背景
Java8的stream接口极大地减少了for循环写法的复杂性,stream提供了map/reduce/collect等一系列聚合接口,还支持并发操作:parallelStream。
在爬虫开发过程中,经常会遇到遍历一个很大的集合做重复的操作,这时候如果使用串行执行会相当耗时,因此一般会采用多线程来提速。Java8的paralleStream用fork/join框架提供了并发执行能力。但是如果使用不当,很容易陷入误区。
Java8的paralleStream是线程安全的吗
一个简单的例子,在下面的代码中采用stream的forEach接口对1-10000进行遍历,分别插入到3个ArrayList中。其中对第一个list的插入采用串行遍历,第二个使用paralleStream,第三个使用paralleStream的同时用ReentryLock对插入列表操作进行同步:
private static List<Integer> list1 = new ArrayList<>();
private static List<Integer> list2 = new ArrayList<>();
private static List<Integer> list3 = new ArrayList<>();
private static Lock lock = new ReentrantLock();
public static void main(String[] args) {
IntStream.range(0, 10000).forEach(list1::add);
IntStream.range(0, 10000).parallel().forEach(list2::add);
IntStream.range(0, 10000).forEach(i -> {
lock.lock();
try {
list3.add(i);
}finally {
lock.unlock();
}
});
System.out.println("串行执行的大小:" + list1.size());
System.out.println("并行执行的大小:" + list2.size());
System.out.println("加锁并行执行的大小:" + list3.size());
}
执行结果:
串行执行的大小:10000并行执行的大小:9595加锁并行执行的大小:10000
并且每次的结果中并行执行的大小不一致,而串行和加锁后的结果一直都是正确结果。显而易见,stream.parallel.forEach()中执行的操作并非线程安全。
那么既然paralleStream不是线程安全的,是不是在其中的进行的非原子操作都要加锁呢?我在stackOverflow上找到了答案:
在上面两个问题的解答中,证实paralleStream的forEach接口确实不能保证同步,同时也提出了解决方案:使用collect和reduce接口。
在Javadoc中也对stream的并发操作进行了相关介绍:
The Collections Framework provides synchronization wrAppers, which add automatic synchronization to an arbitrary collection, making it thread-safe.
Collections框架提供了同步的包装,使得其中的操作线程安全。
所以下一步,来看看collect接口如何使用。
stream的collect接口
闲话不多说直接上源码吧,Stream.java中的collect方法句柄:
<R, A> R collect(Collector<? super T, A, R> collector);
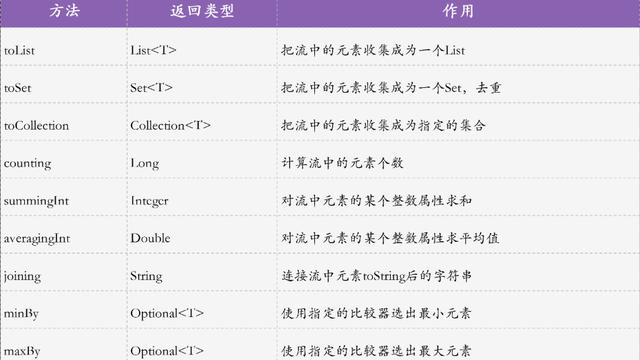
在该实现方法中,参数是一个Collector对象,可以使用Collectors类的静态方法构造Collector对象,比如Collectors.toList(),toSet(),toMap(),etc,这块很容易查到API故不细说了。
除此之外,我们如果要在collect接口中做更多的事,就需要自定义实现Collector接口,需要实现以下方法:
Supplier<A> supplier();
BiConsumer<A, T> accumulator();
BinaryOperator<A> combiner();
Function<A, R> finisher();
Set<Characteristics> characteristics();
要轻松理解这三个参数,要先知道fork/join是怎么运转的,一图以蔽之:

上图来自:http://www.infoq.com/cn/articles/fork-join-introduction
简单地说就是大任务拆分成小任务,分别用不同线程去完成,然后把结果合并后返回。所以第一步是拆分,第二步是分开运算,第三步是合并。这三个步骤分别对应的就是Collector的supplier,accumulator和combiner。talk is cheap show me the code,下面用一个例子来说明:
输入是一个10个整型数字的ArrayList,通过计算转换成double类型的Set,首先定义一个计算组件:
Compute.java:
public class Compute {
public Double compute(int num) {
return (double) (2 * num);
}
}
接下来在Main.java中定义输入的类型为ArrayList的nums和类型为Set的输出结果result:
private List<Integer> nums = new ArrayList<>();
private Set<Double> result = new HashSet<>();
定义转换list的run方法,实现Collector接口,调用内部类Container中的方法,其中characteristics()方法返回空set即可:
public void run() {
// 填充原始数据,nums中填充0-9 10个数
IntStream.range(0, 10).forEach(nums::add);
//实现Collector接口
result = nums.stream().parallel().collect(new Collector<Integer, Container, Set<Double>>() {
@Override
public Supplier<Container> supplier() {
return Container::new;
}
@Override
public BiConsumer<Container, Integer> accumulator() {
