作者 | 孙雄
策划 | Tina
Bazel 是 google 公司于 2015 年开源的一款构建框架,至今收获了 21k 的 star 数,远超 gradle、maven、cmake 等同类产品。近几年来,字节阿里腾讯等互联网大厂也逐步拥抱 Bazel,搭建自己的构建体系。
Bazel 为什么如此受欢迎,原因正如它的宣传: "Correct & Fast, Choose Two",这并不是一句口号,从实际的用户体验也能看出。
(1) 得益于强大的增量构建机制,几万个文件的大型项目,可以做到秒级构建。
(2) Bazel 的封闭性设计,使得增量构建和缓存可信赖,用户不需要通过 clean 操作在构建前清理环境。
本文将分两部分阐述文章的主题。第一部分将分析 Bazel 高性能,高可靠的原理;第二部分则结合实际场景,聊一聊如何挖掘 Bazel 的极致性能。
Bazel 的优势
基于制品 (Artifact) 的构建系统
传统构建系统有很多是基于任务的,例如 Ant,Maven,Gradle。用户可以自定义"任务"(Task),例如执行一段 shell 脚本。用户配置它们的依赖关系,构建系统则按照顺序调度。
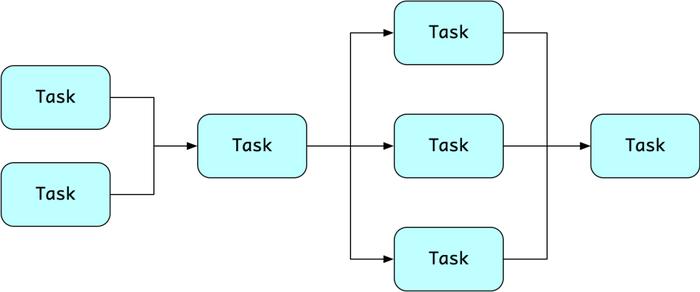 图 1 基于 Task 的调度模型
图 1 基于 Task 的调度模型
这种模式对使用者很友好,他可以专注任务的定义,而不用关心复杂的调度逻辑。构建系统通常给予任务制定者极大的"权利",比如 Gradle 允许用户用 JAVA 代码编写任务,原则上可以做任何事。
如果一个任务,在输入条件不变的情况下,永远输出相同的结果,我们就认为这个任务是"封闭"(Hermeticity) 的。构建系统可以利用封闭性提升构建效率,例如第二次构建时,跳过某些输入没变的 Task,这种方式也称为 增量构建。
不满足封闭性的任务,则会导致增量构建失效,例如 Task 访问某个互联网资源,或者 Task 在执行时依赖随机数或时间戳这样的动态特征,这些都会导致多次执行 Task 得到不同的结果。
Bazel 采用了不同的调度模型,它是基于制品 (Artifact) 的。Bazel 官方定义了一些规则 (rule),用于构建某些特定产物,例如 c++ 的 library 或者 go 语言的 package,用户配置和调用这些规则。他仅仅需要告诉 Bazel 要构建什么 Artifact,而由 Bazel 来决定如何构建它。
规则由官方和可信赖第三方维护,规则产生的任务,满足封闭性需求,这使得用户可以信赖系统的增量构建能力。
用户需要构建的 Artifact,在 Bazel 概念里被称为 Target,基于 Target 的调度模型如下图所示:
 图 2 基于 Target 的调度模型
图 2 基于 Target 的调度模型
图 2 中,File 表示原始文件,Target 表示构建时生成的文件。当用户告诉 Bazel 要构建某个 Target 的时候,Bazel 会分析这个文件如何构建(构建动作定义为 Action,和其他构建系统的 Task 大同小异),如果 Target 依赖了其他 Target,Bazel 会进一步分析依赖的 Target 又是如何构建生成的,这样一层层分析下去,最终绘制出完整的执行计划。
