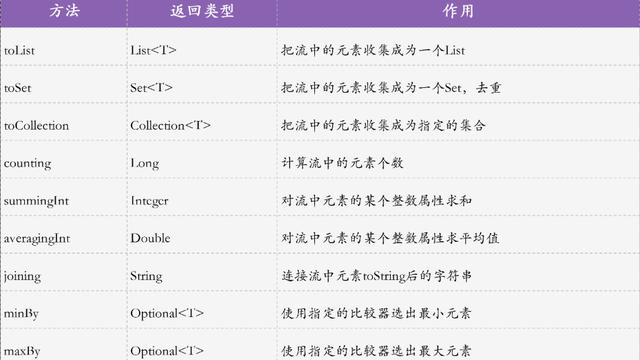
本文介绍JAVA诸多优化实例:第一,排查堆上、堆外内存泄露;第二,使用arthas、jaeger、tcpdump、jstack做性能优化;第三,排查进程异常退出的原因,如被杀、System.exit、Java调用的C++发生Crash、Java内Crash;第四,排查死锁的原因,如log4j死锁、封装不严谨导致的死锁
内存泄露在C++里排查很简单,用钩子函数勾住内存分配和释放函数malloc和free,统计哪些malloc的内存没有free,就可以找出内存泄露的源头。但在Java里问题复杂的多,主要因为Java在内存之上有层JVM管理内存。
JVM先从操作系统申请大内存,接着自己管理这部分内存。所以Java程序的内存泄露分为两种:堆上内存泄露、堆外内存泄露,而堆外内存泄露又分为两种:Java使用堆外内存导致的内存泄露、Java程序使用C++导致的内存泄露。
分析内存泄露首先需要确认是堆上泄漏还是堆外泄露。可以通过jmap -heap pid确认,如下图所示,老年代PS Old Generation使用率占99.99%,再结合gc log,如果老年代回收不掉,基本确认为堆上内存泄露,也不排除进程本身需要这么多内存,此时需要分析堆。而堆外内存泄露的显著表现是top命令查出来的物理内存显著比通过xmx配置的最大内存大。

堆上内存泄露是最常见的,申请的对象引用和内存全在JVM堆上,而对象使用完后,对象引用被其他长生命周期的对象一直拿着,导致无法从堆上释放。首先用jdk/bin/jmap -dump:live,format=b,file=heap.hprof {pid},导出堆里所有活着的对象。然后用工具分析heap.hprof。
分析堆上内存泄露的主流工具有两种:JDK自带的bin目录下的jvisualvm.exe、Eclipse的MemoryAnalyzer。MemoryAnalyzer更强大,可自动分析可疑的内存泄露。使用MemoryAnalyzer时,需要在MemoryAnalyzer.ini里通过-Xmx参数配置最大内存,否则无法打开大堆。接下来介绍堆上内存泄露的若干实例。
使用MemoryAnalyzer自动分析内存泄露,报告如下,可以看到RaftServerMetrics占了44.68%的内存,所有实例大小98M内存,且所有的RaftServerMetrics实例被一个ConcurrentHashMap引用。


接着在直方图里过滤RaftServerMetrics,共找到2065个实例。

然后右键RaftServerMetrics->Merge shortest path to GC Roots ->with all references查找所有引用RaftServerMetrics的地方,结果如下,可看到所有的RaftServerMetrics实例被变量metricsMap引用,问题原因是RaftServerMetrics使用完后,未从静态变量metricsMap里删除。

MemoryAnalyzer自动分析内存泄露时,有时并不能准确的找到,此时需要自己分析哪些对象占用内存过多。下图是使用jvisualvm.exe打开堆的结果,查看数目或者内存异常的对象,可以看到很多对象数目都是111580个,且最后一列显示的内存占用大,从对象的包分析,都和netty有关,且是client相关的对象,基本确认这些对象和内存泄露有关。进一步分析代码,发现大量RPC连接使用完后未关闭。

