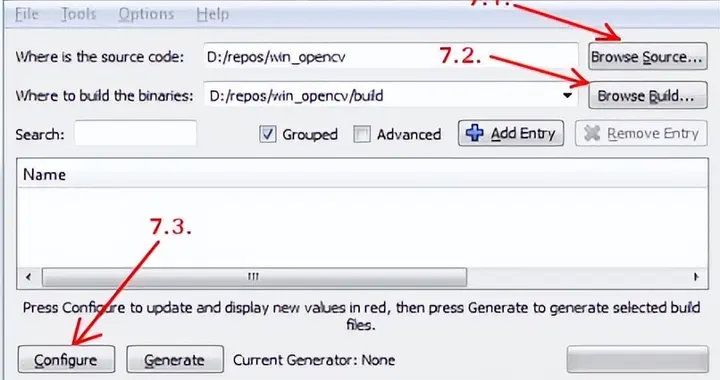
在这一章当中,
在上一章中,我们看到了SIFT用于关键点检测和描述符。但相对缓慢,人们需要更多的加速版本。2006年,三个人,H .Tuytelaars,T. and Van Gool,L,发表了另一篇论文,“SURF:加速健壮的特征”,引入了一种名为“SURF”的新算法。正如名字所表明的那样,它是一个加速版本的SIFT。
在SIFT中,Lowe用高斯差近似高斯的拉普拉斯算子来寻找尺度空间。SURF走得更远,使用Box Filter近似LoG。下图显示了这种近似值的演示。这种近似的一大优点是,借助积分图像可以轻松地计算出带盒滤波器的卷积。并且可以针对不同规模并行执行。SURF还依赖于Hessian矩阵的行列式来确定尺度和位置。
对于方向分配,SURF在水平和垂直方向上对大小为6s的邻域使用小波响应。适当的高斯权重也适用于它。然后将它们绘制在下图所示的空间中。通过计算角度为60度的滑动方向窗口内所有响应的总和,可以估算主导方向。有趣的是,小波响应可以很容易地使用积分图像在任何规模下发现。对于许多应用,不需要旋转不变性,因此无需查找此方向,从而加快了过程。SURF提供了称为Upright-SURF或U-SURF的功能。它提高了速度,并具有高达$pm 15^{circ}$的鲁棒性。OpenCV根据标志支持两种方式。如果为0,则计算方向。如果为1,则不计算方向并且速度更快。
对于功能描述,SURF在水平和垂直方向上使用小波响应(同样,使用积分图像使事情变得更容易)。在s是大小的关键点周围采用大小为20sX20s的邻域。它分为4x4子区域。对于每个子区域,获取水平和垂直小波响应,并像这样形成向量,$v =(sum dx,sum dy,sum |dx|,sum |dy|)$。当表示为向量时,这将为SURF特征描述符提供总共64个维度。尺寸越小,计算和匹配速度越快,但特征的区分性更好。
为了更加独特,SURF特征描述符具有扩展的128维版本。dx和$|dx|$的和分别针对$dy < 0$ 和 $dy≥0$进行计算。同样,$dy$和$|dy|$的总和 根据$dx$的符号进行拆分,从而使特征数量加倍。它不会增加太多的计算复杂性。OpenCV通过将分别为64-dim和128-dim(默认值为128-dim)的标志的值设置为0和1来支持这两者(默认为128-dim)。
另一个重要的改进是对基础兴趣点使用了Laplacian算符(海森矩阵的迹)。它不增加计算成本,因为它已在检测期间进行了计算。拉普拉斯算子的标志将深色背景上的明亮斑点与相反的情况区分开。在匹配阶段,我们仅比较具有相同对比类型的特征(如下图所示)。这些最少的信息可加快匹配速度,而不会降低描述符的性能。
简而言之,SURF添加了许多功能来提高每一步的速度。分析表明,它的速度是SIFT的3倍,而性能却与SIFT相当。SURF擅长处理具有模糊和旋转的图像,但不擅长处理视点变化和照明变化。
OpenCV提供类似于SIFT的SURF功能。您可以使用一些可选条件(例如64 / 128-dim描述符,Upright / Normal SURF等)来启动SURF对象。所有详细信息在docs中都有详细说明。然后,就像在SIFT中所做的那样,我们可以使用SURF.detect(),SURF.compute()等来查找关键点和描述符。
首先,我们将看到一个有关如何找到SURF关键点和描述符并进行绘制的简单演示。所有示例都在Python终端中显示,因为它与SIFT相同。
>>> img = cv.imread('fly.png',0)
# 创建SURF对象。你可以在此处或以后指定参数。
# 这里设置海森矩阵的阈值为400
>>> surf = cv.xfeatures2d.SURF_create(400)
# 直接查找关键点和描述符
>>> kp, des = surf.detectAndCompute(img,None)
>>> len(kp)
699
图片中无法显示1199个关键点。我们将其减少到50左右以绘制在图像上。匹配时,我们可能需要所有这些功能,但现在不需要。因此,我们增加了海森阈值。
# 检查海森矩阵阈值
>>> print( surf.getHessianThreshold() )
400.0
# 我们将其设置为50000。记住,它仅用于表示图片。
# 在实际情况下,最好将值设为300-500
>>> surf.setHessianThreshold(50000)
# 再次计算关键点并检查其数量。
>>> kp, des = surf.detectAndCompute(img,None)
>>> print( len(kp) )
47
它小于50。让我们在图像上绘制它。
>>> img2 = cv.drawKeypoints(img,kp,None,(255,0,0),4)
>>> plt.imshow(img2),plt.show()
请参阅下面的结果。您可以看到SURF更像是斑点检测器。它检测到蝴蝶翅膀上的白色斑点。您可以使用其他图像进行测试。
现在,我想应用U-SURF,以便它不会找到方向。
# 检查flag标志,如果为False,则将其设置为True
>>> print( surf.getUpright() )
False
>>> surf.setUpright(True)
# 重新计算特征点并绘制
>>> kp = surf.detect(img,None)
>>> img2 = cv.drawKeypoints(img,kp,None,(255,0,0),4)
>>> plt.imshow(img2),plt.show()
参见下面的结果。所有的方向都显示在同一个方向上。它比以前更快了。如果你工作的情况下,方向不是一个问题(如全景拼接)等,这是更好的。
最后,我们检查描述符的大小,如果只有64维,则将其更改为128。
# 找到算符的描述
>>> print( surf.descriptorSize() )
64
# 表示flag “extened” 为False。
>>> surf.getExtended()
False
# 因此,将其设为True即可获取128个尺寸的描述符。
>>> surf.setExtended(True)
>>> kp, des = surf.detectAndCompute(img,None)
>>> print( surf.descriptorSize() )
128
>>> print( des.shape )
(47, 128)
其余部分是匹配的,我们将在另一章中进行匹配。
在本章中,
我们看到了几个特征检测器,其中很多真的很棒。但是,从实时应用程序的角度来看,它们不够快。最好的例子是计算资源有限的SLAM(同时定位和制图)移动机器人
