Netty 出发点作为一款高性能的 RPC 框架必然涉及到频繁的内存分配销毁操作,如果是在堆上分配内存空间将会触发频繁的GC,JDK 在1.4之后提供的 NIO 也已经提供了直接直接分配堆外内存空间的能力,但是也仅仅是提供了基本的能力,创建、回收相关的功能和效率都很简陋。基于此,在堆外内存使用方面,Netty 自己实现了一套创建、回收堆外内存池的相关功能。基于此我们一起来看一下 Netty 是如何实现内存分配的。
谈到数据保存肯定要说到内存分配,按照存储空间来划分,可以分为 堆内存 和 堆外内存;按照内存区域连贯性来划分可以分为池化内存和非池化内存。这些划分在 Netty 中的实现接口分别是:
按照底层存储空间划分:
按照是否池化划分:
默认使用 PoolDireBuf 类型的内存, 这些内存主要由 PoolArea 管理。另外 Netty 并不是直接对外暴露这些 API,提供了 Unsafe 类作为出口暴露数据分配的相关操作。
小知识:
一般申请内存是检查当前内存哪里有适合当前数据块大小的空闲内存块,如果有就将数据保存在当前内存块中。
那么池化想做的事情是:既然每次来数据都要去找内存地址来存,我就先申请一块内存地址,这一块就是我的专用空间,内存分配、回收我全权管理。
池化解决的问题:
内存碎片:
内碎片就是申请的地址空间大于真正数据使用的内存空间。比如固定申请1M的空间作为某个线程的使用内存,但是该线程每次最多只占用0.5M,那么每次都有0.5M的碎片。如果该空间不被有效回收时间一长必然存在内存空洞。
外碎片是指多个内存空间合并的时候发现不够分配给待使用的空间大小。比如有一个 20byte,13byte 的连续内存空间可以被回收,现在有一个 48byte 的数据块需要存储,而这两个加起来也只有 33byte 的空间,必然不会被使用到。
Netty 采用了 jemalloc 的思想,这是 FreeBSD 实现的一种并发 malloc 的算法。jemalloc 依赖多个 Arena(分配器) 来分配内存,运行中的应用都有固定数量的多个 Arena,默认的数量与处理器的个数有关。系统中有多个 Arena 的原因是由于各个线程进行内存分配时竞争不可避免,这可能会极大的影响内存分配的效率,为了缓解高并发时的线程竞争,Netty 允许使用者创建多个分配器(Arena)来分离锁,提高内存分配效率。
线程首次分配/回收内存时,首先会为其分配一个固定的 Arena。线程选择 Arena 时使用 round-robin 的方式,也就是顺序轮流选取。
每个线程各种保存 Arena 和缓存池信息,这样可以减少竞争并提高访问效率。Arena 将内存分为很多 Chunk 进行管理,Chunk 内部保存 Page,以页为单位申请。申请内存分配时,会将分配的规格分为几类:TINY,SAMLL,NORMAL 和 HUGE,分别对应不同的范围,处理过程也不相同。

tiny 代表了大小在 0-512B 的内存块;
small 代表了大小在 512B-8K 的内存块;
normal 代表了大小在 8K-16M 的内存块;
huge 代表了大于 16M 的内存块。
每个块里面又定义了更细粒度的单位来分配数据:
线程分配内存主要从两个地方分配: PoolThreadCache 和 Arena。其中 PoolThreadCache 线程独享, Arena 为几个线程共享。
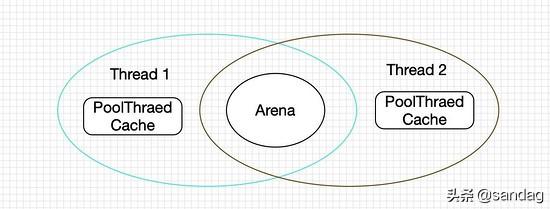
初次申请内存的时候,Netty 会从一整块内存(Chunk)中分出一部分来给用户使用,这部分工作是由 Arena 来完成。而当用户使用完毕释放内存的时候,这些被分出来的内存会按不同规格大小放在 PoolThreadCache 中缓存起来。当下次要申请内存的时候,就会先从 PoolThreadCache 中找。
Chunk、Page、Subpage 和 element 都是 Arena 中的概念,Arena 的工作就是从一整块内存中分出合适大小的内存块。Arena 中最大的内存单位是 Chunk,这是 Netty 向操作系统申请内存的单位。而一块 Chunk(16M) 申请下来之后,内部会被分成 2048 个 Page(8K),当用户向 Netty 申请超过 8K 内存的时候,Netty 会以 Page 的形式分配内存。
Chunk 内部通过伙伴算法管理 Page,具体实现为一棵完全平衡二叉树:
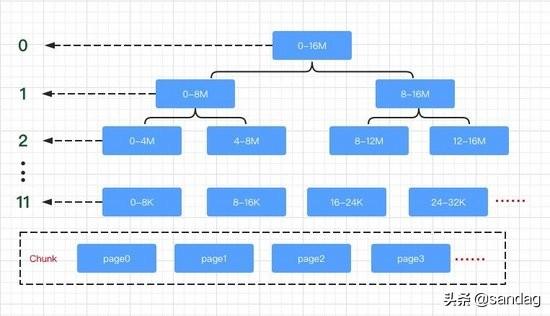
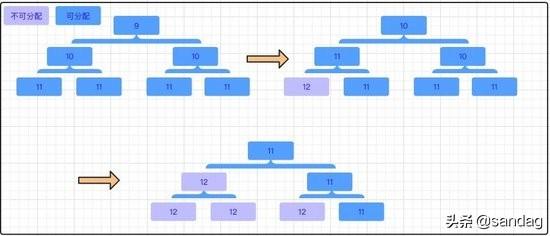
二叉树中所有子节点管理的内存也属于其父节点。当我们要申请大小为 16K 的内存时,我们会从根节点开始不断寻找可用的节点,一直到第 10 层。那么如何判断一个节点是否可用呢?Netty 会在每个节点内部保存一个值,这个值代表这个节点之下的第几层还存在未分配的节点。比如第 9 层的节点的值如果为 9,就代表这个节点本身到下面所有的子节点都未分配;如果第 9 层的节点的值为 10,代表它本身不可被分配,但第 10 层有子节点可以被分配;如果第 9 层的节点的值为 12,此时可分配节点的深度大于了总深度,代表这个节点及其下面的所有子节点都不可被分配。下图描述了分配的过程:
对于小内存(小于4096)的分配还会将 Page 细化成更小的单位 Subpage。Subpage 按大小分有两大类:
PoolSubpage 中直接采用位图管理空闲空间(因为不存在申请 k 个连续的空间),所以申请释放非常简单。
