不知道各位在项目开发过程中有没有过这种体会,接手上一任的代码,看到代码的那一刻,有一种想要砸电脑的冲动,一个方法体内写了无数行代码,到处皆可看到复制粘贴的代码,变量命名也让人看不懂。
各位在编码时,是否有想过,我如何才能写出高质量的代码,写出优雅的代码,写出高度可扩展的代码。我相信大家都希望能写出那样的代码,让人佩服的五体投地,可不知道如何写,那么本文就是为帮助大家提高编码质量而生的。
我相信,大家在看完本文后,一定会有所领悟。下面,我们就进入主题。
在介绍 lombok 之前,我们先来看一段代码:
public class Person {
private Long id;
private String name;
private Integer age;
private Integer sex;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Integer getSex() {
return sex;
}
public void setSex(Integer sex) {
this.sex = sex;
}
}
这段代码大家应该都很熟悉,我们在开发 JAVAWeb 项目时,定义一个 Bean,会先写好属性,然后设置 getter/setter 方法,这段代码本身没有任何问题,也必须这样写。
但是每个 bean 都需要些 getter/setter,这样写的话就不够优雅了,这段代码我们如何优雅的写呢?接下来就轮到强大的 lombok 出场了。
lombok 是一个可以通过注解的形式来简化我们的代码的一个插件,要使用它,我们应该先安装插件,安装步骤如下:
1.
打开 IDEA 的 Plugins,点击 Browse repositories。
2.
搜索 lombok,并安装它,安装好后重启 IDEA。
3.
打开 Settings,找到 Annotaion Processors,将 Enable annotaion processing 勾选上。
4.单纯这样还不够,我们要用到 lombok 的注解还需要添加其依赖:
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.0</version>
<scope>provided</scope>
</dependency>
import lombok.Getter;
import lombok.Setter;
@Getter
@Setter
public class Person {
private Long id;
private String name;
private Integer age;
private Integer sex;
}
我们可以看到,在类上加入了 Getter 和 Setter 两个注解,将之前写的 getter/setter 方法干掉了,这种代码看着清爽多了,写个 main 方法来测试下:
public static void main(String[] args) {
Person person = new Person();
person.setName("lynn");
person.setId(1L);
System.out.println(person.getName());
}
我们并没有写任何 setter/getter 方法,只是加了两个注解就可以调用了,这是为什么呢?这是因为 lombok 提供的 Getter 和 Setter 注解是编译时注解,也就是在编译时,lombok 会自动为我们添加 getter/setter 方法,因此我们不需要显式地去写 getter/setter 方法而可以直接调用,这样的代码是不是看着非常优雅。
当然,lombok 的功能不止于此,它提供了很多注解以简化我们的代码,下面,我将分别介绍它的其他常用注解:
该注解的作用是是否开启链式调用,比如我们开启链式调用:
@Getter
@Setter
//chain设置为true表示开启链式调用
@Accessors(chain = true)
public class Person {
private Long id;
private String name;
private Integer age;
private Integer sex;
public static void main(String[] args) {
Person person = new Person();
person.setName("lynn").setId(1L);
}
}
构建者模式,我们在使用第三方框架时经常能看到 Builder 模式,比如 HttpClient 的:
RequestConfig config = RequestConfig.custom()
.setConnectionRequestTimeout(timeout)
.setConnectTimeout(timeout)
.setSocketTimeout(timeout)
.build();
那么,通过 Builder 注解可以很方便的实现它:
@Getter
@Setter
@Builder
public class Person {
private Long id;
private String name;
private Integer age;
private Integer sex;
public static void main(String[] args) {
Person person = new PersonBuilder()
.name("lynn")
.id(1L)
.build();
}
}
编译时添加 getter、setter、toString、equals 和 hashCode 方法,如:
@Data
public class Person {
private Long id;
private String name;
private Integer age;
private Integer sex;
public static void main(String[] args) {
Person person = new Person();
person.setName("lynn");
System.out.println(person);
}
}
添加输入输出流 close 方法,如:
public static void main(String[] args) throws Exception{
@Cleanup InputStream inputStream = new FileInputStream("1.txt");
}
我们通过断点调试发现,它会调用 close(),说明 lombok 帮我们生成了 close():
通过 lombok 的注解,可以极大的减少我们的代码量,并且更加清爽,更加优雅。
lombok 还有很多注解,如:
日志相关注解(当然需要添加相关日志依赖):
一说到设计模式,我相信大家都能说出那 23 种设计模式,并且还能说出每种设计模式的用法,但是大多数同学应该都没有在实际应用中真正运用过设计模式,还只是停留在理论阶段。
不知道各位是否有过这个感觉,整个应用被相同的代码充斥着,自己也知道这种代码不好,但是不知道怎么做优化,虽然知道有 23 种设计模式,却不知道怎么运用。
本节我就将以实际的例子教大家如何在实际应用中灵活运用所学的设计模式。
(实际应用中,一个场景可能不只包含一个设计模式,很有可能需要多种设计模式配合使用才能写出优雅的高质量的代码。)
我们在做后台管理系统时,会有这样一个需求,根据后台的数据统计导出报表,需要支持 Excel、word、PPT、PDF 等格式。
对于以上需求,一般做法是:为每一个导出报表的方法提供一个方法,然后在 Service 里判断,如果为 excel,则调用 excel 的方法,如果为 Word 则调用 word 的方法,
如:
public void exportReport(String type){
if("Excel".equals(type)){
exportExcel();
}else if("Word".equals(type)){
exportWord();
}
...