作为对此的解决方案,Edward Rosten和Tom Drummond在2006年的论文“用于高速拐角检测的机器学习”中提出了FAST(加速分段测试的特征)算法(后来在2010年对其进行了修订)。该算法的基本内容如下。有关更多详细信息,请参阅原始论文(所有图像均取自原始论文)。
机器学习的方法解决了前三点。使用非最大抑制来解决最后一个问题。
在相邻位置检测多个兴趣点是另一个问题。通过使用非极大抑制来解决。
它比其他现有的拐角检测器快几倍。
但是它对高水平的噪声并不鲁棒。它取决于阈值。
它被称为OpenCV中的任何其他特征检测器。如果需要,您可以指定阈值,是否要应用非极大抑制,要使用的邻域等。对于邻域,定义了三个标志,分别为
cv.FAST_FEATURE_DETECTOR_TYPE_5_8,cv.FAST_FEATURE_DETECTOR_TYPE_7_12和cv.FAST_FEATURE_DETECTOR_TYPE_9_16。以下是有关如何检测和绘制FAST特征点的简单代码。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('simple.jpg',0)
# 用默认值初始化FAST对象
fast = cv.FastFeatureDetector_create()
# 寻找并绘制关键点
kp = fast.detect(img,None)
img2 = cv.drawKeypoints(img, kp, None, color=(255,0,0))
# 打印所有默认参数
print( "Threshold: {}".format(fast.getThreshold()) )
print( "nonmaxSuppression:{}".format(fast.getNonmaxSuppression()) )
print( "neighborhood: {}".format(fast.getType()) )
print( "Total Keypoints with nonmaxSuppression: {}".format(len(kp)) )
cv.imwrite('fast_true.png',img2)
# 关闭非极大抑制
fast.setNonmaxSuppression(0)
kp = fast.detect(img,None)
print( "Total Keypoints without nonmaxSuppression: {}".format(len(kp)) )
img3 = cv.drawKeypoints(img, kp, None, color=(255,0,0))
cv.imwrite('fast_false.png',img3)
查看结果。第一张图片显示了带有nonmaxSuppression的FAST,第二张图片显示了没有nonmaxSuppression的FAST:
在本章中,我们将看到BRIEF算法的基础知识
我们知道SIFT使用128维矢量作为描述符。由于它使用浮点数,因此基本上需要512个字节。同样,SURF最少也需要256个字节(用于64像素)。为数千个功能部件创建这样的向量会占用大量内存,这对于资源受限的应用程序尤其是嵌入式系统而言是不可行的。内存越大,匹配所需的时间越长。
但是实际匹配可能不需要所有这些尺寸。我们可以使用PCA,LDA等几种方法对其进行压缩。甚至使用LSH(局部敏感哈希)进行哈希的其他方法也可以将这些SIFT描述符中的浮点数转换为二进制字符串。这些二进制字符串用于使用汉明距离匹配要素。这提供了更快的速度,因为查找汉明距离仅是应用XOR和位数,这在具有SSE指令的现代CPU中非常快。但是在这里,我们需要先找到描述符,然后才可以应用散列,这不能解决我们最初的内存问题。
现在介绍BRIEF。它提供了一种直接查找二进制字符串而无需查找描述符的快捷方式。它需要平滑的图像补丁,并以独特的方式(在纸上展示)选择一组$nd(x,y)$位置对。然后,在这些位置对上进行一些像素强度比较。例如,令第一位置对为$p$和$q$。如果$I(p)< I(q)$,则结果为1,否则为0。将其应用于所有$nd$个位置对以获得$n_d$维位串。
该$n_d$可以是128、256或512。OpenCV支持所有这些,但默认情况下将是256(OpenCV以字节为单位表示,因此值将为16、32和64)。因此,一旦获得此信息,就可以使用汉明距离来匹配这些描述符。
重要的一点是,BRIEF是特征描述符,它不提供任何查找特征的方法。因此,您将不得不使用任何其他特征检测器,例如SIFT,SURF等。本文建议使用CenSurE,它是一种快速检测器,并且BIM对于CenSurE点的工作原理甚至比对SURF点的工作要好一些。
简而言之,BRIEF是一种更快的方法特征描述符计算和匹配。除了平面内旋转较大的情况,它将提供很高的识别率。
下面的代码显示了借助CenSurE检测器对Brief描述符的计算。(在OpenCV中,CenSurE检测器称为STAR检测器)注意,您需要使用opencv contrib)才能使用它。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('simple.jpg',0)
# 初始化FAST检测器
star = cv.xfeatures2d.StarDetector_create()
# 初始化BRIEF提取器
brief = cv.xfeatures2d.BriefDescriptorExtractor_create()
# 找到STAR的关键点
kp = star.detect(img,None)
# 计算BRIEF的描述符
kp, des = brief.compute(img, kp)
print( brief.descriptorSize() )
print( des.shape )
函数brief.getDescriptorSize()给出以字节为单位的$n_d$大小。默认情况下为32。下一个是匹配项,这将在另一章中进行。
在本章中,我们将了解ORB的基础知识
作为OpenCV的狂热者,关于ORB的最重要的事情是它来自“ OpenCV Labs”。该算法由Ethan Rublee,Vincent Rabaud,Kurt Konolige和Gary R. Bradski在其论文《ORB:SIFT或SURF的有效替代方案》中提出。2011年,正如标题所述,它是计算中SIFT和SURF的良好替代方案成本,匹配性能以及主要是专利。是的,SIFT和SURF已获得专利,你应该为其使用付费。但是ORB不是!!!
