
JAVA虚拟机(JVM)是一个运行时环境,可以执行用Java编程语言编写的程序。Java语言是一种高级语言,它通过抽象和封装的机制,让开发者可以专注于业务逻辑和功能实现,而不用关心底层的细节。因此,运行/开发Java程序时,不必深入了解Java程序的执行过程或JVM的内部原理。对于大多数开发者来说,JVM就像一个神奇的盒子,能够帮助他们实现功能和完成任务。
但是,了解JVM是如何支持Java语言和其他相关语言的,对于程序员来说是很有裨益的!

本文分享一下Java的工作原理和JVM的内部结构。
Java虚拟机(JVM)是一个抽象的机器,用来执行一种代码,即bytecode。你可以把它看作是我们的代码和计算机硬件之间的桥梁,它把我们的代码作为输入,转换成字节码并在计算机硬件上运行它,从而实现开发者预期的结果。
字节码是一种JVM能够理解的文件类型。它是通过compilingJava代码(使用javac)生成的一种Java程序的中间表示形式。它之所以叫字节码,是因为每个操作码(operation)都是单字节大小的。字节码可以再次编译成机器码并在计算机上运行。
运行Java程序的第一步是编译。如果你有一个单独的Java文件,你可以使用提供的命令行工具javac来触发编译。
javac HelloWorld.java

上面代码会把一个给定的Java文件编译成.class文件,其中包含bytecode。如果源代码有错误,编译会失败并报出编译错误。
你可以使用提供的工具javap来查看已创建的类文件,以了解类文件的内部情况。
javap HelloWorld.class
在通过编译创建了.class文件之后,可以使用java语法来启动一个JVM的实例,它会触发一个包含多个复杂步骤的执行路径,最终执行我们提供的代码。
java HelloWorld
首先JVM需要获取.class文件,并将它加载到JVM的内存区域中。这个初始过程是通过JVM类加载器来实现的。
抽象地说,类加载就是扫描并遍历提供的.class文件,并将类文件中的内容加载到JVM的内存区域中。然后,执行引擎就可以引用这些存储的数据,继续执行我们的代码。
JVM中有三种类型的类加载器,分别是:
引导类加载器的职责是加载基础/核心的Java类,这些类对于Java程序运行是必不可少的。在早期的Java版本中,这些核心类被包含在位于jre/lib目录下的rt.jar文件中,但在后来的Java版本中,rt.jar中的内容被分割成模块化的组件。
扩展类加载器的职责是加载lib/ext目录下的类,这些类可能包括我们在代码中使用的任何扩展。
应用类加载器是三种中最常用的一种,它负责加载用户定义的类。它会扫描我们程序的类路径,并加载其中的类。
类加载过程有两个主要步骤:
在加载过程中,类加载器读取类文件的二进制表示形式,即.class文件,并在JVM的运行时内存中创建它的表示。这个表示称为Class Object,它位于JVM内存的方法区中。
在加载过程之后,开始链接。链接有三个步骤。
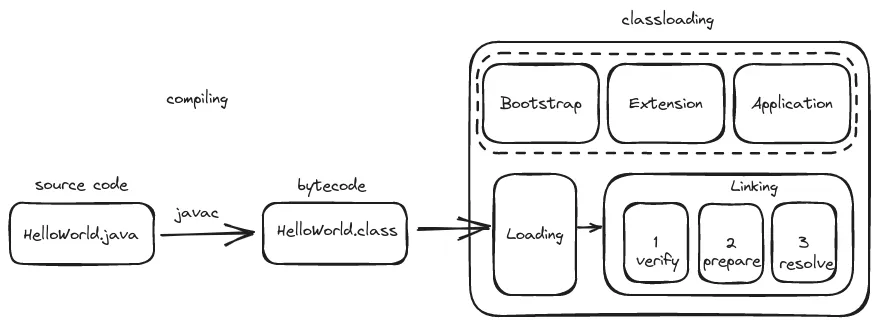
解析
在链接的解析阶段,类加载器会解析常量池表,这是一个位于.class文件/类对象中的实体,类似于一个符号表,指定了类中的字段/方法/引用。在类文件中,对其他类的引用是以符号方式表示的,没有具体的内存地址来引用。解析会搜索JVM内存,并为那些符号引用分配具体的引用。如果在.class文件中发现了一个尚未加载的类,它会触发该类本身的加载/链接过程,这可能会导致一个递归的加载和链接过程。
在字节码加载和链接之后,类就成功地存储在JVM内存中(将在后面的部分讨论),并准备好初始化。
当代码中第一次用new关键字或静态字段来引用一个类,或者当程序执行时遇到一个初始化类(比如MAIn类),则会触发类文件的初始化。
在初始化阶段,执行静态块,静态变量被分配初始值。
在上面的段落中,多次提到了将类文件数据存储在JVM内存中。这些数据究竟存储在哪里,来作为加载/链接/初始化的结果?答案是运行时内存区域。
JVM运行时内存区域是指定的内存空间,它被划分为多个部分,用于存储执行相关/类文件相关的数据。
运行时内存区的主要区域如下:
方法区是运行时内存的一部分,用于存储与类文件相关的数据。运行时常量池、字段元数据、类元数据、方法元数据和字节码本身等都存储在方法区中。
程序计数器是一个小的内存区域,用于存储当前正在执行的操作的地址,这是Java程序执行的必要信息。每个线程都有自己的PC。
存储所有的类/数组实例,是所有线程共享的一块内存。
保存局部变量和部分结果。包含栈帧。每个线程都有自己的JVM栈。
当一个方法被调用时,在栈中创建一个新的帧。它会存储与该方法相关的局部变量和部分结果。如果在该方法内部调用了另一个方法,就会为新调用的方法创建一个新的栈帧。在给定线程中,一次只有一个帧是活动的。
在上面的部分中,简要地介绍了Java源代码是如何编译并加载到JVM运行时内存区域中的。
接下来看看这些数据是如何执行的。
这部分过程是通过JVM的执行引擎来实现的,它由两个主要部分组成:(执行引擎还包括许多其他组件,但在本文中不会提及。)
“Java作为一种编程语言,是一种混合的解释和编译语言,也就是说Java代码既要经过编译,又要经过解释。简单来说,当类文件开始运行时,JVM会先用解释器直接执行字节码,不需要编译。这样做的主要好处是可以提高启动速度和执行速度(不用等待编译过程)。
在解释的过程中,JVM会发现代码中的热点和热区,也就是经常执行或者可以优化的代码段。这些代码段会被JIT编译器编译成本地代码,然后执行引擎会从解释模式切换到执行模式。”
这个编译过程有多个层次,称为分层编译。


