第一次申请小内存空间的时候,需要先申请一个空闲页,然后将该页转成 PoolSubpage,再将该页设为已被占用,最后再把这个 PoolSubpage 存到 PoolSubpage 池中。这样下次就不需要再去申请空闲页了,直接去池中找就好了。Netty 中有 36 种 PoolSubpage,所以用 36 个 PoolSubpage 链表表示 PoolSubpage 池。
因为单个 PoolChunk 只有 16M,这远远不够用,所以会很很多很多 PoolChunk,这些 PoolChunk 组成一个链表,然后用 PoolChunkList 持有这个链表。
我们先从内存分配器 PoolArena 来分析 Netty 中的内存是如何分配的,Area 的工作就是从一整块内存中协调如何分配合适大小的内存给当前数据使用。PoolArena 是 Netty 的内存池实现抽象类,其内部子类为 HeapArena 和 DirectArena,HeapArena 对应堆内存(heap buffer),DirectArena 对应堆外直接内存(direct buffer),两者除了操作的内存(byte[]和ByteBuffer)不同外其余完全一致。
从结构上来看, PoolArena 中主要包含三部分子内存池:
tinySubpagePools;
smallSubpagePools;
一系列的 PoolChunkList。
tinySubpagePools 和 smallSubpagePools 都是 PoolSubpage 的数组,数组长度分别为 32 和 4。
PoolChunkList 则主要是一个容器,其内部可以保存一系列的 PoolChunk 对象,并且,Netty 会根据内存使用率的不同,将 PoolChunkList 分为不同等级的容器。
abstract class PoolArena<T> implements PoolArenaMetric {
enum SizeClass {
Tiny,
Small,
Normal
}
// 该参数指定了tinySubpagePools数组的长度,由于tinySubpagePools每一个元素的内存块差值为16,
// 因而数组长度是512/16,也即这里的512 >>> 4
static final int numTinySubpagePools = 512 >>> 4;
//表示该PoolArena的allocator
final PooledByteBufAllocator parent;
//表示PoolChunk中由Page节点构成的二叉树的最大高度,默认11
private final int maxOrder;
//page的大小,默认8K
final int pageSize;
// 指定了叶节点大小8KB是2的多少次幂,默认为13,该字段的主要作用是,在计算目标内存属于二叉树的
// 第几层的时候,可以借助于其内存大小相对于pageShifts的差值,从而快速计算其所在层数
final int pageShifts;
//默认16MB
final int chunkSize;
// 由于PoolSubpage的大小为8KB=8196,因而该字段的值为
// -8192=>=> 1111 1111 1111 1111 1110 0000 0000 0000
// 这样在判断目标内存是否小于8KB时,只需要将目标内存与该数字进行与操作,只要操作结果等于0,
// 就说明目标内存是小于8KB的,这样就可以判断其是应该首先在tinySubpagePools或smallSubpagePools
// 中进行内存申请
final int subpageOverflowMask;
// 该参数指定了smallSubpagePools数组的长度,默认为4
final int numSmallSubpagePools;
//tinySubpagePools用来分配小于512 byte的Page
private final PoolSubpage<T>[] tinySubpagePools;
//smallSubpagePools用来分配大于等于512 byte且小于pageSize内存的Page
private final PoolSubpage<T>[] smallSubpagePools;
//用来存储用来分配给大于等于pageSize大小内存的PoolChunk
//存储内存利用率50-100%的chunk
private final PoolChunkList<T> q050;
//存储内存利用率25-75%的chunk
private final PoolChunkList<T> q025;
//存储内存利用率1-50%的chunk
private final PoolChunkList<T> q000;
//存储内存利用率0-25%的chunk
private final PoolChunkList<T> qInit;
//存储内存利用率75-100%的chunk
private final PoolChunkList<T> q075;
//存储内存利用率100%的chunk
private final PoolChunkList<T> q100;
//堆内存(heap buffer)
static final class HeapArena extends PoolArena<byte[]> {
}
//堆外直接内存(direct buffer)