ORB基本上是FAST关键点检测器和Brief描述符的融合,并进行了许多修改以增强性能。首先,它使用FAST查找关键点,然后应用Harris角测度在其中找到前N个点。它还使用金字塔生成多尺度特征。但是一个问题是,FAST无法计算方向。那么旋转不变性呢?作者提出以下修改。
它计算角点位于中心的贴片的强度加权质心。从此角点到质心的矢量方向确定了方向。为了改善旋转不变性,使用x和y计算矩,它们应该在半径$r$的圆形区域中,其中$r$是斑块的大小。
现在,对于描述符,ORB使用Brief描述符。但是我们已经看到,BRIEF的旋转性能很差。因此,ORB所做的就是根据关键点的方向“引导” BRIEF。对于位置$(xi,yi)$上n个二进制测试的任何特征集,定义一个$2×n$矩阵S,其中包含这些像素的坐标。然后使用面片的方向$θ$,找到其旋转矩阵并旋转$S$以获得转向(旋转)版本S_θ。
ORB将角度离散化为frac{2π}{30}(12度)的增量,并构造了预先计算的Brief模式的查找表。只要关键点方向$θ$在各个视图中一致,就将使用正确的点集$S_θ$来计算其描述符。
BRIEF具有一个重要的特性,即每个位特征具有较大的方差,且均值接近0.5。但是,一旦沿关键点方向定向,它就会失去此属性,变得更加分散。高方差使功能更具区分性,因为它对输入的响应不同。另一个理想的特性是使测试不相关,因为从那时起每个测试都会对结果有所贡献。为了解决所有这些问题,ORB在所有可能的二进制测试中进行贪婪搜索,以找到方差高且均值接近0.5且不相关的测试。结果称为rBRIEF。
对于描述符匹配,使用了对传统LSH进行改进的多探针LSH。该论文说,ORB比SURF快得多,而SIFT和ORB描述符比SURF更好。在全景拼接等低功耗设备中,ORB是一个不错的选择。
与往常一样,我们必须使用函数cv.ORB()或使用feature2d通用接口来创建ORB对象。它具有许多可选参数。最有用的是nFeatures,它表示要保留的最大特征数(默认为500),scoreType表示是对特征进行排名的Harris分数还是FAST分数(默认为Harris分数)等。另一个参数WTAK决定点数产生定向的BRIEF描述符的每个元素。默认情况下为两个,即一次选择两个点。在这种情况下,为了匹配,将使用NORMHAMMING距离。如果WTAK为3或4,则需要3或4个点来生成Brief描述符,则匹配距离由NORMHAMMING2定义。下面是显示ORB用法的简单代码。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('simple.jpg',0)
# 初始化ORB检测器
orb = cv.ORB_create()
# 用ORB寻找关键点
kp = orb.detect(img,None)
# 用ORB计算描述符
kp, des = orb.compute(img, kp)
# 仅绘制关键点的位置,而不绘制大小和方向
img2 = cv.drawKeypoints(img, kp, None, color=(0,255,0), flags=0)
plt.imshow(img2), plt.show()
查看以下结果:
ORB特征匹配,我们将在另一章中进行。
在本章中,
蛮力匹配器很简单。它使用第一组中一个特征的描述符,并使用一些距离计算将其与第二组中的所有其他特征匹配。并返回最接近的一个。
对于BF匹配器,首先我们必须使用cv.BFMatcher()创建BFMatcher对象。它需要两个可选参数。第一个是normType,它指定要使用的距离测量。默认情况下为cv.NORM_L2。对于SIFT,SURF等(也有cv.NORM_L1)很有用。对于基于二进制字符串的描述符,例如ORB,BRIEF,BRISK等,应使用cv.NORM_HAMMING,该函数使用汉明距离作为度量。如果ORB使用WTA_K == 3或4,则应使用cv.NORM_HAMMING2。
第二个参数是布尔变量,即crossCheck,默认情况下为false。如果为true,则Matcher仅返回具有值(i,j)的那些匹配项,以使集合A中的第i个描述符具有集合B中的第j个描述符为最佳匹配,反之亦然。即两组中的两个特征应彼此匹配。它提供了一致的结果,并且是D.Lowe在SIFT论文中提出的比率测试的良好替代方案。
创建之后,两个重要的方法是BFMatcher.match()和BFMatcher.knnMatch()。第一个返回最佳匹配。第二种方法返回k个最佳匹配,其中k由用户指定。当我们需要对此做其他工作时,它可能会很有用。
就像我们使用cv.drawKeypoints()绘制关键点一样,cv.drawMatches()可以帮助我们绘制匹配项。它水平堆叠两张图像,并绘制从第一张图像到第二张图像的线,以显示最佳匹配。还有cv.drawMatchesKnn绘制所有k个最佳匹配。如果k=2,它将为每个关键点绘制两条匹配线。因此,如果要选择性地绘制,则必须通过掩码。
让我们来看一个SIFT和ORB的示例(两者都使用不同的距离测量)。
在这里,我们将看到一个有关如何在两个图像之间匹配特征的简单示例。在这种情况下,我有一个queryImage和trAInImage。我们将尝试使用特征匹配在trainImage中找到queryImage。(图像是/samples/data/box.png和
/samples/data/boxinscene.png)
我们正在使用ORB描述符来匹配特征。因此,让我们从加载图像,查找描述符等开始。
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
img1 = cv.imread('box.png',cv.IMREAD_GRAYSCALE) # 索引图像
img2 = cv.imread('box_in_scene.png',cv.IMREAD_GRAYSCALE) # 训练图像
# 初始化ORB检测器
orb = cv.ORB_create()
# 基于ORB找到关键点和检测器
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
接下来,我们创建一个距离测量值为cv.NORM_HAMMING的BFMatcher对象(因为我们使用的是ORB),并且启用了CrossCheck以获得更好的结果。然后,我们使用Matcher.match()方法来获取两个图像中的最佳匹配。我们按照距离的升序对它们进行排序,以使最佳匹配(低距离)排在前面。然后我们只抽出前10的匹配(只是为了提高可见度。您可以根据需要增加它)
# 创建BF匹配器的对象
bf = cv.BFMatcher(cv.NORM_HAMMING, crossCheck=True) # 匹配描述符.