JDK提供绕过JVM直接在操作系统申请内存的接口,例如通过Unsafe类的allocateMemory、freeMemory直接分配、释放内存,内存对象的引用在堆上,但内存在堆外。排查此类内存泄露,首先开启:
-XX:NativeMemoryTracking=detail
然后jcmd pid VM.native_memory detail,打出内存分配信息,注意NativeMemoryTracking显示的内存不包含C++分配的内存。此处需要关注两个点,第一,Total行的committed数值是否等于进程占用的物理内存,如果不等,说明有C++等native code分配的内存,可参考Java调用C++组件 分析;第二,Native Memory Tracking的committed数值是否过大,如果过大,说明有Unsafe.allocateMemory分配了太多内存。

Unsafe.allocateMemory的使用场景有两个:第一,封装在DirectByteBuffer内;第二,业务直接使用Unsafe.allocateMemory。
DirectByteBuff通常被用于通信框架如netty中,不仅可以减少GC压力,而且避免IO操作时将对象从堆上拷贝到堆外。为了快速验证是否DirectByteBuffer导致内存泄露,可使用参数-XX:MaxDirectMemorySize限制DirectByteBuffer分配的堆外内存大小,如果堆外内存仍然大于MaxDirectMemorySize,可基本排除DirectByteBuffer导致的内存泄露。
分析DirectByteBuffer的内存首先可用Java Mission Control,绑定到进程,并查看DirectByteBuffer占的内存如2.24GB。此处也可直接用MemoryAnalyzer打开dump的堆,统计所有DirectByteBuffer的capacity之和,计算DirectByteBuffer申请的堆外内存大小。

然后用命令jdk/bin/jmap -dump:live,format=b,file=heap.hprof {pid},导出堆里所有活着的对象,并用MemoryAnalyzer打开dump的堆,分析所有的DirectByteBuffe:Merge shortest path to GC Roots ->with all references。
如果排除DirectByteBuffer,那就是应用程序直接用Unsafe类的allocateMemory分配的内存,例如Spark的off heap memory[1]。此时可排查代码所有Unsafe.allocateMemory的地方。
例如RocksDB采用C++实现,并通过JNI提供给Java调用的接口,如果Java通过JNI创建了新的RocksDB实例,RocksDB会启动若干后台线程申请、释放内存,这部分内存都对Java不可见,如果发生泄漏,也无法通过dump jvm堆分析。
分析工具可采用google的gperftools,也可用jemalloc,本文采用jemalloc,首先安装jemalloc到/usr/local/lib/libjemalloc.so。
git clone https://github.com/jemalloc/jemalloc.gitgit checkout 5.2.1./configure --enable-prof --enable-stats --enable-debug --enable-fillmake && make install然后在进程启动脚本里,添加如下命令,LD_PRELOAD表示JVM申请内存时不再用glibc的ptmalloc,而是使用jemalloc。MALLOC_CONF的lg_prof_interval表示每次申请2^30Byte时生成一个heap文件。export LD_PRELOAD=/usr/local/lib/libjemalloc.soexport MALLOC_CONF=prof:true,lg_prof_interval:30并在进程的启动命令里添加参数-XX:+PreserveFramePointer。进程启动后,随着不断申请内存,会生成很多dump文件,可把所有dump文件通过命令一起分析:jeprof --show_bytes --pdf jdk/bin/java *.heap > leak.pdf。
leak.pdf如下所示,可看到所有申请内存的路径,进程共申请过88G内存,而RocksDB申请了74.2%的内存,基本确定是不正常的行为,排查发现不断创建新的RocksDB实例,共1024个,每个实例都在运行,优化方法是合并RocksDB实例。
需要注意的是,88G是所有申请过的内存,包含申请但已经被释放的,因此通过该方法,大部分情况下能确定泄露源头,但并不十分准确,准确的方法是在C++代码里用钩子函数勾住malloc和free,记录哪些内存未被释放。

perf是最为普遍的性能分析工具,在Java里可采用阿里的工具arthas进行perf,并生成火焰图,该工具可在Docker容器内使用,而系统perf命令在容器里使用有诸多限制。
下载arthas-bin.zip[2],运行./a.sh,然后绑定到对应的进程,开始perf: profiler start,采样一段时间后,停止perf: profiler stop。结果如下所示,可看到getServiceList耗了63.75%的CPU。