static final class DirectArena extends PoolArena<ByteBuffer> {
}
}如上所示,PoolArena 是由多个 PoolChunk 组成的大块内存区域,而每个 PoolChun k则由多个 Page 组成。当需要分配的内存小于 Page 的时候,为了节约内存采用 PoolSubpage 实现小于 Page 大小内存的分配。在PoolArena 中为了保证 PoolChunk 空间的最大利用化,按照 PoolArena 中各 个PoolChunk 已使用的空间大小将其划分为 6 类:
0-25%
1-50%
25-75%
50-100%
75-100%
100%
PoolArena 维护了一个 PoolChunkList 组成的双向链表,每个 PoolChunkList 内部维护了一个 PoolChunk 双向链表。分配内存时,PoolArena 通过在 PoolChunkList 找到一个合适的 PoolChunk,然后从 PoolChunk 中分配一块内存。
下面来看 PoolArena 是如何分配内存的:
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
// 将需要申请的容量格式为 2^N
final int normCapacity = normalizeCapacity(reqCapacity);
// 判断目标容量是否小于8KB,小于8KB则使用tiny或small的方式申请内存
if (isTinyOrSmall(normCapacity)) { // capacity < pageSize
int tableIdx;
PoolSubpage<T>[] table;
boolean tiny = isTiny(normCapacity);
// 判断目标容量是否小于512字节,小于512字节的为tiny类型的
if (tiny) { // < 512
// 将分配区域转移到 tinySubpagePools 中
if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
// 如果无法从当前线程缓存中申请到内存,则尝试从tinySubpagePools中申请,这里tinyIdx()方法
// 就是计算目标内存是在tinySubpagePools数组中的第几号元素中的
tableIdx = tinyIdx(normCapacity);
table = tinySubpagePools;
} else {
// 如果目标内存在512byte~8KB之间,则尝试从smallSubpagePools中申请内存。这里首先从
// 当前线程的缓存中申请small级别的内存,如果申请到了,则直接返回
if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
tableIdx = smallIdx(normCapacity);
table = smallSubpagePools;
}
// 获取目标元素的头结点
final PoolSubpage<T> head = table[tableIdx];
// 这里需要注意的是,由于对head进行了加锁,而在同步代码块中判断了s != head,
// 也就是说PoolSubpage链表中是存在未使用的PoolSubpage的,因为如果该节点已经用完了,
// 其是会被移除当前链表的。也就是说只要s != head,那么这里的allocate()方法
// 就一定能够申请到所需要的内存块
synchronized (head) {
// s != head就证明当前PoolSubpage链表中存在可用的PoolSubpage,并且一定能够申请到内存,
// 因为已经耗尽的PoolSubpage是会从链表中移除的
final PoolSubpage<T> s = head.next;
// 如果此时 subpage 已经被分配过内存了执行下文,如果只是初始化过,则跳过该分支
if (s != head) {
// 从PoolSubpage中申请内存
assert s.doNotDestroy && s.elemSize == normCapacity;
// 通过申请的内存对ByteBuf进行初始化
long handle = s.allocate();
assert handle >= 0;
// 初始化 PoolByteBuf 说明其位置被分配到该区域,但此时尚未分配内存
s.chunk.initBufWithSubpage(buf, handle, reqCapacity);
// 对tiny类型的申请数进行更新
if (tiny) {
allocationsTiny.increment();
} else {
allocationsSmall.increment();
}
return;
}
}
// 走到这里,说明目标PoolSubpage链表中无法申请到目标内存块,因而就尝试从PoolChunk中申请
allocateNormal(buf, reqCapacity, normCapacity);
return;
}
// 走到这里说明目标内存是大于8KB的,那么就判断目标内存是否大于16M,如果大于16M,
// 则不使用内存池对其进行管理,如果小于16M,则到PoolChunkList中进行内存申请
if (normCapacity <= chunkSize) {