matches = bf.match(des1,des2) # 根据距离排序
matches = sorted(matches, key = lambda x:x.distance) # 绘制前10的匹配项
img3 = cv.drawMatches(img1,kp1,img2,kp2,matches[:10],None,flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS) plt.imshow(img3),plt.show()
将获得以下的结果:
matchs = bf.match(des1,des2)行的结果是DMatch对象的列表。该DMatch对象具有以下属性:
这次,我们将使用BFMatcher.knnMatch()获得k个最佳匹配。在此示例中,我们将k = 2,以便可以应用D.Lowe在他的论文中阐述的比例测试。
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
img1 = cv.imread('box.png',cv.IMREAD_GRAYSCALE) # 索引图像
img2 = cv.imread('box_in_scene.png',cv.IMREAD_GRAYSCALE) # 训练图像
# 初始化SIFT描述符
sift = cv.xfeatures2d.SIFT_create()
# 基于SIFT找到关键点和描述符
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
# 默认参数初始化BF匹配器
bf = cv.BFMatcher()
matches = bf.knnMatch(des1,des2,k=2)
# 应用比例测试
good = []
for m,n in matches:
if m.distance < 0.75*n.distance:
good.append([m])
# cv.drawMatchesKnn将列表作为匹配项。
img3 = cv.drawMatchesKnn(img1,kp1,img2,kp2,good,None,flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
plt.imshow(img3),plt.show()
查看以下结果:
FLANN是近似最近邻的快速库。它包含一组算法,这些算法针对大型数据集中的快速最近邻搜索和高维特征进行了优化。对于大型数据集,它的运行速度比BFMatcher快。我们将看到第二个基于FLANN的匹配器示例。
对于基于FLANN的匹配器,我们需要传递两个字典,这些字典指定要使用的算法,其相关参数等。第一个是IndexParams。对于各种算法,要传递的信息在FLANN文档中进行了说明。概括来说,对于SIFT,SURF等算法,您可以通过以下操作:
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
使用ORB时,你可以参考下面。根据文档建议使用带注释的值,但在某些情况下未提供必需的参数。其他值也可以正常工作。
FLANN_INDEX_LSH = 6
index_params= dict(algorithm = FLANN_INDEX_LSH,
table_number = 6, # 12
key_size = 12, # 20
multi_probe_level = 1) #2
第二个字典是SearchParams。它指定索引中的树应递归遍历的次数。较高的值可提供更好的精度,但也需要更多时间。如果要更改值,请传递search_params = dict(checks = 100)
有了这些信息,我们就很容易了。
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
img1 = cv.imread('box.png',cv.IMREAD_GRAYSCALE) # 索引图像
img2 = cv.imread('box_in_scene.png',cv.IMREAD_GRAYSCALE) # 训练图像
# 初始化SIFT描述符
sift = cv.xfeatures2d.SIFT_create()
# 基于SIFT找到关键点和描述符
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
# FLANN的参数
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks=50) # 或传递一个空字典
flann = cv.FlannBasedMatcher(index_params,search_params)
matches = flann.knnMatch(des1,des2,k=2)
# 只需要绘制好匹配项,因此创建一个掩码
matchesMask = [[0,0] for i in range(len(matches))]
# 根据Lowe的论文进行比例测试
for i,(m,n) in enumerate(matches):
if m.distance < 0.7*n.distance:
matchesMask[i]=[1,0]
draw_params = dict(matchColor = (0,255,0),
singlePointColor = (255,0,0),
matchesMask = matchesMask,
flags = cv.DrawMatchesFlags_DEFAULT)
img3 = cv.drawMatchesKnn(img1,kp1,img2,kp2,matches,None,**draw_params)
plt.imshow(img3,),plt.show()
查看以下结果:
在本章节中,我们将把calib3d模块中的特征匹配和findHomography混合在一起,以在复杂图像中找到已知对象。
那么我们在上一环节上做了什么?我们使用了queryImage,找到了其中的一些特征点,我们使用了另一个trainImage,也找到了该图像中的特征,并且找到了其中的最佳匹配。简而言之,我们在另一个混乱的图像中找到了对象某些部分的位置。此信息足以在trainImage上准确找到对象。
为此,我们可以使用calib3d模块中的函数,即cv.findHomography()。如果我们从两个图像中传递点集,它将找到该对象的透视变换。然后,我们可以使用cv.perspectiveTransform()查找对象。找到转换至少需要四个正确的点。
我们已经看到,匹配时可能会出现一些可能影响结果的错误。为了解决这个问题,算法使用RANSAC或LEAST_MEDIAN(可以由标志决定)。因此,提供正确估计的良好匹配称为“内部点”,其余的称为“外部点”。cv.findHomography()返回指定内部和外部点的掩码。
让我们开始吧!!!
首先,像往常一样,让我们在图像中找到SIFT功能并应用比例测试以找到最佳匹配。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
MIN_MATCH_COUNT = 10
img1 = cv.imread('box.png',0) # 索引图像
img2 = cv.imread('box_in_scene.png',0) # 训练图像
# 初始化SIFT检测器
sift = cv.xfeatures2d.SIFT_create()
# 用SIFT找到关键点和描述符
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks = 50)
flann = cv.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1,des2,k=2)
# #根据Lowe的比率测试存储所有符合条件的匹配项。
good = []
for m,n in matches:
if m.distance < 0.7*n.distance:
good.append(m)
现在我们设置一个条件,即至少有10个匹配项(由MIN_MATCH_COUNT定义)可以找到对象。否则,只需显示一条消息,说明没有足够的匹配项。
如果找到足够的匹配项,我们将在两个图像中提取匹配的关键点的位置。他们被传递以寻找预期的转变。一旦获得了这个3x3转换矩阵,就可以使用它将索引图像的角转换为训练图像中的相应点。然后我们画出来。
if len(good)>MIN_MATCH_COUNT:
src_pts = np.float32([ kp1[m.queryIdx].pt for m in good ]).reshape(-1,1,2)
dst_pts = np.float32([ kp2[m.trainIdx].pt for m in good ]).reshape(-1,1,2)
M, mask = cv.findHomography(src_pts, dst_pts, cv.RANSAC,5.0)
matchesMask = mask.ravel().tolist()
h,w,d = img1.shape
pts = np.float32([ [0,0],[0,h-1],[w-1,h-1],[w-1,0] ]).reshape(-1,1,2)
dst = cv.perspectiveTransform(pts,M)
img2 = cv.polylines(img2,[np.int32(dst)],True,255,3, cv.LINE_AA)
else:
print( "Not enough matches are found - {}/{}".format(len(good), MIN_MATCH_COUNT) )
matchesMask = None
最后,我们绘制内部线(如果成功找到对象)或匹配关键点(如果失败)。
draw_params = dict(matchColor = (0,255,0), # 用绿色绘制匹配
singlePointColor = None,
matchesMask = matchesMask, # 只绘制内部点
flags = 2)
img3 = cv.drawMatches(img1,kp1,img2,kp2,good,None,**draw_params)
plt.imshow(img3, 'gray'),plt.show()
请参阅下面的结果。对象在混乱的图像中标记为白色:
背景建模包括两个主要步骤:
第一步,计算背景的初始模型,而在第二步中,更新模型以适应场景中可能的变化。
在本教程中,我们将学习如何使用OpenCV中的BS。
在本教程中,您将学习如何:
在下面,您可以找到源代码。我们将让用户选择处理视频文件或图像序列。在此示例中,我们将使用
cv::BackgroundSubtractorMOG2生成前景掩码。
结果和输入数据将显示在屏幕上。
from __future__ import print_function
import cv2 as cv
import argparse
parser = argparse.ArgumentParser(description='This program shows how to use background subtraction methods provided by
OpenCV. You can process both videos and images.')