}
这样写本身没有问题,也能实现需求,但是它有以下缺点:
我们在开发时需要遵循有一个原则:一个方法做你该做的事。也就是无论增加什么样的报表格式,业务方法 exportReport 的作用依然是导出功能,除非业务需求发生改变,否则不能修改业务方法。
那么,我们该怎么改造呢?
我们发现,导出报表可以导出不同的格式,这些格式我们可以理解为产品,需要由一个地方产出,因此马上就能想到可以利用工厂模式对其进行改造,下面是改造后的代码:
public enum Type {
EXCEL,
WORD,
PPT,
PDF;
}
/**
* 模板引擎基类
* 所有模板类继承此类
* @author 李熠
*
*/
public abstract class Template {
//读取内容
public abstract List<Serializable> read(InputStream inputStream)throws Exception;
//写入内容
public abstract void write(List<Serializable> data)throws Exception;
}
//Excel模板
public class ExcelTemplate extends Template {
@Override
public List<Serializable> read(InputStream inputStream)throws Exception{
List<Serializable> list = new ArrayList<>();
return list;
}
@Override
public void write(List<Serializable> data) throws Exception {
}
}
public class TemplateFactory {
public static Template create(Type type){
Template template = null;
switch (type){
case EXCEL:
template = new ExcelTemplate();
break;
}
return template;
}
public static void main(String[] args) {
Template template = TemplateFactory.create(Type.EXCEL);
template.read(input);
template.write(data);
}
}
这样就完成了工厂模式对报表导出的改造,在业务方法内,通过 TemplateFactory 创建 template,然后调用 template 的 read 或 write 方法,以后我们每增加一个格式,只需要实现 Template 的相应方法,在 factory 实例化它即可,无需修改业务方法。
此场景用到的设计模式有:简单工厂模式。
这种场景也比较多见,比如:
针对这些情况,一般做法也是在业务方法内,做个 if - else 判断,如果是第一步,则执行第一步的业务,如果是第二步,则执行第二步的业务,这种方式同场景 1 一样,代码也比较难看。
对于这样的场景,我们同样可以使用设计模式来实现,因为每一步都是有关联的,执行完第一步,才能执行第二步,执行完第二步才能执行第三步,它很像一条链子将它们联系起来,所以很容易想到可以采用责任链模式。
下面,请看具体的实现:
public abstract class Handler {
protected Handler handler;
public void setHandler(Handler handler) {
this.handler = handler;
}
public abstract void handleRequest();
}
public class StepOneHandler extends Handler {
@Override
public void handleRequest() {
if(this.handler != null){
this.copy(this.handler);
this.handler.handleRequest();
}else{
//执行第一步的方法
}
}
}
public class StepOneHandler extends Handler {
@Override
public void handleRequest() {
if(this.handler != null){
this.copy(this.handler);
this.handler.handleRequest();
}else{
//执行第一步的方法
}
}
}
public class HandlerFactory {
public static Handler create(int step){
Handler handler = null;
switch (request.getStep()){
case 1:
handler = new StepOneHandler();
break;
case 2:
Handler stepTwoHandler = new StepTwoHandler();
handler.setHandler(stepTwoHandler);
break;
default:
break;
}
return handler;
}
public static void main(String[] args) {
Handler handler = HandlerFactory.create(step);
handler.handleRequest();
}
}
业务类传入一个 step,通过 HandlerFactory 实例化 handler,通过 handler 就可以执行指定的步骤,同样地,增加一个步骤,业务类无需任何变动。
有些时候,我们会使用多重循环,直接带业务方法里写,看着很不优雅,就像这样:
for (int i = 0;i < list.size();i++){
for (int j = 0;j < list.size();j++){
for (int k = 0;k < list.size();k++){
}
}
}