// 小于16M,首先到当前线程的缓存中申请,如果申请到了则直接返回,如果没有申请到,
// 则到PoolChunkList中进行申请
if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
allocateNormal(buf, reqCapacity, normCapacity);
} else {
// 对于大于16M的内存,Netty不会对其进行维护,而是直接申请,然后返回给用户使用
allocateHuge(buf, reqCapacity);
}
}所有内存分配的 size 都会经过 normalizeCapacity() 进行处理,申请的容量总是会被格式为 2^N。主要规则如下:
PoolArena 提供了两种方式进行内存分配:
默认先尝试从 poolThreadCache 中分配内存,PoolThreadCache 利用 ThreadLocal 的特性,消除了多线程竞争,提高内存分配效率;
首次分配时,poolThreadCache 中并没有可用内存进行分配,当上一次分配的内存使用完并释放时,会将其加入到 poolThreadCache 中,提供该线程下次申请时使用。
如果是分配小内存,则尝试从 tinySubpagePools 或 smallSubpagePools 中分配内存,如果没有合适 subpage,则采用方法 allocateNormal 分配内存。
如果分配一个 page 以上的内存,直接采用方法 allocateNormal() 分配内存, allocateNormal() 则会将申请动作交由 PoolChunkList 进行。
private synchronized void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
//如果在对应的PoolChunkList能申请到内存,则返回
if (q050.allocate(buf, reqCapacity, normCapacity) || q025.allocate(buf, reqCapacity, normCapacity) ||
q000.allocate(buf, reqCapacity, normCapacity) || qInit.allocate(buf, reqCapacity, normCapacity) ||
q075.allocate(buf, reqCapacity, normCapacity)) {
++allocationsNormal;
return;
}
// Add a new chunk.
PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize);
long handle = c.allocate(normCapacity);
++allocationsNormal;
assert handle > 0;
c.initBuf(buf, handle, reqCapacity);
qInit.add(c);
}首先将申请动作按照 q050->q025->q000->qInit->q075 的顺序依次交由各个 PoolChunkList 进行处理,如果在对应的 PoolChunkList 中申请到了内存,则直接返回。
如果申请不到,那么直接创建一个新的 PoolChunk,然后在该 PoolChunk 中申请目标内存,最后将该 PoolChunk 添加到 qInit 中。
上面说过 Chunk 是 Netty 向操作系统申请内存块的最大单位,每个 Chunk 是16M,PoolChunk 内部通过 memoryMap 数组维护了一颗完全平衡二叉树作为管理底层内存分布及回收的标记位,所有的子节点管理的内存也属于其父节点。
关于 PoolChunk 内部如何维护完全平衡二叉树就不在这里展开,大家有兴趣可以自行看源码。
对于内存的释放,PoolArena 主要是分为两种情况,即池化和非池化,如果是非池化,则会直接销毁目标内存块,如果是池化的,则会将其添加到当前线程的缓存中。如下是 free() 方法的源码:
public void free(PoolChunk<T> chunk, ByteBuffer nioBuffer, long handle, int normCapacity,
PoolThreadCache cache) {
// 如果是非池化的,则直接销毁目标内存块,并且更新相关的数据
if (chunk.unpooled) {
int size = chunk.chunkSize();
destroyChunk(chunk);
activeBytesHuge.add(-size);
deallocationsHuge.increment();
} else {
// 如果是池化的,首先判断其是哪种类型的,即tiny,small或者normal,
// 然后将其交由当前线程的缓存进行处理,如果添加成功,则直接返回
SizeClass sizeClass = sizeClass(normCapacity);
if (cache != null && cache.add(this, chunk, nioBuffer, handle,
normCapacity, sizeClass)) {
return;
}
// 如果当前线程的缓存已满,则将目标内存块返还给公共内存块进行处理
freeChunk(chunk, handle, sizeClass, nioBuffer);
}
}