parser.add_argument('--input', type=str, help='Path to a video or a sequence of image.', default='vtest.avi')
parser.add_argument('--algo', type=str, help='Background subtraction method (KNN, MOG2).', default='MOG2')
args = parser.parse_args()
if args.algo == 'MOG2':
backSub = cv.createBackgroundSubtractorMOG2()
else:
backSub = cv.createBackgroundSubtractorKNN()
capture = cv.VideoCapture(cv.samples.findFileOrKeep(args.input))
if not capture.isOpened:
print('Unable to open: ' + args.input)
exit(0)
while True:
ret, frame = capture.read()
if frame is None:
break
fgMask = backSub.apply(frame)
cv.rectangle(frame, (10, 2), (100,20), (255,255,255), -1)
cv.putText(frame, str(capture.get(cv.CAP_PROP_POS_FRAMES)), (15, 15),
cv.FONT_HERSHEY_SIMPLEX, 0.5 , (0,0,0))
cv.imshow('Frame', frame)
cv.imshow('FG Mask', fgMask)
keyboard = cv.waitKey(30)
if keyboard == 'q' or keyboard == 27:
break
我们讨论上面代码的主要部分:
#创建背景分离对象
if args.algo == 'MOG2':
backSub = cv.createBackgroundSubtractorMOG2()
else:
backSub = cv.createBackgroundSubtractorKNN()
capture = cv.VideoCapture(cv.samples.findFileOrKeep(args.input))
if not capture.isOpened:
print('Unable to open: ' + args.input)
exit(0)
#更新背景模型
fgMask = backSub.apply(frame)
#获取帧号并将其写入当前帧
cv.rectangle(frame, (10, 2), (100,20), (255,255,255), -1)
cv.putText(frame, str(capture.get(cv.CAP_PROP_POS_FRAMES)), (15, 15),
cv.FONT_HERSHEY_SIMPLEX, 0.5 , (0,0,0))
#展示当前帧和背景掩码
cv.imshow('Frame', frame)
cv.imshow('FG Mask', fgMask)
MOG2方法的程序输出如下所示(检测到灰色区域有阴影):
对于KNN方法,程序的输出将如下所示(检测到灰色区域的阴影):
在本章中,
Meanshift背后的直觉很简单,假设你有点的集合。(它可以是像素分布,例如直方图反投影)。你会得到一个小窗口(可能是一个圆形),并且必须将该窗口移到最大像素密度(或最大点数)的区域。如下图所示:
初始窗口以蓝色圆圈显示,名称为“C1”。其原始中心以蓝色矩形标记,名称为“C1o”。但是,如果找到该窗口内点的质心,则会得到点“C1r”(标记为蓝色小圆圈),它是窗口的真实质心。当然,它们不匹配。因此,移动窗口,使新窗口的圆与上一个质心匹配。再次找到新的质心。很可能不会匹配。因此,再次移动它,并继续迭代,以使窗口的中心及其质心落在同一位置(或在很小的期望误差内)。因此,最终您获得的是一个具有最大像素分布的窗口。它带有一个绿色圆圈,名为“C2”。正如您在图像中看到的,它具有最大的点数。整个过程在下面的静态图像上演示:
因此,我们通常会传递直方图反投影图像和初始目标位置。当对象移动时,显然该移动会反映在直方图反投影图像中。结果,meanshift算法将窗口移动到最大密度的新位置。
要在OpenCV中使用meanshift,首先我们需要设置目标,找到其直方图,以便我们可以将目标反投影到每帧上以计算均值偏移。我们还需要提供窗口的初始位置。对于直方图,此处仅考虑色相。另外,为避免由于光线不足而产生错误的值,可以使用cv.inRange()函数丢弃光线不足的值。
import numpy as np
import cv2 as cv
import argparse
parser = argparse.ArgumentParser(description='This sample demonstrates the meanshift algorithm.
The example file can be downloaded from:
https://www.bogotobogo.com/python/OpenCV_Python/images/mean_shift_tracking/slow_traffic_small.mp4')
parser.add_argument('image', type=str, help='path to image file')
args = parser.parse_args()
cap = cv.VideoCapture(args.image)
# 视频的第一帧
ret,frame = cap.read()
# 设置窗口的初始位置
x, y, w, h = 300, 200, 100, 50 # simply hardcoded the values
track_window = (x, y, w, h)
# 设置初始ROI来追踪
roi = frame[y:y+h, x:x+w]
hsv_roi = cv.cvtColor(roi, cv.COLOR_BGR2HSV)
mask = cv.inRange(hsv_roi, np.array((0., 60.,32.)), np.array((180.,255.,255.)))
roi_hist = cv.calcHist([hsv_roi],[0],mask,[180],[0,180])
cv.normalize(roi_hist,roi_hist,0,255,cv.NORM_MINMAX)
# 设置终止条件,可以是10次迭代,也可以至少移动1 pt
term_crit = ( cv.TERM_CRITERIA_EPS | cv.TERM_CRITERIA_COUNT, 10, 1 )
while(1):
ret, frame = cap.read()
if ret == True:
hsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV)
dst = cv.calcBackProject([hsv],[0],roi_hist,[0,180],1)
# 应用meanshift来获取新位置
ret, track_window = cv.meanShift(dst, track_window, term_crit)
# 在图像上绘制
x,y,w,h = track_window
img2 = cv.rectangle(frame, (x,y), (x+w,y+h), 255,2)
cv.imshow('img2',img2)
k = cv.waitKey(30) & 0xff
if k == 27:
break
else:
break
我使用的视频中的三帧如下:
您是否密切关注了最后结果?这儿存在一个问题。无论汽车离相机很近或非常近,我们的窗口始终具有相同的大小。这是不好的。我们需要根据目标的大小和旋转来调整窗口大小。该解决方案再次来自“ OpenCV Labs”,它被称为Gary布拉德斯基(Gary Bradsky)在其1998年的论文“用于感知用户界面中的计算机视觉面部跟踪”中发表的CAMshift(连续自适应均值偏移)[26]。它首先应用Meanshift。一旦Meanshift收敛,它将更新窗口的大小为s = 2 times sqrt{frac{M_{00}}{256}}。它还可以计算出最合适的椭圆的方向。再次将均值偏移应用于新的缩放搜索窗口和先前的窗口位置。该过程一直持续到达到要求的精度为止。
它与meanshift相似,但是返回一个旋转的矩形(即我们的结果)和box参数(用于在下一次迭代中作为搜索窗口传递)。请参见下面的代码:
import numpy as np
import cv2 as cv
import argparse
parser = argparse.ArgumentParser(description='This sample demonstrates the camshift algorithm.
