近年来,基于扩散模型(Diffusion Models)的图像生成模型层出不穷,展现出令人惊艳的生成效果。然而,现有相关研究模型代码框架存在过度碎片化的问题,缺乏统一的框架体系,导致出现「迁移难」、「门槛高」、「质量差」的代码实现难题。
为此,中山大学人机物智能融合实验室(HCP Lab)构建了 HCP-Diffusion 框架,系统化地实现了模型微调、个性化训练、推理优化、图像编辑等基于 Diffusion 模型的相关算法,结构如图 1 所示。
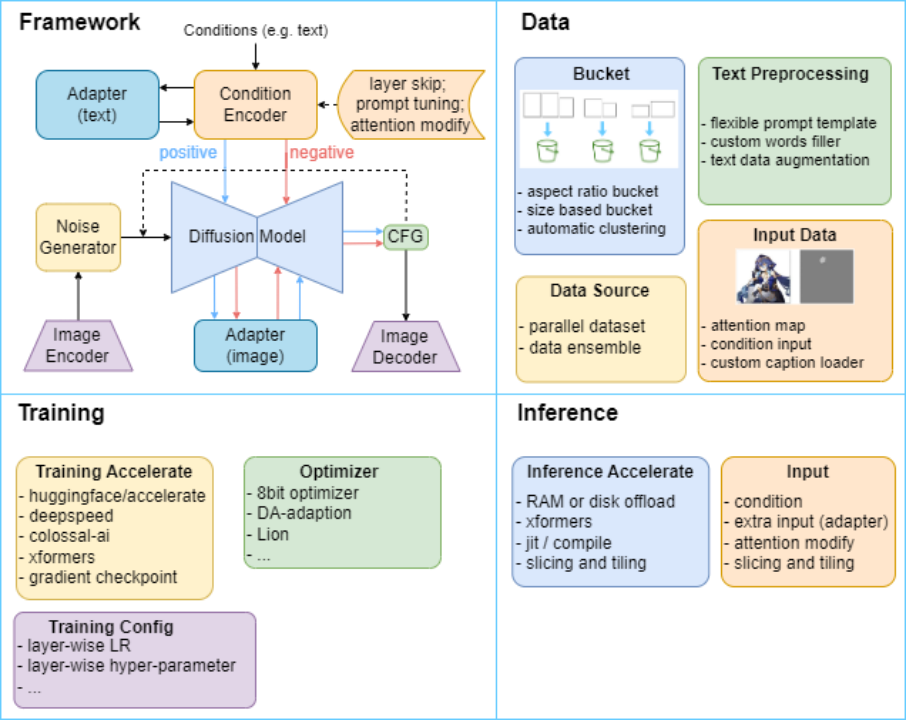
图 1 HCP-Diffusion 框架结构图,通过统一框架统一现有 diffusion 相关方法,提供多种模块化的训练与推理优化方法。
HCP-Diffusion 通过格式统一的配置文件调配各个组件和算法,大幅提高了框架的灵活性和可扩展性。开发者像搭积木一样组合算法,而无需重复实现代码细节。
比如,基于 HCP-Diffusion,我们可以通过简单地修改配置文件即可完成 LoRA,DreamArtist,Contro.NET 等多种常见算法的部署与组合。这不仅降低了创新的门槛,也使得框架可以兼容各类定制化设计。
HCP-Diffusion 代码工具:https://Github.com/7eu7d7/HCP-Diffusion
HCP-Diffusion 图形界面:https://github.com/7eu7d7/HCP-Diffusion-webui
HCP-Diffusion:功能模块介绍
框架特色
HCP-Diffusion 通过将目前主流的 diffusion 训练算法框架模块化,实现了框架的通用性,主要特色如下:
统一架构:搭建 Diffusion 系列模型统一代码框架
算子插件:支持数据、训练、推理、性能优化等算子算法,如 deepspeed, colossal-AI 和 offload 等加速优化
一键配置:Diffusion 系列模型可通过高灵活度地修改配置文件即可完成模型实现
一键训练:提供 Web UI,一键训练、推理
数据模块
HCP-Diffusion 支持定义多个并行数据集,每个数据集可采用不同的图像尺寸与标注格式,每次训练迭代会从每个数据集中各抽取一个 batch 进行训练,如图 2 所示。此外,每个数据集可配置多种数据源,支持 txt、json、yaml 等标注格式或自定义标注格式,具有高度灵活的数据预处理与加载机制。
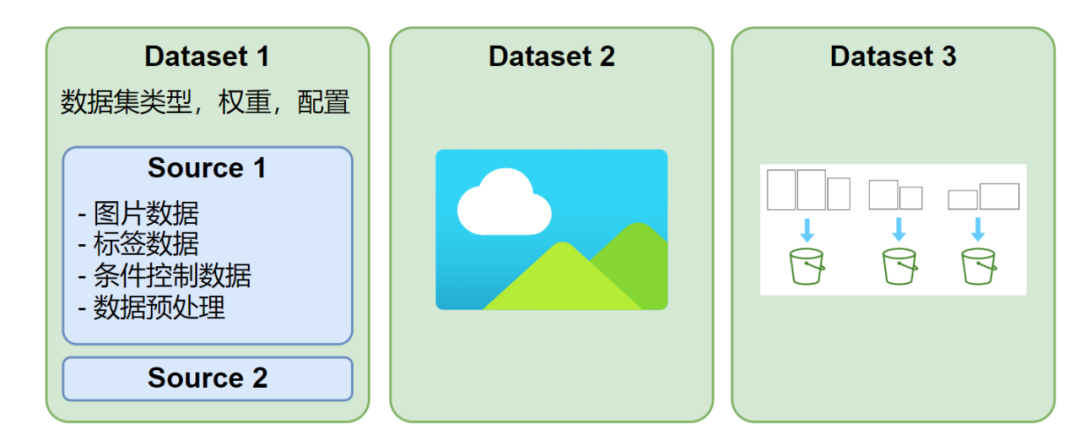 图 2 数据集结构示意图
图 2 数据集结构示意图