并行编译
Bazel 精准的知道每个 Action 依赖哪些文件,这使得没有相互依赖关系的 Action 可以并行执行,而不用担心竞争问题。基于任务的构建系统则存在这样的问题:
 图 3 基于任务的构建系统存在竞争问题
图 3 基于任务的构建系统存在竞争问题
如图 3 所示,两个 Task 都会向同一个文件写一行字符串,这就造成两个 Task 的执行顺序会影响最终的结果。要想得到稳定的结果,就需要定义这两个 Task 之间的依赖关系。
Bazel 的 Action 由构建系统本身设计,更加安全,也不会出现类似的竞争问题。因此我们可以充分利用多核 CPU 的特性,让 Action 并行执行。
通常我们采用 CPU 逻辑核心数作为 Action 执行的并发度,如果开启了远端执行 (后面会提到),则可以开启更高的并发度。
增量编译
对 Bazel 来说,每个 Target 的构建过程,都对应若干 Action 的执行。Action 的执行本质上就是"输入文件 + 编译命令 + 环境信息 = 输出文件"的过程。
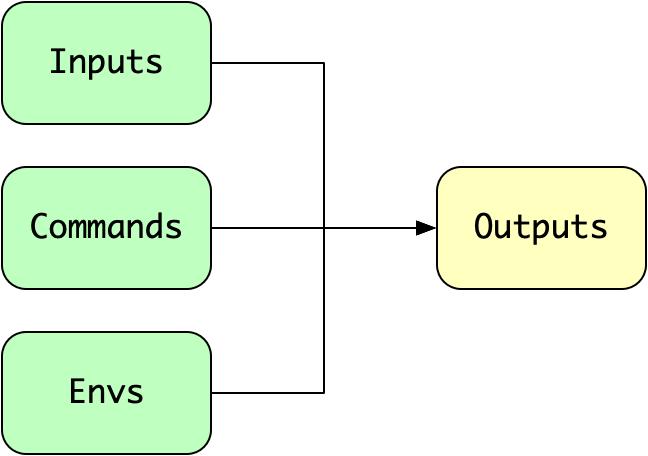 图 4 Action 的描述
图 4 Action 的描述
如果本地文件系统保留着上一次构建的 outputs,此时 Bazel 只需要分析 inputs, commands 和 envs 和上次相比有没有改变,没有改变就直接跳过该 Action 的执行。
这对于本地开发非常有用,如果你只修改了少量代码,Bazel 会自动分析哪些 Action 的 inputs 发生了变化,并只构建这些 Action,整体的构建时间会非常快。
不过增量构建并不是 Bazel 独有的能力,大部分的构建系统都具备。但对于几万个文件的大型工程,如果不修改一行代码,只有 Bazel 能在一秒以内构建完毕,其他系统都至少需要几十秒的时间,这简直就是 降维打击 了。
Bazel 是如何做到的呢?
首先,Bazel 采用了 Client/Server 架构,当用户键入 bazel build 命令时,调用的是 bazel 的 client 工具,而 client 会拉起 server,并通过 grpc 协议将请求 (buildRequest) 发送给它。由 server 负责配置的加载,ActionGraph 的生成和执行。
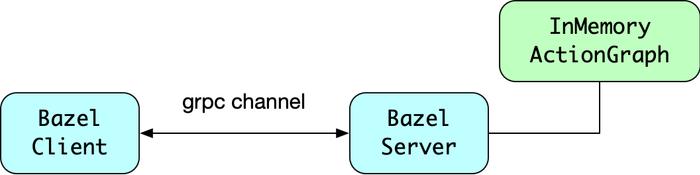 图 5 Bazel 的 C/S 架构
图 5 Bazel 的 C/S 架构
构建结束后,Server 并不会立即销毁,而 ActionGraph 也会一直保存在内存中。当用户第二次发起构建时,Bazel 会检测工作空间的哪些文件发生了改变,并更新 ActionGraph。如果没有文件改变,就会直接复用上一次的 ActionGraph 进行分析。
这个分析过程完全在内存中完成,所以如果整个工程无需重新构建,即便是几万个 Action,也能在一秒以内分析完毕。而其他系统,至少需要花费几十秒的时间来重新构建 ActionGraph。
远程缓存与远程执行
远程缓存
增量构建极大的提升了本地研发的构建效率,但有些场合它的效果不是很好,例如 CI 环境通常采用“干净”的容器,此时没有上一次的构建数据,只能全量构建。
