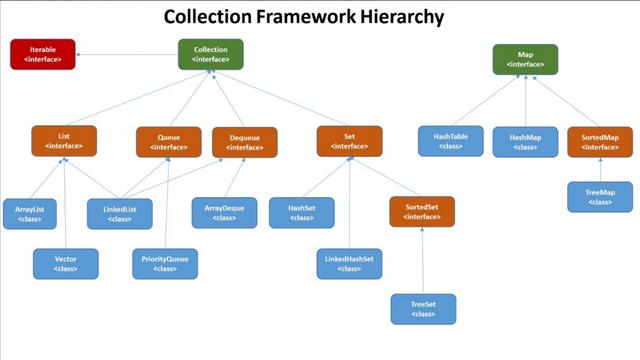
List、Set、Map的区别:
- List:存储的元素是有序的,可重复的。
- Set:存储的元素是无序的,不可重复的。
- Map:使用键值对(key-value)存储。key是无序、不可重复的,value是无序、可重复的。每个键最多映射一个值。
1.ArrayList和Vector的区别:
- ArrayList是List的主要实现类,底层使用Object[](数组)存储,适用于频繁的查找工作,现成不安全。
- Vector是List的古老实现类,底层使用Object[](数组)存储,线程安全。
2.ArrayList和LinkedList的区别:
- (1)是否保证线程安全:两者都是线程不安全的。
- (2)底层数据结构:ArrayList底层使用的是Object[]数组的数据结构;LinkedList底层使用的双向链表的数据结构(JDK1.6之前为循环链表,JDK1.7采用双向链表)。
- (3)插入和删除是否受元素位置的影响:
#ArrayList采用数组存储,所以插入和删除的时间复杂度受元素位置的影响。在执行add(E e)方法的时候, ArrayList默认会将元素插入到数组的末尾,这种情况的时间复杂度是O(1)。但如果要指定位置i进行插入元素,时间 复杂度则是O(n-i)。
#LinkedList采用链表存储,所以add(E e)插入和删除的时间复杂度不受元素位置影响,近似O(1)。而制定位置i进行 插入元素,时间复杂度近似为O(n)。
- (4)是否支持快速随机访问:ArrayList支持,LinkedList不支持,这都是由底层数据结构决定。ArrayList实现了Randomacces的接口,而LinkedList 没有实现该接口,但这并不是真正决定它是否具有随机访问元素的能力,这只是一个标识而已。
- (5)内存空间占用:ArrayList的空间占用体现在其初始化的时候就会先分配固定的内存空间,大部分情况下都会有剩余的空间没有被使用;LinedList的空间占用体现在每个Node(元素)的大小,因为每个Node既要存储相应的业务数据,还要存储链表的前驱和链表的后继。
3.ArrayList的扩容机制:
#HashSet如何检查重复
- 当把对象加入到HashSet时,会先计算对象的hashCode值来判断对象加入的位置,同时也会与其他加入的对象的hashCode值进行比较,如果没有相同的,则视为没有重复。如果有相同的,则会调用equals()方法检查两个对象是否相同,如果相同,则视为重复,加入失败。
#HashMap长度为什么是2的幂次方
- 主要是为了尽可能的减少碰撞,为了减少碰撞,其使用的算法是<(n-1)& hash>,即对hash值用数组长度取模。
void reverse(List list) ===========> 反转
void shuffle(List list) ============> 随机排序
void sort(List list) ===============> 按自然排序的升序排序
void sort(List list,Comparator c) ==> 定制排序,由Comparator控制排序逻辑
void swap(List list,int i,int j) ===> 交换两个索引位置的元素
void rotate(List list,int distance) => 旋转。当distance为正数时,将list后distance个元素整体移到前面。当为负数时,将list前disntance个元素整体移到后面
int binarySearch(List list,Object key) ==>对List进行二分查找,返回索引,注意List必须是有序的
int max(Collection coll) =============> 根据元素的自然顺序,返回最大的元素。类比int min(Collection coll)
int max(Collection coll,Comparator c) ===> 根据定制排序,返回最大元素
void fill(List list,Object obj) =========> 用指定的元素代替指定list中的所有元素。
int frequency(Collection c,Object o) =====> 统计元素出现次数
int indexOfSubList(List list,List target) ===>统计target在list中第一次出现的索引,找不到则返回-1
boolean replaceAll(List list,Object oldVaule,Object newValue) ===>用新元素替换旧元素