The example file can be downloaded from:
https://www.bogotobogo.com/python/OpenCV_Python/images/mean_shift_tracking/slow_traffic_small.mp4')
parser.add_argument('image', type=str, help='path to image file')
args = parser.parse_args()
cap = cv.VideoCapture(args.image)
# 获取视频第一帧
ret,frame = cap.read()
# 设置初始窗口
x, y, w, h = 300, 200, 100, 50 # simply hardcoded the values
track_window = (x, y, w, h)
# 设置追踪的ROI窗口
roi = frame[y:y+h, x:x+w]
hsv_roi = cv.cvtColor(roi, cv.COLOR_BGR2HSV)
mask = cv.inRange(hsv_roi, np.array((0., 60.,32.)), np.array((180.,255.,255.)))
roi_hist = cv.calcHist([hsv_roi],[0],mask,[180],[0,180])
cv.normalize(roi_hist,roi_hist,0,255,cv.NORM_MINMAX)
# 设置终止条件,可以是10次迭代,有可以至少移动1个像素
term_crit = ( cv.TERM_CRITERIA_EPS | cv.TERM_CRITERIA_COUNT, 10, 1 )
while(1):
ret, frame = cap.read()
if ret == True:
hsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV)
dst = cv.calcBackProject([hsv],[0],roi_hist,[0,180],1)
# 应用camshift 到新位置
ret, track_window = cv.CamShift(dst, track_window, term_crit)
# 在图像上画出来
pts = cv.boxPoints(ret)
pts = np.int0(pts)
img2 = cv.polylines(frame,[pts],True, 255,2)
cv.imshow('img2',img2)
k = cv.waitKey(30) & 0xff
if k == 27:
break
else:
break
三帧的结果如下
在本章中,
光流是由物体或照相机的运动引起的两个连续帧之间图像物体的视运动的模式。它是2D向量场,其中每个向量都是位移向量,表示点从第一帧到第二帧的运动。考虑下面的图片(图片提供:Wikipedia关于Optical Flow的文章)。
它显示了一个球连续5帧运动。箭头显示其位移向量。光流在以下领域具有许多应用:
光流基于以下几个假设进行工作:
考虑第一帧中的像素$I(x,y,t)$(在此处添加新维度:时间。之前我们只处理图像,因此不需要时间)。它在$dt$时间之后拍摄的下一帧中按距离$(dx,dy)$移动。因此,由于这些像素相同且强度不变,因此可以说
然后采用泰勒级数的右侧逼近,去掉常用项并除以$dt$得到下面的式子
其中
上述方程式称为光流方程式。在其中,我们可以找到$fx$和$fy$,它们是图像渐变。同样,$f_t$是随时间变化的梯度。但是$(u,v)$是未知的。我们不能用两个未知变量来求解这个方程。因此,提供了几种解决此问题的方法,其中一种是Lucas-Kanade。
之前我们已经看到一个假设,即所有相邻像素将具有相似的运动。Lucas-Kanade方法在该点周围需要3x3色块。因此,所有9个点都具有相同的运动。我们可以找到这9点的$(fx,fy,ft)$。所以现在我们的问题变成了求解带有两个未知变量的9个方程组的问题。用最小二乘拟合法可获得更好的解决方案。下面是最终的解决方案,它是两个方程式-两个未知变量问题,求解以获得解决答案。
(用哈里斯拐角检测器检查逆矩阵的相似性。这表示拐角是更好的跟踪点。)因此,从用户的角度来看,这个想法很简单,我们给一些跟踪点,我们接收到这些光流矢量点。但是同样存在一些问题。到现在为止,我们只处理小动作,所以当大动作时它就失败了。为了解决这个问题,我们使用金字塔。当我们上金字塔时,较小的动作将被删除,较大的动作将变为较小的动作。因此,通过在此处应用Lucas-Kanade,我们可以获得与尺度一致的光流。
OpenCV在单个函数cv.calcOpticalFlowPyrLK()中提供所有这些功能。在这里,我们创建一个简单的应用程序来跟踪视频中的某些点。为了确定点,我们使用cv.goodFeaturesToTrack()。我们采用第一帧,检测其中的一些Shi-Tomasi角点,然后使用Lucas-Kanade光流迭代地跟踪这些点。对于函数cv.calcOpticalFlowPyrLK(),我们传递前一帧,前一点和下一帧。它返回下一个点以及一些状态码,如果找到下一个点,状态码的值为1,否则为零。我们将这些下一个点迭代地传递为下一步中的上一个点。请参见下面的代码:
import numpy as np
import cv2 as cv
import argparse
parser = argparse.ArgumentParser(description='This sample demonstrates Lucas-Kanade Optical Flow calculation.
