓一体可以处理复杂的分布式数据库的规模,而这些数据库以前对于数据仓库来说过于繁琐。
确保数据质量
这个通用数据层在数据流中提供了一个方便的入口点,用于执行数据质量检查、对半结构化数据进行架构化以及在数据生产者和使用者之间强制执行任何数据协定。数据质量问题可以在青铜层和银层中得到遏制和纠正,从而确保下游表始终建立在新鲜的高质量数据之上。这种数据流的简化简化了体系结构,通过将工作负载迁移到经济高效的计算来降低成本,并消除了数据删除等重复的合规性工作。
降低成本
由于来自数据库的操作数据和大规模事件数据都在单个青铜层和银层中存储和处理,因此引入和数据准备可以在低成本计算上运行一次。我们已经看到了令人印象深刻的例子,通过将 ELT 工作负载迁移到数据湖仓一体上的此架构,云数据仓库成本节省了数百万美元。以开放格式保存数据,可以在所有三个层中分摊所有数据优化和管理成本,从而为数据平台节省大量成本。
更快的性能
通用数据湖仓一体通过两种方式提高性能。首先它专为可变数据而设计,可快速摄取来自变更数据捕获 (CDC)、流数据和其他来源的更新。其次它打开了一扇门,将工作负载从大型臃肿的批处理转移到增量模型,以提高速度和效率。Uber 通过使用 Hudi 进行增量 ETL,节省了 ~80% 的总体计算成本。它们同时提高了性能、数据质量和可观测性。
让客户自由选择计算引擎
与十年前不同,今天的数据需求并不止于传统的分析和报告。数据科学、机器学习和流数据是财富 500 强公司和初创公司的主流和无处不在。新兴的数据用例(如深度学习)LLMs正在带来各种新的计算引擎,这些引擎具有针对每个工作负载独立优化的卓越性能/体验。预先选择一个仓库或湖引擎的传统做法抛弃了云提供的所有优势;借助通用数据湖仓一体可以轻松地为每个用例按需启动合适的计算引擎。
通用数据湖仓一体架构使数据可以跨所有主要数据仓库和数据湖查询引擎进行访问,并与任何目录集成,这与之前将数据存储与一个计算引擎相结合的方法发生了重大转变。这种架构能够使用最适合每个独特工作的引擎,在BI和报告、机器学习、数据科学和无数更多用例中无缝构建专门的下游“黄金”层。例如 Spark 非常适合数据科学工作负载,而数据仓库则经过传统分析和报告的实战考验。除了技术差异之外,定价和向开源的转变在组织采用计算引擎的过程中起着至关重要的作用。
例如沃尔玛在 Apache Hudi 上构建了他们的湖仓一体,确保他们可以通过以开源格式存储数据来轻松利用新技术。他们使用通用数据湖仓一体架构,使数据使用者能够使用各种技术(包括 Hive 和 Spark、Presto 和 Trino、BigQuery 和 Flink)查询湖仓一体。
夺回数据的所有权
所有真实数据源数据都以开源格式保存在组织云存储桶的青铜层和银层中。
数据的可访问性不是由供应商锁定的不透明第三方系统决定。这种架构能够灵活地在组织的云网络内(而不是在供应商的帐户中)运行数据服务,以加强安全性并支持高度监管的环境。
此外可以自由地使用开放数据服务或购买托管服务来管理数据,从而避免数据服务的锁定点。
简化访问控制
由于数据使用者在湖仓一体中对青铜和白银数据的单个副本进行操作,访问控制变得更加易于管理和实施。数据沿袭已明确定义,团队不再需要跨多个不相交的系统和数据副本管理单独的权限。
为工作负载选择合适的技术
虽然通用数据湖仓一体架构非常有前途,但一些关键技术选择对于在实践中实现其优势至关重要。
当务之急是尽快在银层提供摄取的数据,因为任何延迟现在都会阻碍多个用例。为了实现数据新鲜度和效率的组合,组织应选择非常适合流式处理和增量处理的数据湖仓一体技术。这有助于处理棘手的写入模式,例如在青铜层引入期间的随机写入,以及利用更改流以增量方式更新银牌表,而无需一次又一次地重新处理青铜层。
虽然我可能持有一些偏见,但我和我的团队围绕这些通用数据湖仓一体原则构建了 Apache Hudi。Hudi 经过实战考验,通常被认为是最适合这些工作负载的,同时还提供丰富的开放数据服务层,以保留构建与购买的可选性。此外 Hudi 在数据湖之上解锁了流数据处理模型,以大幅减少运行时间和传统批处理 ETL 作业的成本。我相信在未来的道路上通用数据湖仓一体架构也可以建立在为这些需求提供类似或更好的支持的未来技术之上。
最后 .NETable 是通用数据湖仓一体架构的另一个构建块。它通过简单的目录集成实现了跨主要湖仓一体表格式(Apache Hudi、Apache Iceberg 和 Delta Lake)的互操作性,允许跨计算引擎自由设置数据,并以不同格式构建下游黄金层。这些好处已经得到了沃尔玛[6]等财富 10 强企业的验证。
下一步
在这篇博客中介绍了通用数据湖仓一体作为构建云数据基础设施的新方式。在此过程中我们只是给数百家组织(包括通用电气、TikTok、亚马逊和沃尔玛、迪士尼、Twilio、Robinhood、Zoom 等大型企业)使用数据湖仓一体技术(如 Apache Hudi)构建的数据架构并概述了这些架构。这种方法比许多公司目前维护的混合架构更简单、更快速、成本更低。它实现了存储和计算的真正分离,同时支持在数据中使用同类计算引擎的实用方法。在未来几年我们相信在对数据的需求不断增长的推动下,它只会越来越受欢迎,包括 ML 和 AI 的增长、云成本的上升、复杂性的增加以及对数据团队的需求不断增加。
虽然我坚信“在相同数据上为正确的工作负载提供正确的引擎”原则,但今天以客观和科学的方式做出这一选择并非易事。这是由于缺乏标准化的功能比较和基准测试、缺乏对关键工作负载的共同理解以及其他因素。在本系列的后续博客文章中,我们将分享 Universal Data Lakehouse 如何跨数据传输模式(批处理、CDC 和流式处理)工作,以及它如何以“更好地协同工作”的方式与不同的计算引擎(如 Amazon Redshift、Snowflake、BigQuery 和 Databricks)协同工作。
Onehouse 提供的托管云服务提供交钥匙体验以构建本博客中概述的通用数据湖仓一体架构。像 Apna 这样的用户已经将数据新鲜度从几小时提高到几分钟,并通过削减他们的数据集成工具并用 Onehouse 取代仓库来存储他们的青铜和白银数据,从而显着降低了成本。借助通用数据湖仓一体架构,他们的分析师可以继续使用仓库对湖仓一体中存储的数据进行查询。