另外,常用优化小建议:热点函数避免使用lambda表达式如stream.collect等、热点函数避免使用正则表达式、避免把UUID转成String在协议里传输等。
perf适用于查找整个程序的热点函数,但不适用于分析单次RPC调用的耗时分布,此时就需要jaeger。
jaeger是Uber开源的一个基于Go的分布式追踪系统。jaeger基本原理是:用户在自己代码里插桩,并上报给jaeger,jaeger汇总流程并在UI显示。非生产环境可安装jaeger-all-in-one[3],数据都在内存里,有内存溢出的风险。在需要追踪的服务的启动脚本里export JAEGER_AGENT_HOST={jaeger服务所在的host}。
下图为jaeger的UI,显示一次完整的流程,左边为具体的插桩名称,右边为每块插装代码耗时,可以看到最耗时的部分在including leader create container和including follower create container,这部分语义是leader创建完container后,两个follower才开始创建container,而创建container非常耗时,如果改成leader和两个follower同时创建container,则时间减少一半。

tcpdump常用来抓包分析,但也能用来优化性能。在我们的场景中,部署Ozone集群(下一代分布式对象存储系统),并读数据,结果发现文件越大读速越慢,读1G文件,速度只有2.2M每秒,使用perf未发现线索。

用命令tcpdump -i eth0 -s 0 -A 'tcp dst port 9878 and tcp[((tcp[12:1] & 0xf0) >> 2):4] = 0x47455420' -w read.cap,该命令在读200M文件时会将所有GET请求导出到read.cap文件,然后用wireshark打开read.cap,并过滤出HTTP协议,因为大部分协议都是TCP协议,用于传输数据,而HTTP协议用于请求开始和结束。
从下图的wireshark界面,可看到读200M文件,共有10个GET请求:GET /goofys-bucket/test.dbf HTTP/1.1,每个GET请求读20M文件,每个GET请求读完后回复:HTTP/1.1 200 OK。第1个GET请求到达S3gateway时间为0.2287秒,第10个GET请求到达Ozone集群时间为1.026458秒。第1个GET请求完成时间为1.869579秒,第10个GET请求完成时间为23.640925秒。
可见10个GET请求在1秒内全部到达Ozone集群,但每个请求耗时越来越长。因此只需要分析后续的GET请求读同样大小的数据块,比前序GET请求多做了哪些事情即可。

最后通过分析日志和阅读代码发现,Ozone采用的第三方库commons-io采用read实现skip。例如读第10个GET请求时,实际只需要读[180M, 200M),但commons-io实现skip前180M时,会将前180M读出来,导致第10个GET请求读完整的[0M, 200M),因此GET请求越来越慢。优化后,性能提升一百倍。
jstack用来查询线程状态,但在极端情况下也可以用于性能优化。在部署服务时,发现进程迅速占满所有CPU,24核的机器进程使用CPU达到2381%。

CPU使用如此之高,无法运行arthas进行perf分析,只能采用其他策略。首先用top -Hp pid命令打出进程pid的所有线程及每个线程的CPU消耗。如下图,第一列PID为线程号,%CPU列代表CPU消耗,注意该图只是展示作用,该图的进程并不是使用CPU达到2381%的进程,原进程的信息当初没保存。

然后计算出使用CPU最高的线程号的十六进制表示0x417,再用jstack -l pid > jstack.txt命令打出所有线程状态,用0x417在jstack.txt查询消耗CPU最高的线程,即下图所示ThreadPoolExecutor里的线程,该线程一直处于RUNNABLE,且队列为empty,基本确认该部分线程出了问题,因为正常的线程不会一直空转,状态会有TIMED_WAITING的时刻。
因为线程堆栈不包含业务代码,都是JDK的源码,因此用线程堆栈搜索JDK相关问题,最终发现是JDK8的Bug:JDK-8129861,该Bug在创建大小为0的线程池时容易触发,因此在应用代码里,将大小为0的线程池修改即可。