即使是本地研发,如果从远端同步代码时修改了全局参数,也会导致增量构建失效。
缓存 (Remote Cache) 与远程执行 (Remote Execution) 可以很好的解决这个问题。
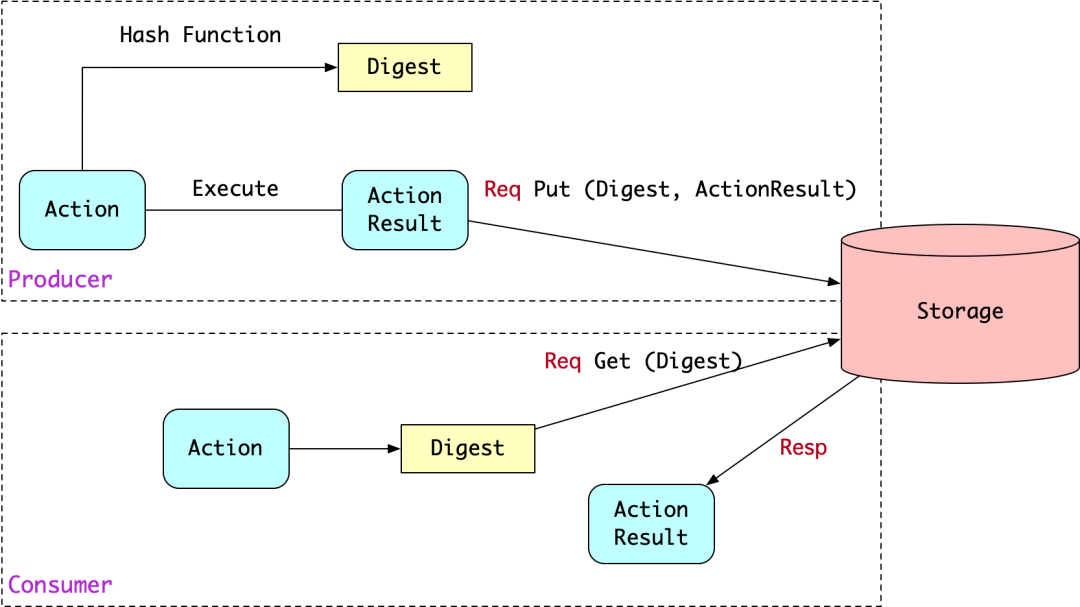
前面聊到,Action 满足封闭性,即相同的 Action 信息一定产生相同的结果。因此可以建立 Action 到 ActionResult 的映射。为了便于索引,Bazel 把 Action 信息通过 sha256 哈希算法压缩成摘要 (Digest),把 Digest 到 ActionResult 的映射存储在云端,就可以实现 Action 的跨构建共享。
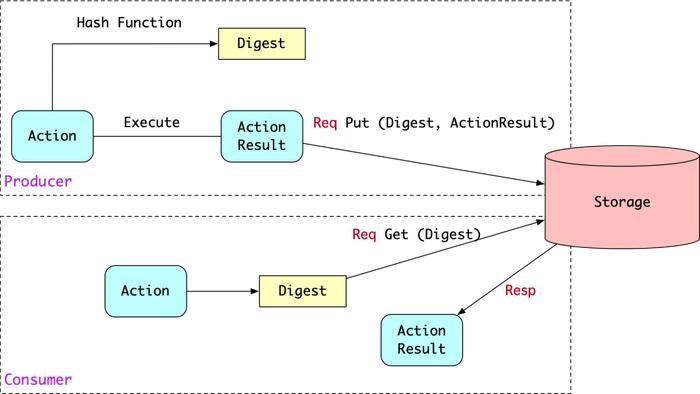 图 6 Action 共享示意图
图 6 Action 共享示意图
这里的 Storage 是完全基于内容寻址的,即“一个 Digest 唯一对应一个 ActionResult”,内容寻址的好处是不容易污染存储空间,因为修改任何一行代码会计算出不同的 Digest,不用担心污染别人的 ActionResult。内容寻址的存储引擎,被称为 Content Addressable Storage(CAS),如果没有特别强调,本文后续使用简称 CAS 来表述。
CAS 里存放的任何文件,无论是 Action 的 META 信息还是编译产物二进制,都被称为 Blob。
为保证 CAS 的存储空间被有效利用,通常会使用 LRU 算法管理 CAS 里存储的 Blob,当存储空间写满时,最久没被访问的 Blob 就会被自动淘汰,这样就保证了空间里的 Blob 是最活跃的。
远程执行
既然 ActionResult 可以被不同的 Bazel 任务共享,说明 ActionResult 和 Action 在哪里执行并没有关系。因此,Bazel 在构建时,可以把 Action 发送给另一台服务器执行,对方执行完,向 CAS 上传 ActionResult,然后本地再下载。
这种做法减少了本地执行 Action 的开销,使得我们设置更高的构建并发度。
Bazel 为 Remote Cache 和 Remote Execution 设计了专门的协议 Remote Execution API,用于规范协议的客户端和服务端的行为。
完整的流程如下图所示:
 图 7 远程执行流程
图 7 远程执行流程
可以看到,Client 和 Server 的直接交互是很少的,大部分情况还是和 CAS 交互,这部分采用了增量的设计,Client 先调用 findMissingBlobs 接口,该接口的请求参数是一堆 Blob Digest 列表,返回值是 CAS 缺失的 Digest 列表。这样 Client 只上传这些 Blob,可以减少网络传输的浪费。
Remote Execution API 是一套通用的远程执行协议,客户端部分由 Bazel 实现,服务端部分可自行定制。Bazel 团队开发两款开源实现,分别是 Bazel Remote(CAS) 和 Buildfarm (Remote Executoin & CAS),除此之外也有 Buildbarn,Buildgrid 等开源实现以及 Engflow,Buildbuddy 这样的企业版。