The example file can be downloaded from:
https://www.bogotobogo.com/python/OpenCV_Python/images/mean_shift_tracking/slow_traffic_small.mp4')
parser.add_argument('image', type=str, help='path to image file')
args = parser.parse_args()
cap = cv.VideoCapture(args.image)
# 用于ShiTomasi拐点检测的参数
feature_params = dict( maxCorners = 100,
qualityLevel = 0.3,
minDistance = 7,
blockSize = 7 )
# lucas kanade光流参数
lk_params = dict( winSize = (15,15),
maxLevel = 2,
criteria = (cv.TERM_CRITERIA_EPS | cv.TERM_CRITERIA_COUNT, 10, 0.03))
# 创建一些随机的颜色
color = np.random.randint(0,255,(100,3))
# 拍摄第一帧并在其中找到拐角
ret, old_frame = cap.read()
old_gray = cv.cvtColor(old_frame, cv.COLOR_BGR2GRAY)
p0 = cv.goodFeaturesToTrack(old_gray, mask = None, **feature_params)
# 创建用于作图的掩码图像
mask = np.zeros_like(old_frame)
while(1):
ret,frame = cap.read()
frame_gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
# 计算光流
p1, st, err = cv.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)
# 选择良好点
good_new = p1[st==1]
good_old = p0[st==1]
# 绘制跟踪
for i,(new,old) in enumerate(zip(good_new, good_old)):
a,b = new.ravel()
c,d = old.ravel()
mask = cv.line(mask, (a,b),(c,d), color[i].tolist(), 2)
frame = cv.circle(frame,(a,b),5,color[i].tolist(),-1)
img = cv.add(frame,mask)
cv.imshow('frame',img)
k = cv.waitKey(30) & 0xff
if k == 27:
break
# 现在更新之前的帧和点
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1,1,2)
(此代码不会检查下一个关键点的正确性。因此,即使任何特征点在图像中消失了,光流也有可能找到下一个看起来可能与它接近的下一个点。因此,对于稳健的跟踪,实际上 应该以特定的时间间隔检测点。OpenCV样本附带了这样一个样本,该样本每5帧发现一次特征点,并且还对光流点进行了后向检查,以仅选择良好的流点。请参阅代码
samples/python/lk_track.py)。
查看我们得到的结果:
Lucas-Kanade方法计算稀疏特征集的光流(在我们的示例中为使用Shi-Tomasi算法检测到的角)。OpenCV提供了另一种算法来查找密集的光流。它计算帧中所有点的光通量。它基于Gunner Farneback的算法,在2003年Gunner Farneback的“基于多项式展开的两帧运动估计”中对此进行了解释。
下面的示例显示了如何使用上述算法找到密集的光流。我们得到一个带有光流矢量$(u,v)$的2通道阵列。我们找到了它们的大小和方向。我们对结果进行颜色编码,以实现更好的可视化。方向对应于图像的色相值。幅度对应于值平面。请参见下面的代码:
import numpy as np
import cv2 as cv
cap = cv.VideoCapture(cv.samples.findFile("vtest.avi"))
ret, frame1 = cap.read()
prvs = cv.cvtColor(frame1,cv.COLOR_BGR2GRAY)
hsv = np.zeros_like(frame1)
hsv[...,1] = 255
while(1):
ret, frame2 = cap.read()
next = cv.cvtColor(frame2,cv.COLOR_BGR2GRAY)
flow = cv.calcOpticalFlowFarneback(prvs,next, None, 0.5, 3, 15, 3, 5, 1.2, 0)
mag, ang = cv.cartToPolar(flow[...,0], flow[...,1])
hsv[...,0] = ang*180/np.pi/2
hsv[...,2] = cv.normalize(mag,None,0,255,cv.NORM_MINMAX)
bgr = cv.cvtColor(hsv,cv.COLOR_HSV2BGR)
cv.imshow('frame2',bgr)
k = cv.waitKey(30) & 0xff
if k == 27:
break
elif k == ord('s'):
cv.imwrite('opticalfb.png',frame2)
cv.imwrite('opticalhsv.png',bgr)
prvs = next
查看以下结果:
在本节中,我们将学习
一些针孔相机会给图像带来明显的失真。两种主要的变形是径向变形和切向变形。径向变形会导致直线出现弯曲。
距图像中心越远,径向畸变越大。例如,下面显示一个图像,其中棋盘的两个边缘用红线标记。但是,您会看到棋盘的边框不是直线,并且与红线不匹配。所有预期的直线都凸出。有关更多详细信息,请访问“失真(光学)”。
径向变形可以表示成如下:
同样,由于摄像镜头未完全平行于成像平面对齐,因此会发生切向畸变。因此,图像中的某些区域看起来可能比预期的要近。切向畸变的量可以表示为:
简而言之,我们需要找到五个参数,称为失真系数,公式如下:
除此之外,我们还需要其他一些信息,例如相机的内在和外在参数。内部参数特定于摄像机。它们包括诸如焦距(f_x,f_y)和光学中心(c_x,c_y)之类的信息。焦距和光学中心可用于创建相机矩阵,该相机矩阵可用于消除由于特定相机镜头而引起的畸变。相机矩阵对于特定相机而言是唯一的,因此一旦计算出,就可以在同一相机拍摄的其他图像上重复使用。它表示为3x3矩阵:
外在参数对应于旋转和平移矢量,其将3D点的坐标平移为坐标系。
对于立体声应用,首先需要纠正这些失真。要找到这些参数,我们必须提供一些定义良好的图案的示例图像(例如国际象棋棋盘)。我们找到一些已经知道其相对位置的特定点(例如棋盘上的四角)。我们知道现实世界空间中这些点的坐标,也知道图像中的坐标,因此我们可以求解失真系数。为了获得更好的结果,我们至少需要10个测试模式。
如上所述,相机校准至少需要10个测试图案。OpenCV附带了一些国际象棋棋盘的图像(请参见samples / data / left01.jpg – left14.jpg),因此我们将利用这些图像。考虑棋盘的图像。相机校准所需的重要输入数据是3D现实世界点集以及图像中这些点的相应2D坐标。可以从图像中轻松找到2D图像点。(这些图像点是国际象棋棋盘中两个黑色正方形相互接触的位置)
真实世界中的3D点如何处理?这些图像是从静态相机拍摄的,而国际象棋棋盘放置在不同的位置和方向。因此,我们需要知道(X,Y,Z)值。但是为简单起见,我们可以说棋盘在XY平面上保持静止(因此Z始终为0),并且照相机也相应地移动了。这种考虑有助于我们仅找到X,Y值。现在对于X,Y值,我们可以简单地将点传递为(0,0),(1,0),(2,0),…,这表示点的位置。在这种情况下,我们得到的结果将是棋盘正方形的大小比例。但是,如果我们知道正方形大小(例如30毫米),则可以将值传递为(0,0),(30,0),(60,0),…。因此,我们得到的结果以毫米为单位。(在这种情况下,我们不知道正方形的大小,因为我们没有拍摄那些图像,因此我们以正方形的大小进行传递)。
3D点称为对象点,而2D图像点称为图像点。
因此,要在国际象棋棋盘中查找图案,我们可以使用函数cv.findChessboardCorners()。我们还需要传递所需的图案,例如8x8网格,5x5网格等。在此示例中,我们使用7x6网格。(通常,棋盘有8x8的正方形和7x7的内部角)。它返回角点和retval,如果获得图案,则为True。这些角将按顺序放置(从左到右,从上到下)
