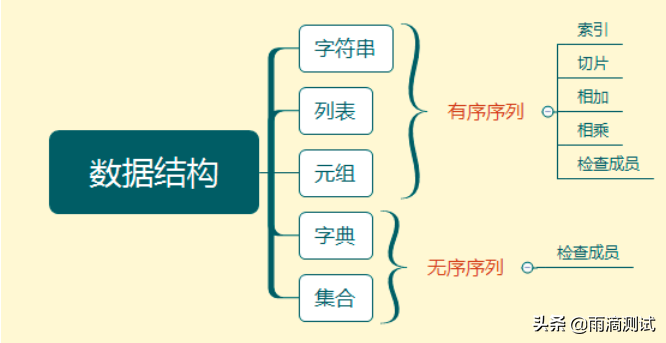
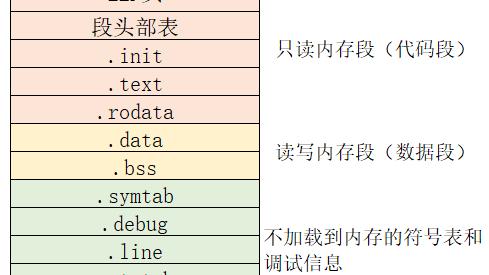
查找表为线性表,其存储结构为一维结构数组,也即是顺序表,数组的每一个元素对应查找表的一个记录。为简单起见,设记录中只有一个整数关键字,存放记录的结构体类型描述如下:
typedef struct
{
int key; /*存放关键字的成员项*/
…… /*其它成员项*/
} NODE;
顺序查找(Sequential Search)是一种最简单的查找方法。现假设查找表中有n个记录,顺序存放在某个数组a中。顺序查找的方法为:从顺序表的一端开始,将给定值依次与数组中各个记录的关键字进行比较,若在表中找到某个记录的关键字与给定值相等,则查找成功,返回记录所在位置的下标i;若在找完表中所有记录后也未找到与给定值相等的关键字的记录,则查找失败,给出失败信息。该算法适合顺序表中记录的关键字无序的情况。
int search(NODE a[],int n, int k)
/*在a[0]~a[n-1]中顺序查找关键字等于k的记录。查找成功时返回该记录的下标,失败时返回-1*/
{
int i=0;
while(i
i++;
if(a[i].key = =k) /*查找成功*/
return i;
else return -1; /*查找失败*/
}
在该算法中,while循环语句中包含两个判断条件,势必会影响查找的速度,因此要尽可能地减少判断条件以提高效率。这里介绍一个编程小技巧来达到这一目的。具体做法是:在顺序表的末尾设置一个监视哨a[n].key,开始查找之前,先将给定关键字的值k赋给a[n].key,这样循环中就不用判断整个表是否查找完毕。具体算法如下:
int search(NODE a[],int n, int k)
/*在a[0]~a[n-1]中顺序查找关键字等于k的记录。查找成功时返回该记录的下标,失败时返回-1*/
{
int i=0;
a[n].key=k;
while(a[i].key!=k)
i++;
if(i>=n)
return -1; /*查找成功*/
else
return i; /*查找失败*/
}
顺序查找的基本操作是关键字的比较。查找成功的最好情况是第一个记录就符合查找要求,只需进行一次比较;最坏情况是第n个记录符合查找要求,要进行n次比较。若每个记录的查找概率相等,即pi=1/n,且每次都是成功查找,则顺序查找的平均查找长度为:

对于算法8-2,查找不成功时关键字的比较次数为n+1,顺序查找的算法时间复杂度为O(n)。