return Container::accumulate;
}
@Override
public BinaryOperator<Container> combiner() {
return Container::combine;
}
@Override
public Function<Container, Set<Double>> finisher() {
return Container::getResult;
}
@Override
public Set<Characteristics> characteristics() {
// 固定写法
return Collections.emptySet();
}
});
}
构造内部类Container,该类的作用是一个存放输入的容器,定义了三个方法:
Container.java:
class Container {
// 定义本地的result
public Set<Double> set;
public Container() {
this.set = new HashSet<>();
}
public Container accumulate(int num) {
this.set.add(compute.compute(num));
return this;
}
public Container combine(Container container) {
this.set.addAll(container.set);
return this;
}
public Set<Double> getResult() {
return this.set;
}
}
在Main.java中编写测试方法:
public static void main(String[] args) {
Main main = new Main();
main.run();
System.out.println("原始数据:");
main.nums.forEach(i -> System.out.print(i + " "));
System.out.println("nncollect方法加工后的数据:");
main.result.forEach(i -> System.out.print(i + " "));
}
输出:
原始数据:0 1 2 3 4 5 6 7 8 9
collect方法加工后的数据:0.0 2.0 4.0 8.0 16.0 18.0 10.0 6.0 12.0 14.0
我们将10个整型数值的list转成了10个double类型的set,至此验证成功~
本程序参考 http://blog.csdn.net/io_field/article/details/54971555。
一言蔽之
总结就是paralleStream里直接去修改变量是非线程安全的,但是采用collect和reduce操作就是满足线程安全的了。
测试1
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Warmup(iterations = 5, time = 3, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 20, time = 3, timeUnit = TimeUnit.SECONDS)
@Fork(1)
@State(Scope.Benchmark)
public class StreamBenchTest {
List<String> data = new ArrayList<>();
@Setup
public void init() {
// prepare
for(int i=0;i<100;i++){
data.add(UUID.randomUUID().toString());
}
}
@TearDown
public void destory() {
// destory
}
@Benchmark
public void benchStream(){
data.stream().forEach(e -> {
e.getBytes();
try {
Thread.sleep(10);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
});
}
@Benchmark
public void benchParallelStream(){
data.parallelStream().forEach(e -> {
e.getBytes();
try {
Thread.sleep(10);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
});
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(".*" +StreamBenchTest.class.getSimpleName()+ ".*")
.forks(1)
.build();
new Runner(opt).run();
}
}
parallelStream线程数
默认是Runtime.getRuntime().availableProcessors() - 1,这里为7
运行结果
# Run complete. Total time: 00:02:44
Benchmark Mode Cnt Score Error Units
StreamBenchTest.benchParallelStream avgt 20 155868805.437 ± 1509175.840 ns/op
StreamBenchTest.benchStream avgt 20 1147570372.950 ± 6138494.414 ns/op
测试2
将数据data改为30,同时sleep改为100
Benchmark Mode Cnt Score Error Units
StreamBenchTest.benchParallelStream avgt 20 414230854.631 ± 725294.455 ns/op
StreamBenchTest.benchStream avgt 20 3107250608.500 ± 4805037.628 ns/op
可以发现sleep越长,parallelStream优势越明显。
小结
parallelStream在阻塞场景下优势更明显,其线程池个数默认为Runtime.getRuntime().availableProcessors() - 1,如果需修改则需设置-Djava.util.concurrent.ForkJoinPool.common.parallelism=8
以上就是本次讲述知识点的全部内容,感谢你对码农之家的支持。
以上就是本次给大家分享的关于java的全部知识点内容总结,感谢大家的阅读和支持。