数据集处理部分提供带自动聚类的 aspect ratio bucket,支持处理图像尺寸各异的数据集。用户无需对数据集尺寸做额外处理和对齐,框架会根据宽高比或分辨率自动选择最优的分组方式。该技术大幅降低数据处理的门槛,优化用户体验,使开发者更专注于算法本身的创新。
而对于图像数据的预处理,框架也兼容 torch vision, albumentations 等多种图像处理库。用户可以根据需要在配置文件中直接配置预处理方式,或是在此基础上拓展自定义的图像处理方法。
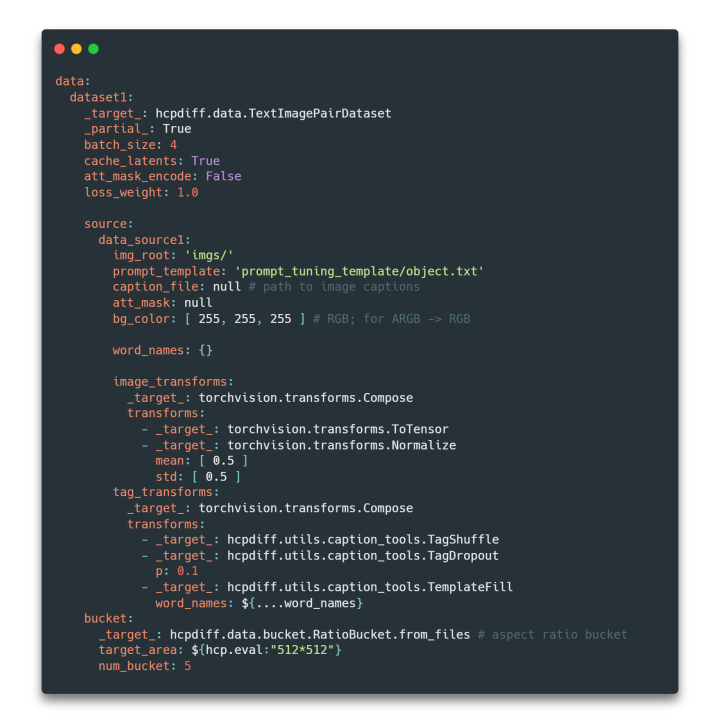
HCP-Diffusion 在文本标注方面,设计了灵活且清晰的 prompt 模板规范,可支持复杂多样的训练方法与数据标注。其对应用上述配置文件 source 目录下的 word_names,里面可自定义下图大括号中的特殊字符对应的嵌入词向量与类别描述,以与 DreamBooth、DreamArtist 等模型兼容。

并且对于文本标注,也提供了按句擦除 (TagDropout) 或按句打乱 (TagShuffle) 等多种文本增强方法,可以减少图像与文本数据间的过拟合问题,使生成的图像更多样化。
模型框架模块
HCP-Diffusion 通过将目前主流的 diffusion 训练算法框架模块化,实现了框架的通用性。具体而言,Image Encoder,Image Decoder 完成图像的编解码,Noise Generator 产生前向过程的噪声,Diffusion Model 实现扩散过程,Condition Encoder 对生成条件进行编码,Adapter 微调模型与下游任务对齐,positive 与 negative 双通道代表正负条件对图像的控制生成。

如图 5 所示,HCP-Diffusion 在配置文件中通过简易的组合,即可实现 LoRA、ControlNet、DreamArtist 等多种主流训练算法。同时支持对上述算法进行组合,例如 LoRA 和 Textual Inversion 同时训练,为 LoRA 绑定专有触发词等。此外,通过插件模块,可以轻松自定义任意插件,业已兼容目前所有主流方法接入。通过上述的模块化,HCP-Diffusion 实现了对任意主流算法的框架搭建,降低了开发门槛,促进了模型的协同创新。
HCP-Diffusion 将 LoRA、ControlNet 等各种 Adapter 类算法统一抽象为模型插件,通过定义一些通用的模型插件基类,可以将所有这类算法统一对待,降低用户使用成本和开发成本,将所有 Adapter 类算法统一。
框架提供四种类型的插件,可以轻松支持目前所有主流算法:
+ SinglePluginBlock: 单层插件,根据该层输入改变输出,比如 lora 系列。支持正则表达式 (re: 前缀) 定义插入层, 不支持 pre_hook: 前缀。
