下面列举了常见的数据结构
Select * from t where t.col=5
我们在执行一条查询的Sql语句时候,在数据量比较大又不加索引的情况下,逐行查询并进行比对,每次需要从磁盘上查找,每行数据可能在磁盘不同的位置,数据比较靠后的话,一千万数据可能要比对几百万,很耗费资源。
Mysql衡量查询效率的就是磁盘IO次数,那么Mysql中应该采用什么样的数据结构存储数据呢,以及为什么要使用那个数据结构呢。
大多数人都知道,如果加上索引之后。把数据放在二叉树里面,查询会快很多,但是还有一种特殊的情况:
把一个递增列的索引放入二叉树中,列id作为等于5查询目标,就会从col为1开始搜索,**这样要搜索几次?**二叉树插入的数据如果大于本身,会放在父节点的右下角,小的会放在父节点的左下角,因此形成了这样像链表一样的结构,其实本质还是二叉树。

需要从根节点遍历,经过5次的查找,每个节点都存储在磁盘上,每查一个节点需要跟磁盘做一次IO交互,效率相比之前没加索引也没有太大提升,这显然不是Mysql的索引结构。
HasMap的数据结构就是红黑树,原来是数组加链表,现在优化到了数组加红黑树。

红黑树本质还是二叉树,还有一个名字又叫平衡二叉树。当一边子节点比另一边高太多的时候,会自动旋转平衡。当数据量比较大的时候比如1000万,红黑树存储的高度就可能达到几十。如果数据量越大树的高度就会越高。每查一个节点要进行一次磁盘IO交互。树的高的越高查找效率越低,很显然红黑树也不是Mysql的数据结构,早期版本Mysql有用到红黑树,现在版本没有用到红黑树。那么能不能对红黑树做点改造。
树的高的越高查找效率越低,那么将树高缩小,比如限制在5层,把一层存放更多元素。把一个节点的数据在磁盘同一个区域全部查出来放到内存,只做一次IO查找,就可以查到很多索引信息。B树又叫平衡多叉树。

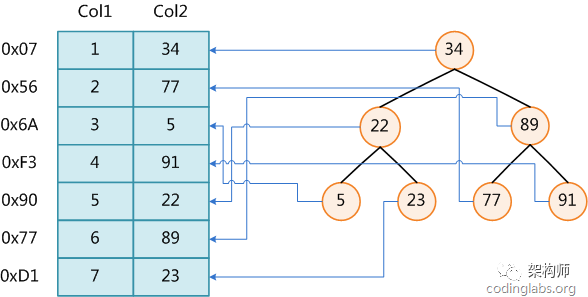
索引值和具体data都在每个节点里,而节点的位置不固定,最好的情况查找值就在第一层。
B树的特点就是每层节点数目非常多,层数很少,目的就是为了减少磁盘IO次数,B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题,由于节点内部每个 key 都带着 data 域,每次查找到具体节点还要和data进行顺序比对,如果查找某个范围内数据,又需要重新遍历。正是为了解决这个问题,B+树应运而生
B树遍历全部数据:

B+树节点只存储 key 的副本,真实的 key 和 data 域都在叶子节点存储,数据全部存储在叶子节,并且每一个节点之间用指针串联起来,形成链表,方便遍历,可以跨区间访问,这优点尤其突出在范围查询,不需要在一次从根节点到子节点遍历。

B+树遍历全部数据:

数据量大的情况下哪个更快,我想你应该知道了吧!