在生产环境发生过进程被清理脚本杀掉。排查工具有两个:linux自带的auditd和systemtap。
首先使用auditd,因为该工具简单易用,不用安装。使用service auditd status检查服务状态,如果未启动可用service auditd restart启动。然后使用命令:auditctl -a exit,always -F arch=b64 -S kill,监听所有的Kill信号。如下图所示,从type=OBJ_PID行里可以看到:捕捉到的Kill信号杀的进程号opid=40442,线程名ocomm=”rocksdb:pst_st”,注意这里打出的线程名而不是进程名。
从type=SYSCALL行里可以看到:a1=9表示kill -9;发出kill -9的进程是exe=”/usr/bin/bash”,进程号是pid=98003。从这些信息并不能找到相应的进程,因为脚本往往运行完就停止,生命周期非常短。

接下来使用systemtap分析,systemtap需要安装:yum install systemtap systemtap-runtime。先写systemtap脚本findkiller.stp,如下所示,该systemtap脚本捕捉杀进程sig_pid的KILL信号,并使用task_ancestry打印发出KILL信号进程的所有祖先进程。
probe signal.send{if(sig_name == "SIGKILL" && sig_pid == target()) {printf("%s, %s was sent to %s (pid:%d) by %s (pid:%d) uid :%dn", ctime(gettimeofday_s()), sig_name, pid_name , sig_pid, execname(), pid(), uid());printf("parent of sender: %s(%d)n", pexecname(), ppid());printf("task_ancestry:%sn", task_ancestry(pid2task(pid()), 1)); }}然后stap -p4 findkiller.stp生成ko文件:stap_XX.ko,有的机器需要将ko文件补上签名才能运行。然后运行:nohup staprun -x 98120 stap_XX.ko >nohup.out 2>&1 &,此处的98120即为脚本中的target()。
捕捉结果如下,从图里可以看出发出KILL命令的进程是通过crond启动的,也就是说定时任务运行了某些脚本杀了进程。但仍然不知道定时任务启动了哪个脚本杀了进程。

接下来再用auditd排查,使用命令:auditctl -a exit,always -F arch=b64 -S execve捕捉所有的系统调用,结果如下,最后一行是捕捉到杀进程opid=20286的信号,从图中可看出kill信号附近出现的都是/data/tools/clean命令。

/data/tools/clean里调用了若干脚本,在每个脚本里用打出当前脚本名和进程号到crontab.pid里。并和systemtap抓到的进程号62118对比,找到了KILL信号是从kill_non_run_App.sh脚本里发出。

如果在Java程序里显式调用System.exit结束进程,可以用arthas排查。首先写脚本system_exit.as如下。
options unsafe truestack java.lang.System exit -n 1运行命令nohup ./as.sh -f system_exit.as 69001 -b > system_exit.out 2>&1 &,即可监控进程69001调用的所有System.exit。
此处发生的Crash案例和下文Java内Crash产生的原因一样,但现象不一样,大部分情况下,是Crash在C++代码,只产生core文件,不产生Java内Crash的Crash log;少量情况下Crash在JVM里,产生Java内Crash的Crash log。
如果Java通过JNI调用C++代码,在C++里发生Crash,JVM有时不会产生任何信息就退出,此时借助操作系统产生的core file分析进程退出原因,但操作系统默认关闭该功能,如下图所示core file size为0表示关闭该功能。

因此需要在进程的启动脚本里(只影响当前进程)设置ulimit -c ulimited来设置core file的大小,启动进程后,打开/proc/{pid}/limits,查看Max core file size的大小确认是否开启。

当发生Crash时,会生成core.pid文件,一般core.pid文件会非常大,因为该文件包含了所有虚拟内存大小,所以大于物理内存,如下图所示core.44729共53GB。

接下来使用命令gdb bin/java core.44729打开core文件,发现是rocksdb start thread时挂的,挂在libstdc++里,这是glibc库,基本不可能出问题,因此该堆栈可能是表象,有其他原因导致start thread失败。

注意到打开core文件时,有太多线程-LWP轻量级进程。

然后在gdb里用info threads,发现有三万多个线程,都在wait锁状态,基本确认三万多个线程,导致内存太大,创建不出来新的线程,因此挂在start thread里。

