在学习C语言或者其他编程语言的时候,我们编写的一个程序代码,基本都是在屏幕上打印出 hello world ,开始步入编程世(深)界(坑)的。C 语言版本的 hello world 代码:
#include <stdio.h>
int main()
{
printf("hello worldn");
return 0;
}不用多说,这段程序在运行时,会在显示终端上打印出 hello world 。
那么,这段程序背后关联的内容,你是否真正梳理明白了呢?
闲话少说,让我们进入正题,扒一扒 hello world 背后的内幕。
注:本文是在 Ubuntu 环境下对程序的编译和运行进行实验,相关内容以 linux 系统为主。
在 Linux 系统或者其他环境下,将源码编程成可执行程序,很简单。点击编译按钮或者输入编译指令即可完成。例如,在 Linux 下,用 gcc 编译此程序代码,然后运行:
$ gcc hello.c -o hello
$ ./hello
hello world但是,你知道编译器干了哪些工作吗?编译器将源代码文件编程成可执行程序,经历了四步:编译预处理、编译、汇编、链接。
编译过程
1. 编译预处理
编译预处理过程主要是处理源代码文件中,以 “#” 开头的预编译指令。例如,“#inlude”、“#define”等。
预处理器根据以字符 “#” 开头的指令,修改原始的 C 程序文件,生成一个以 .i 为扩展名的程序文件。
本例中,#include<stdio.h> 命令告诉预处理器,读取系统头文件 stdio.h 的内容,并把它插入到源程序文本中。
在 Linux 环境下,可以通过如下指令得到预处理完成后的 .i 文件
$ gcc -E hello.c -o hello.i这个文件内容比较长,如果有兴趣的话可以自己进行实验,查看一下。
2. 编译
编译的过程就是把预处理完的文件,进行一系列的词法分析、语法分析、语义分析以及优化后,生成相应的汇编代码文件。这个过程往往是整个程序构建的核心部分。
将 hello.i 文件翻译成文本文件 hello.s,其内部是一个汇编语言的程序。
通过如下指令可以得到汇编文件
$ gcc -S hello.i -o hello.s3. 汇编
汇编器将上一步生成的汇编代码翻译成机器可以执行的指令,把这些指令打包成可重定位目标程序,保存在目标文件 hello.o 中。
可以通过下边的指令生成:
$ gcc -c hello.s -o hello.o文件 hello.o 是一个二进制文件。
4. 链接
hello 程序调用了 printf 函数,这是 标准 C 库中的一个函数。printf 函数存储在一个预编译好的目标文件 printf.o 中,链接器负责将这个文件以某种方式合并到 hello.o 程序中。
合并处理后,得到一个可执行目标文件 hello,这个可执行文件可以由系统加载运行。
hello.c 程序已经被编译可执行的目标文件 hello,且存在磁盘上。那这个程序是如何运行起来的呢?
当然,你可以说,通过如下指令可以运行程序:
$ ./hello
hello world但是,从计算机角度来说,运行这个程序需要做哪些工作呢?
当输入 “./hello” 后,shell 开始处理这条指令。
首先,shell 加载可执行文件 hello,复制目标文件 hello 中的代码和数据到内存中。
数据和指令加载完成后,处理器开始执行 hello 程序中 main 函数的机器指令。这些指令将 “hello world” 字符串中的字节复制到寄存器文件,再从寄存器文件中复制显示设备上,最终在屏幕上显示出来。
程序执行过程
其实,操作系统在加载程序后,还做了一些工作,用于准备 main 函数执行需要的环境,然后调用 main 函数。
在 Linux 下,可执行文件的存储格式为 ELF(Executable Linkable Format)。那么其内部结构是什么样的呢?
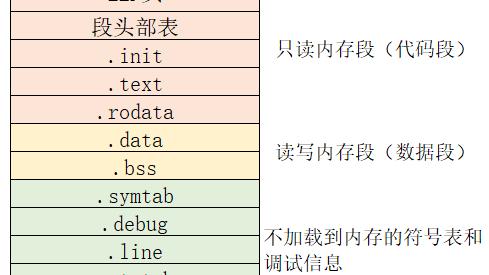
典型的 ELF 可执行文件的布局情况如下:
可执行文件布局
ELF 头部描述了整个文件的属性,包括,文件是否可执行、目标硬件、目标操作系统、入口点等信息。
.init 定义了一个小函数,叫做 _init,程序的初始化代码会调用它。
.text 为已编译程序的机器代码。 .rodata 为只读数据,比如 printf 语句中格式串。.data 为已初始化的全局和静态 C 变量。
.bss 存放未初始化的全局变量和局部静态变量,以及所有被初始化为 0 的全局或静态变量。不占用实际的空间,只是一个占位符。
.symtab 是一个符号表,存放在程序中定义和引用的函数和全局变量的信息。
.debug 一个调试符号表,内部是程序定义的局部变量和类型定义,程序定义和引用的全局变量,以及原始的 C 源文件。
.line 源程序中的行号和 .text 节中机器指令之间的映射。
.strtab 一个字符串表,内容包括 .symtab 和 .debug 节中的符号表,以及节头部中的节名字。
总体来说,将程序源码编译之后生成的目标文件,主要分成两种段:程序指令和程序数据。代码段属于程序指令,数据段和 .bss 段属于程序数据。
可执行程序被加载器加载到内存,即从磁盘内复制可执行文件中的代码和数据到内存中,然后跳转到程序的入口点来运行该程序。将程序复制到内存并运行的过程就叫做加载。
在 Linux 系统中,每个程序都有一个运行时的内存映像。
程序加载后内存布局
代码段后边是数段,运行时,堆在数据段之后,通过调用 malloc 库向上增长。
用户栈总是从最大的合法用户地址开始,向较小内存地址增长。
用户栈以上的区域,是为内核中的代码和数据保留的。
程序加载运行时,会创建类似上图所示的内存映像,在程序头部的引导下,加载器将可执行文件复制到代码段和数据段,然后加载器跳转到程序的入口点。
入口点的函数调用启动函数,初始化执行环境,然后调用用户层的 main 函数,处理 main 函数的返回值,并在需要的时候把控制权返回给内核。
main 函数为作为用户可执行程序的入口,是由系统启动函数内部定义的。在环境准备好后,调用 main 函数,开始执行用户程序。
没想到,这么简单的程序背后,涉及到这么多知识内容。