+ PluginBlock: 输入层和输出层都只有一个,比如定义残差连接。支持正则表达式 (re: 前缀) 定义插入层, 输入输出层都支持 pre_hook: 前缀。
+ MultiPluginBlock: 输入层和输出层都可以有多个,比如 controlnet。不支持正则表达式 (re: 前缀), 输入输出层都支持 pre_hook: 前缀。
+ WrAppluginBlock: 替换原有模型的某个层,将原有模型的层作为该类的一个对象。支持正则表达式 (re: 前缀) 定义替换层,不支持 pre_hook: 前缀。
训练、推理模块
 图 6 自定义优化器配置
图 6 自定义优化器配置
HCP-Diffusion 中的配置文件支持定义 Python/ target=_blank class=infotextkey>Python 对象,运行时自动实例化。该设计使得开发者可以轻松接入任何 pip 可安装的自定义模块,例如自定义优化器,损失函数,噪声采样器等,无需修改框架代码,如上图所示。配置文件结构清晰,易于理解,可复现性强,有助于平滑连接学术研究和工程部署。
加速优化支持
HCP-Diffusion 支持 Accelerate、DeepSpeed、Colossal-AI 等多种训练优化框架,可以显著减少训练时的显存占用,加快训练速度。支持 EMA 操作,可以进一步提高模型的生成效果和泛化性。在推理阶段,支持模型 offload 和 VAE tiling 等操作,最低仅需 1GB 显存即可完成图像生成。

通过上述简单的文件配置,即可无需耗费大量精力查找相关框架资源完成模型的配置,如上图所示。HCP-Diffusion 模块化的设计方式,将模型方法定义,训练逻辑,推理逻辑等完全分离,配置模型时无需考虑训练与推理部分的逻辑,帮助用户更好的聚焦于方法本身。同时,HCP-Diffusion 已经提供大多数主流算法的框架配置样例,只需对其中部分参数进行修改,就可以实现部署。
HCP-Diffusion:Web UI 图像界面
除了可直接修改配置文件,HCP-Diffusion 已提供了对应的 Web UI 图像界面,包含图像生成,模型训练等多个模块,以提升用户体验,大幅降低框架的学习门槛,加速算法从理论到实践的转化。
 图 8 HCP-Diffusion Web UI 图像界面
图 8 HCP-Diffusion Web UI 图像界面
实验室简介
中山大学人机物智能融合实验室 (HCP Lab) 由林倞教授于 2010 年创办,近年来在多模态内容理解、因果及认知推理、具身学习等方面取得丰富学术成果,数次获得国内外科技奖项及最佳论文奖,并致力于打造产品级的AI技术及平台。实验室网站:http://www.sysu-hcp.net