接着分析三万多个线程都是什么线程,随机选几十个线程,打出每个线程的堆栈,可以看到大部分线程都是jvm线程。因为rocksdb创建出来的线程是:
从/tmp/librocksdbjni8646115773822033422.so来的;而jvm创建出来的线程都是从/usr/java/jdk1.8.0_191-amd64/jre/lib/amd64/server/libjvm.so来的,这部分线程占了大部分。


因此问题出在Java代码里,产生core.pid文件的进程,虽然没有产生crash log,但也是因为Java 线程太多,导致C++代码创建线程时挂掉。至于为什么Java线程太多请看Java内Crash。
另外,core.pid完整的保留了C++组件Crash时的现场,包括变量、寄存器的值等,如果真的因为C++组件有Bug而Crash,例如空指针等。首先自行找到C++源码,找出怀疑空指针的变量{variableName},通过在gdb里执行命令:p {variableName},可以看出每个变量的值,从而找出空指针的变量。
排查Java内Crash的原因如OOM等,需要配置JVM的如下参数:
-XX:ErrorFile
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath。
JVM内发生Crash时,会在-XX:ErrorFile配置的路径下生成crash log。而-XX:+HeapDumpOnOutOfMemoryError、-XX:HeapDumpPath用于发生OOM时生成Dump堆,用于还原现场。下图所示为产生的crash log。可以看到创建线程时发生OutOfMemory导致进程挂掉。

从下图crash log可以看到有两万四千个Datanode State machine Thread线程都在等锁。到此确认上文Java调用C++发生Crash 产生core.pid的进程和产生crash log的进程都是因为两万多个Datanode State Machine Thread挂掉。

接着分析为何有两万多个Datanode State Machine Thread,代码里可以看到该线程用线程池newCacheThreadPool创建。该newCacheThreadPool在没有线程可用,例如线程都在等锁的情况下,会创建新的线程,因此创建了两万多个线程。接着分析Datanode State Machine Thread等的什么锁。在进程的线程数超过5000时,用jstack -l pid > jstack.txt打出所有线程的状态。
可以看到几乎所有Datanode State Machine Thread在等锁,而只有一个Datanode State Machine Thread – 5500 拿到了锁,但是卡在提交RPC请求submitRequest。至此Java调用C++发生Crash 和Java内Crash的原因找到。


jstack打出的死锁信息如下所示。grpc-default-executor-14765线程拿到了log4j的锁,在等RaftServerImpl的锁;grpc-default-executor-14776线程拿到了RaftServerImpl的锁,在等log4j的锁,导致这两个线程都拿到了对方等待的锁,所以造成两个线程死锁。可以看出,仅仅打日志的log4j,不释放锁是最值得怀疑的地方。最后发现log4j存在死锁的缺陷[4]。该缺陷在log4j2得到解决,升级log4j即可。


jstack打出的死锁信息如下所示。grpc-default-executor-3449线程拿到了RaftLog的锁,在等DataBlockingQueue的锁;SegmentedRaftLogWorker拿到了DataBlockingQueue的锁,在等RaftLog的锁。


这里最值得怀疑的是SegmentedRaftLogWorker拿到了DataBlockingQueue的锁却不释放,因为queue的操作只是在队列里增、删、查元素。如下图所示DataBlockingQueue的方法poll,使用的锁是自己封装的锁AutoCloseableLock implement AutoCloseable,锁的释放依赖于AutoCloseableLock重载的close方法。

再看acquire方法,先用lock.lock()拿到锁,再创建新的AutoCloseableLock对象,如果拿到锁后,在创建新对象AutoCloseableLock时发生OOM等异常,锁就无法释放。

参考
[1]https://www.waitingforcode.com/Apache-spark/apache-spark-off-heap-memory/read
[2]https://github.com/alibaba/arthas/releases/tag/arthas-all-3.3.6
[3]https://www.jaegertracing.io/docs/1.18/getting-started/
[4]https://stackoverflow.com/questions/3537870/production-settings-file-for-log4j/