企业版除了提供更稳定,弹性的远程执行服务外,通常还提供数据分析能力,用户可以根据自己的条件选择合适的开源软件或企业版服务。
外部依赖缓存 (repository_cache)
前面我们主要分析了基于 Action 的增量构建,缓存和远程执行机制。现在让我们看看 Bazel 是如何管理外部依赖的。
大部分项目都没法避免引入第三方的依赖项。构建系统通常提供了下载第三方依赖的能力。为了避免重复下载,Bazel 要求在声明外部依赖的时候,需要记录外部依赖的 hash,例如下面的这种形式:
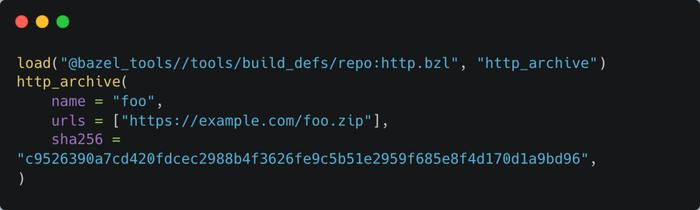 图 8 外部依赖描述
图 8 外部依赖描述
Bazel 会将下载的依赖,以 CAS 的方式存储在内置的 repository_cache 目录下。你可以通过
bazel info repository_cache 命令查看目录的位置。
Bazel 认为通过 checksum 机制,外部依赖应该是全局共享的,因此无论你的本地有多少个工程,哪怕使用的是不同的 Bazel 版本,都可以共享一份外部依赖。
除此之外,Bazel 也支持通过 1.0.0 这样的 SerVer 版本号来声明依赖,这是 Bazel6.0 版本加入的功能,也是官方推荐使用的,具体做法可以查看官网 相关部分。
如何高效使用 Bazel
Bazel 为了正确性和高性能,做了很多优秀的设计,那么我们如何正确的使用这些能力,让我们的构建性能“起飞”呢, 我们将从本地研发和 CI pipeline 两种场景进行分析。
本地研发
本地研发通常采用默认的 Bazel 配置即可,无需为增量构建和 repository_cache 做额外配置,Bazel 默认就处理的很好。
使用时应该信任 bazel 的增量构建机制,即便是从远端仓库同步了代码,也可以直接 build,无须先通过 bazel build 清理环境。
至于 Remote Cache 和 Remote Execution,则需要结合网络状况和 Action 的执行开销,决定是否开启,参数是 --remote_cache 和 --remote_execution。
正确开启 bazel 的 remote 能力
正确开启 remote_cache 和 remote_execution 对构建效率有显著作用,但网络或 Action 特性,也可能导致收益不明显甚至劣化。
举个例子说明使用 remote_cache 的利弊:
我们假设 Action 的执行时间是 a,上传缓存和下载缓存的时间分别是 b 和 c, 缓存命中率是μ
如果不使用 remote cache,耗时恒定为 a,如果使用 remote cache, 命中缓存耗时是 c,不命中则是 a + b, 结合命中率,可以求出耗时的数学期望是 μc + (1 - μ)(a + b)
也就是说,只有 μc + (1 - μ)(a + b)
例如 Action 执行时间是 500ms,上传产物时间是 200ms,下载产物时间是 100ms,缓存命中率是 30%, 代入到式子中:0.3 * (500 + 200 - 100)ms = 180ms