我们可以将其进行封装改造,将循环细节封装起来,只将一些方法暴露给业务方调用:
public class Lists {
public static void main(String[] args) {
List<Object> list1 = new ArrayList<>();
list1.add("1");
list1.add("1");
List<Object> list2 = new ArrayList<>();
list2.add("2");
list2.add("2");
List<Object> list3 = new ArrayList<>();
list3.add("3");
list3.add("3");
//通过这样的方式,使代码更加优雅,更加清晰,调用方无需理解循环细节
Lists.forEach(list1,list2,list3).then(new Each() {
@Override
public void test(Object... items) {
System.out.println(items[0]+"t"+items[1]+"t"+items[2]);
}
});
}
private List[] lists;
public static class Builder{
private List[] lists;
public Builder setLists(List[] lists){
this.lists = lists;
return this;
}
//通过构建者实例化Lists类
public Lists build(){
return new Lists(this);
}
}
private Lists(Builder builder){
this.lists = builder.lists;
}
/**
*
* @param lists
* @return
*/
public static Lists forEach(List...lists){
return new Lists.Builder().setLists(lists).build();
}
public void then(Each each){
if(null != lists && lists.length > 0){
List list1 = lists[0];
for (int i = 0;i < list1.size() ;i++){
List list2 = lists[1];
for(int j = 0;j < list2.size();j++){
List list3 = lists[2];
for(int k = 0;k < list3.size();k++){
each.test(list1.get(i),list2.get(j),list3.get(k));
}
}
}
}
}
//设置观察者
public interface Each{
void test(Object...items);
}
}
上面的 main 方法就是我们业务调用时需要调用的方法,可以看出,我们将循环细节封装到 Lists 里面,使调用方的代码更加优雅。
此场景用到的设计模式有:构建者模式、观察者模式。
在实际应用中,我们看到最多的代码便是 if - else,这样的代码在业务场景中出现太多的话,看着就不太优雅了,前面的场景其实已经多次将 if - else 用设计模式替换,本场景,我将会用新的设计模式来替换讨厌的 if - else,那就是策略模式。
策略模式,通俗点讲,就是根据不同的情况,采取不同的策略,我们把它转化成 if - else,即:
if(情况1){
执行策略1
}else if(情况2){
执行策略2
}
public interface Strategy {
/**
* 策略方法
*/
void strategyInterface();
}
public class ConcreteStrategyA implements Strategy{
@Override
public void strategyInterface() {
System.out.println("实现策略1");
}
}
public class Context {
//持有一个具体策略的对象
private Strategy strategy;
/**
* 构造函数,传入一个具体策略对象
* @param strategy 具体策略对象
*/
public Context(Strategy strategy){
this.strategy = strategy;
}
/**
* 策略方法
*/
public void contextInterface(){
strategy.strategyInterface();
}
public static void executeStrategy(int type){
Strategy strategy = null;
if(type == 1){
strategy = new ConcreteStrategyA();
}
Context context = new Context(strategy);
context.contextInterface();
}
public static void main(String[] args) {
Context.executeStrategy(1);
}
}
这样,我们就避免了在业务场景中大量地使用 if - else 了。
通过以上的学习,我们其实是可以写出很多优雅的代码,各位在实际中如果有什么问题,或者在实际应用中发现一段代码不知道如何优化也可以再本 chat 的读者圈随时向我提问。
接下来,我将告诉大家一些 Java 编程的小技巧,利用这些技巧,可以避免一些低级 bug,也可以写出一些优雅的代码。
我们在集成一个类时,可能会重写父类方法,大家务必加上 Override 注解,请看下面的代码:
public class Parent {
public void method(int type){
}
}
public class Son extends Parent{
public void method(String type) {
}
}
