
我们以Python Pandas数据加载类型表格为例,演示Python Pandas Excel操作。

本文将使用Pandas中 read_excel 函数来读取 Excel 文件,并存储成DataFrame格式,本文将介绍如何使用 iloc 、loc 方法获取 DataFrame中对应的数据,实现Execl数据的获取。
根据上述参数介绍,我们通过指定表单名和指定列的方式来读取文件
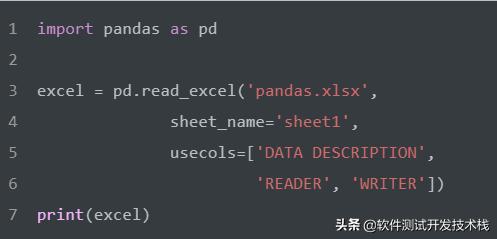
如下,我们可以看到读取的Excel数据类型为DataFrame类型:

iloc 语法
data.iloc[<row selection>, <column selection>]
iloc 在Pandas中是用来通过数字来选择数据中具体的某些行和列。可以设想每一行都有一个对应的下标(0,1,2,...),通过 iloc 我们可以利用这些下标去选择对应的行数据。同理,对于行也一样,通过这些下标也可以选择对应的列数据。
需要注意的是0表示第一行,但不包含表头。
选择单行或单列
选择数据中的第一行。

选择数据中的最后一行。

选择数据中的第一列。

选择数据中的最后一列。
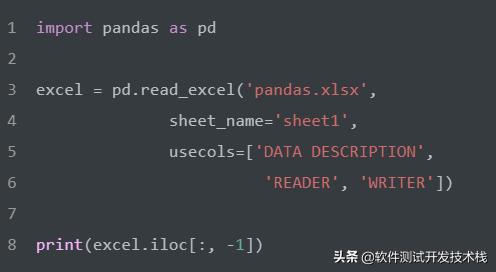
行列混合选择
选择数据中的第 1-3 行的所有列。

选择数据中的前2列的所有行。

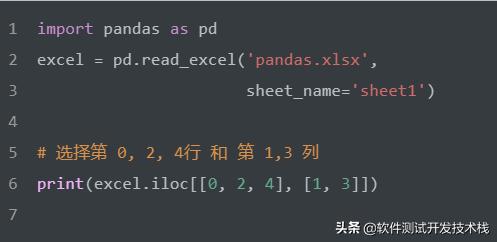
选择第 0, 2, 4行 和 第 1,3 列。
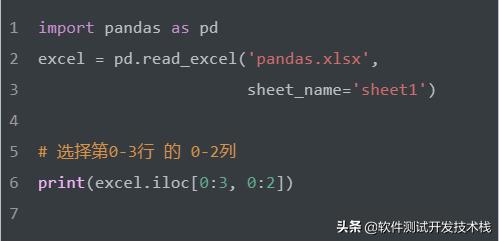
选择第0 到 第3行 的 第0 到第2列。
使用 iloc 仅选择了单独的一行或一列,返回的数据为 Series 类型。若选择了多行数据则会返回 DataFrame 类型,若只选择了一行,但需要要返回 DataFrame 类型,可以传入一个单值列表,如[1],如下:

data.loc[<row selection>, <column selection>]
ioc 用于以下两种场景:
使用 下标 查找
选择数据中的第一行。
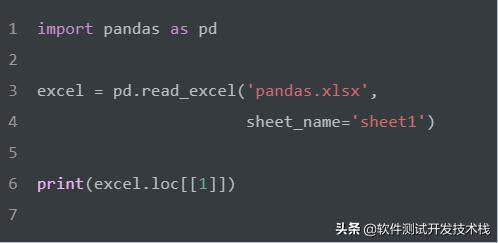
选择数据中的前二行。

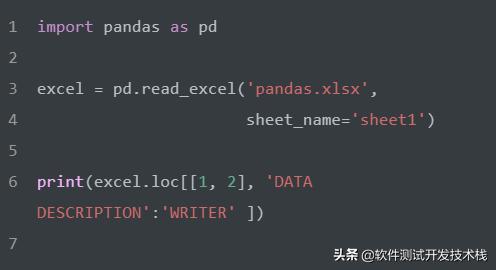
选择第1到3行的 READER、WRITER列。

选择第1、2行的 DATA DESCRIPTION 到 WRITER列。
需要注意 excel.loc[[1]] 不等价于 excel.iloc[[1]] ,前者是选择索引为1的行,而后者是选择第1行,DataFrame的索引可以是数字或者是字符串。
使用逻辑判断选择数据
选择WRITER列等于to_json的 DATA DESCRIPTION列到 WRITER列。

同样,如果只选择了某一列,返回的数据是 Series 类型,若只选择了一行,但需要要返回 DataFrame 类型,可以传入一个单值列表,如[1]。
选择 READER的值中是以 "read" 开头的行的所有列。

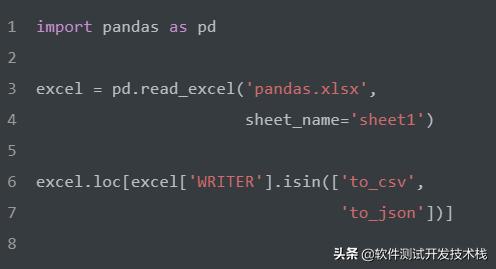
选择"WRITER" 等于['to_csv', 'to_json']值的行。
选择READER = 'read_csv' 并且 READER 是以 "read"开头的行。

利用Apply的lambda函数判断符合条件的行,如下选择READER由“_”链接的行的所有列。

利用apply的lambda函数判断符合条件的行的'DATA DESCRIPTION', 'READER' 列。


