实践中,我们不一定能对 Action 做如此精细的数据分析,但可以根据网络状况大致估算。Bazel 提供了精细化的控制方式,可以控制某一种类型的 Action 是否启用 remote_cache,例如:
 图 9 针对 CppLink 禁用 remote_cache
图 9 针对 CppLink 禁用 remote_cache
图 9 针对 CppLink 类型的 Action 禁用了 remote_cache 能力,其他类型则可以正常使用。甚至还可以通过 no-remote-cache-upload,设置为只禁止上传缓存,不禁止下载缓存。
对于缓存的精细化设置属于比较高级的功能,Bazel 暂时没有过多开放相关能力,相关的文档也不全。或许我们可以期待一下,未来能使用更方便的配置来管理。
缓存命中率调优
上面的例子可以看出,Action 的缓存命中率直接决定了 remote cache 的收益,如何优化缓存命中率呢?
前文介绍原理时,我们知道 Action 由 inputs 和 commands 组成,inputs 指执行 Action 所需的目录结构和文件内容。而 commands 包括了参数 (args), 执行路径 (workdir) 和环境变量 (envs)。
当缓存命中率不符合预期时,我们需要对 Action 的详情进行调试。
bazel 的 --execution_log_binary_file 参数可以把 Action 的详细信息打印到文件里。
对比两次构建的 Action 详情,就可以知道是什么参数发生了变化。
该参数导出的原始信息是二进制格式,有一些特殊字符,如下图所示:
 图 10 execution_log_binary_file 文本
图 10 execution_log_binary_file 文本
可以借助 bazel 的 execution_log_parser 工具,把它变成更可读的形式:
该工具需要源码编译 bazel:
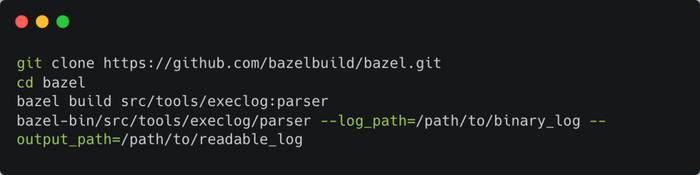 图 11 使用 parser 工具把 log 变成可读形式
图 11 使用 parser 工具把 log 变成可读形式
转换后的文件如下图所示:
 图 12 转换后的 execution_log
图 12 转换后的 execution_log
之后就可以用文本对比工具,对两次构建生成的 execution_log 进行对比。
CI pipeline
再来看到 CI 场景,如果你在公司里搭建了持续集成流水线,则需要考虑更多的东西。在公司内网的模式下,CI 的网络往往不再是瓶颈,我们应该完整的使用 Remote Cache 和 Remote Execution 的能力。
搭建 Remote Execution 服务
使用 Remote 能力的前提是部署支持 Remote Execution 协议的服务,一般来说,开源产品 buildfarm 或 buildbarn 就足够使用了,如果对性能和数据分析有更加极致的要求,可以考虑企业版产品或者基于 Remote Execution API 协议自研。