我们的本意是要重写 method,但是参数类型写错了,变成了重载,编译器不会报错,如果我们加上 @Override,编译器会报错,我们就能马上发现代码的错误,而避免运行一段时间导致的 bug。
为什么这么说呢?错误我们马上就能发现,而且如果是编译时错误,都无法运行,但是警告并不影响编译和运行,举个例子:
int i = 0;
for(int j = 0;j < 10;j++){
}
我的本意是 for 循环用 i,但是却写成了 j,这时编译不会报错,但是 IDE 会给出警告:
它告诉我们i这个变量没有使用到,如果忽略警告,那么很可能运行一段时间出现致命性的 bug,但是如果我们重视警告,当编译器提出这个警告时,我们就会想,i为什么没有用到呢,检查代码,马上就能发现隐藏的 bug。
在开发数据库项目时,经常会有一些譬如状态、类型、性别等具有固定值的字段,一般我们会用数字表示,在业务中,也会经常判断,比如状态为 1 时,执行什么操作,如果直接这样写数字,必须要写注释,否则很难懂。类似这种字段,尽量封装成枚举类型,如:
/**
* 验证码类型(1、注册2、动态码登录3、修改密码4、忘记密码)
*/
public enum CaptchaType {
/**
* 注册
*/
REGISTER(1),
/**
* 动态码登录
*/
DYNAMIC(2),
/**
* 修改密码
*/
UPDATE_PASSWORD(3),
/**
* 忘记密码
*/
FORGET_PASSWORD(4);
private int type;
CaptchaType(int type){
this.type = type;
}
public int getType() {
return type;
}
}
我们在使用时直接调用枚举,可读性增加了,也利于扩展。
小王是公司的 Android 开发工程师,在开发应用时,封装了一些常量,用于提示语。
架构师在 code review 时发现,变量命名很成问题,如:
String MSG0001 = "网络有问题,请检查网络设置!";
架构师要求小王更正,但小王给我的理由是这种编码是产品经理定的,我可以在每个调用者上面加上注释,而保留现状。
很明显,这样的代码是不可取的,如果换成一个可读变量名是不是更清晰呢?比如:
String NET_CONNECT_ERROR = "网络有问题,请检查网络设置!";
这个原则很好理解,即一个方法只做一件事,如果一个方法做了太多的事,请考虑重构此方法,合理运用类似上面提到的设计模式。
下面对两种代码进行比较:
if("1".equals(type)){}
if(type.equals("1")){}
如果变量放在前面,一旦变量为 null,则会出现空指针异常,但是常量放在前面,则不会出现空指针异常。
各位看到网上经常再说,位运算效率高怎么怎么样的,但事实真的如此吗,我们不妨做个测试:
long start = System.currentTimeMillis();
for (int i = 0;i < 1000000;i++){
int sum = i * 2;
}
long end = System.currentTimeMillis();
System.out.println((end - start)+"ms");
start = System.currentTimeMillis();
for (int i = 0;i < 1000000;i++){
int sum = i >> 1;
}
end = System.currentTimeMillis();
System.out.println((end - start)+"ms");
以上代码,我分别测试了 1 万次,10 万次和 100 万次,得出的结论是 1 万次速度一样,10 万次和 100 万次都只相差 2 毫秒,如今计算机计算性能越来越好,利用位运算和四则运算效率相差太小,而位运算的可读性非常低,除非有详细的注释,否则一般人真看不懂。
因此,尽量少用位运算。当然有些场景是避免不了的,比如:密码生成、图像处理等,但实际应用中,我们很少自己写这类算法。
我们如果要精确计算浮点数,切记不要用 float 和 double,它们的计算结果往往不是你想要的,比如:
double a = 11540.0;
double b = 0.35;
System.out.println(a * b);
计算结果为:
4038.9999999999995
我们要精确计算,需要用 BigDecimal 类,如:
double a = 11540.0;
double b = 0.35;
BigDecimal a1 = new BigDecimal(a+"");
BigDecimal b1 = new BigDecimal(b+"");
System.out.println(a1.multiply(b1));
这样就能得出精确的值:
4039.000
java8 为我们带来了 lambda 表达式,也带来了集合的流式运算,java8 以前,我们循环集合是这样的:
for (int i = 0;i < list.size() ;i++){
}
java8 以后,我们可以这样做:
list.stream().forEach(item -> {
//TODO write your code here
});
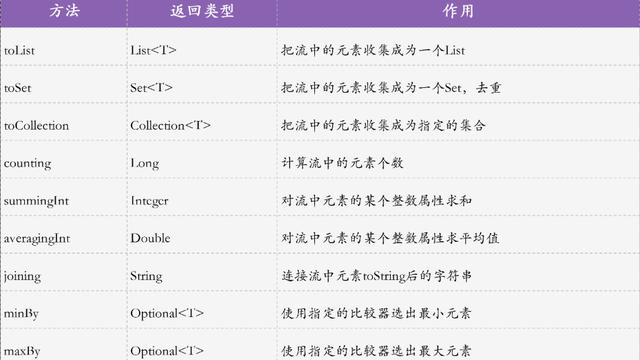
通过集合的流式操作,我们可以很方便的过滤元素、分组、排序等,如:
//表示筛选元素不为null的
list.stream().filter(item -> item != null).forEach(item -> {
});
//集合排序
list.stream().sorted(((o1, o2) -> {
return o1 > o2;
}));
除了,集合的流式操作,通过 lambda 表示,我们还可以实例化匿名类,如:
new Thread(()->{
//TODO write your code
}).start();
//上下两段代码是一样的效果
new Thread(new Runnable() {
@Override
public void run() {
}
}).start();
可以看出,使用 lambda 表达式,让我们的代码更加简洁,也更加优雅,同学们,请拥抱 lambda 吧!