Remote Execution 服务的架构设计是一个很大,也很有趣的话题。篇幅关系,本文不过多深入细节,但提供几点设计要求可以参考:
Remote Execution 服务通常包括 scheduler 和 worker 组件,集群规模较小时,单 scheduler 可以调度所有 Action,而规模较大时,需要多 scheduler 协同,这是一个很大的挑战。
scheduler 的职责是把 Action 调度给 最合适 的 worker,并且分派的过程 越快越好。
如何衡量任务调度的好与坏,一方面尽量让 Action 均匀分布,避免排队时间过长,另一方面尽量利用 worker 的本地文件缓存,减少重复的文件下载。
不同客户端发来的相同 Action,可以考虑在服务端进行合并。
不同类型的 worker,需要根据系统的负载,进行弹性伸缩,以确保资源的高效利用。
客户端调度增强
除了 Remote Execution 服务,另一块需要注意的地方是客户端调度。不同于本地构建,CI 场景为了追求强隔离性,往往以实时运行 Docker ContAIner 的方式提供构建环境。也就是说,构建环境不包含上一次构建的数据。
这种模式对于 Bazel 构建很不友好,不仅外部依赖要重新下载,而且增量编译功能也无法使用。但我们也有办法尽可能的加快构建速度。
 图 13 CI 环可复用的要素
图 13 CI 环可复用的要素
首先是使用 Remote Cache 和 Remote Execution 服务,在没有增量构建的场景下,Remote Cache 和 Remote Execution 提供的优化效果是非常夸张的,根据我的观察,提速普遍在 70% 以上,甚至能达到 90%。
其次是缓存本地数据,例如 trivas CI 这样的流水线编排系统,就支持对特定目录进行缓存。它的原理是把目录打包上传到对象存储,下次构建时再下载下来。我们可以将 Bazel 的 repository_cache 和 action_local_cache 相关的目录进行缓存,下次构建就可以直接复用。
如果条件允许的话,甚至可以要求流水线提供常驻容器,这样 Bazel 的进程都可以长期保留着,下次构建时,直接 Attach 到已有的容器上执行命令即可。这种方式有望在 CI pipeline 场景实现秒级构建,这是多么酷的一件事情啊!
不过,常驻容器对安全性也带来了一定的挑战,企业具体采用那种方案,也应该因实际情况而异。
总 结
本文从原理方面介绍了 Bazel 高性能的原因,从实践方面针对本地研发和 CI pipeline 两种场景给出了建议。
Bazel 在设计时非常注重“增量”,“缓存”和“并行”,这是高性能的 基础。而 Bazel 官方推出并维护了不同语言的构建规则,也保证了构建过程时封闭,可靠的,这是高性能的 前提。除此之外,针对工作空间的完整 ActionGraph 的内存缓存机制 (skyframe),使得 Bazel 对大型项目拥有秒级的构建速度,这也是其他主流构建系统远远达不到的。
在实际使用中,我们不仅需要深度了解 Bazel 的缓存和远程执行机制,也需要根据不同的场景配置不同的参数。本地场景需要关注网络和缓存命中率,以决定是否开启远端缓存和远端执行能力。CI 场景则需要关心流水线的调度能力,尽可能的提升数据的复用。