此功能可能无法在所有图像中找到所需的图案。因此,一个不错的选择是编写代码,使它启动相机并检查每帧所需的图案。获得图案后,找到角并将其存储在列表中。另外,在阅读下一帧之前请提供一些时间间隔,以便我们可以在不同方向上调整棋盘。继续此过程,直到获得所需数量的良好图案为止。即使在此处提供的示例中,我们也不确定给出的14张图像中有多少张是好的。
因此,我们必须阅读所有图像并仅拍摄好图像。除了棋盘,我们还可以使用圆形网格。在这种情况下,我们必须使用函数cv.findCirclesGrid()来找到模式。较少的图像足以使用圆形网格执行相机校准。
一旦找到拐角,就可以使用cv.cornerSubPix()来提高其精度。我们还可以使用cv.drawChessboardCorners()绘制图案。所有这些步骤都包含在以下代码中:
import numpy as np
import cv2 as cv
import glob
# 终止条件
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 30, 0.001)
# 准备对象点, 如 (0,0,0), (1,0,0), (2,0,0) ....,(6,5,0)
objp = np.zeros((6*7,3), np.float32)
objp[:,:2] = np.mgrid[0:7,0:6].T.reshape(-1,2)
# 用于存储所有图像的对象点和图像点的数组。
objpoints = [] # 真实世界中的3d点
imgpoints = [] # 图像中的2d点
images = glob.glob('*.jpg')
for fname in images:
img = cv.imread(fname)
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# 找到棋盘角落
ret, corners = cv.findChessboardCorners(gray, (7,6), None)
# 如果找到,添加对象点,图像点(细化之后)
if ret == True:
objpoints.append(objp)
corners2 = cv.cornerSubPix(gray,corners, (11,11), (-1,-1), criteria)
imgpoints.append(corners)
# 绘制并显示拐角
cv.drawChessboardCorners(img, (7,6), corners2, ret)
cv.imshow('img', img)
cv.waitKey(500)
cv.destroyAllwindows()
一张上面画有图案的图像如下所示:
现在我们有了目标点和图像点,现在可以进行校准了。我们可以使用函数cv.calibrateCamera()返回相机矩阵,失真系数,旋转和平移矢量等。
ret, mtx, dist, rvecs, tvecs = cv.calibrateCamera(objpoints, imgpoints, gray.shape[::-1], None, None)
现在,我们可以拍摄图像并对其进行扭曲。OpenCV提供了两种方法来执行此操作。但是,首先,我们可以使用
cv.getOptimalNewCameraMatrix()基于自由缩放参数来优化相机矩阵。如果缩放参数alpha = 0,则返回具有最少不需要像素的未失真图像。因此,它甚至可能会删除图像角落的一些像素。如果alpha = 1,则所有像素都保留有一些额外的黑色图像。此函数还返回可用于裁剪结果的图像ROI。
因此,我们拍摄一张新图像(在本例中为left12.jpg。这是本章的第一张图像)
img = cv.imread('left12.jpg')
h, w = img.shape[:2]
newcameramtx, roi = cv.getOptimalNewCameraMatrix(mtx, dist, (w,h), 1, (w,h))
这是最简单的方法。只需调用该函数并使用上面获得的ROI裁剪结果即可。
# undistort
dst = cv.undistort(img, mtx, dist, None, newcameramtx)
# 剪裁图像
x, y, w, h = roi
dst = dst[y:y+h, x:x+w]
cv.imwrite('calibresult.png', dst)
该方式有点困难。首先,找到从扭曲图像到未扭曲图像的映射函数。然后使用重映射功能。
# undistort
mapx, mapy = cv.initUndistortRectifyMap(mtx, dist, None, newcameramtx, (w,h), 5)
dst = cv.remap(img, mapx, mapy, cv.INTER_LINEAR)
# 裁剪图像
x, y, w, h = roi
dst = dst[y:y+h, x:x+w]
cv.imwrite('calibresult.png', dst)
尽管如此,两种方法都给出相同的结果。看到下面的结果:
您可以看到所有边缘都是笔直的。现在,您可以使用NumPy中的写入功能(np.savez,np.savetxt等)存储相机矩阵和失真系数,以备将来使用。
重投影误差可以很好地估计找到的参数的精确程度。重投影误差越接近零,我们发现的参数越准确。给定固有,失真,旋转和平移矩阵,我们必须首先使用cv.projectPoints()将对象点转换为图像点。然后,我们可以计算出通过变换得到的绝对值和拐角发现算法之间的绝对值范数。为了找到平均误差,我们计算为所有校准图像计算的误差的算术平均值。
mean_error = 0
for i in xrange(len(objpoints)):
imgpoints2, _ = cv.projectPoints(objpoints[i], rvecs[i], tvecs[i], mtx, dist)
error = cv.norm(imgpoints[i], imgpoints2, cv.NORM_L2)/len(imgpoints2)
mean_error += error
print( "total error: {}".format(mean_error/len(objpoints)) )
在本章中
这将是一小部分。在上一次相机校准的会话中,你发现了相机矩阵,失真系数等。给定图案图像,我们可以利用以上信息来计算其姿势或物体在空间中的位置,例如其旋转方式, 对于平面物体,我们可以假设Z = 0,这样,问题就变成了如何将相机放置在空间中以查看图案图像。 因此,如果我们知道对象在空间中的位置,则可以在其中绘制一些2D图以模拟3D效果。 让我们看看如何做。
我们的问题是,我们想在棋盘的第一个角上绘制3D坐标轴(X,Y,Z)。 X轴为蓝色,Y轴为绿色,Z轴为红色。 因此,实际上Z轴应该感觉像它垂直于我们的棋盘平面。
首先,让我们从先前的校准结果中加载相机矩阵和失真系数。
import numpy as np
import cv2 as cv
import glob
# 加载先前保存的数据
with np.load('B.npz') as X:
mtx, dist, _, _ = [X[i] for i in ('mtx','dist','rvecs','tvecs')]
现在让我们创建一个函数,绘制,该函数将棋盘上的角(使用cv.findChessboardCorners()获得)和轴点绘制为3D轴。
def draw(img, corners, imgpts):
corner = tuple(corners[0].ravel())
img = cv.line(img, corner, tuple(imgpts[0].ravel()), (255,0,0), 5)
img = cv.line(img, corner, tuple(imgpts[1].ravel()), (0,255,0), 5)
img = cv.line(img, corner, tuple(imgpts[2].ravel()), (0,0,255), 5)
return img
然后,与前面的情况一样,我们创建终止条件,对象点(棋盘上角的3D点)和轴点。 轴点是3D空间中用于绘制轴的点。 我们绘制长度为3的轴(由于我们根据该棋盘尺寸进行了校准,因此单位将以国际象棋正方形的尺寸为单位)。因此我们的X轴从(0,0,0)绘制为(3,0,0),因此对于Y轴。 对于Z轴,从(0,0,0)绘制为(0,0,-3)。 负号表示它被拉向相机。
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 30, 0.001)
objp = np.zeros((6*7,3), np.float32)
objp[:,:2] = np.mgrid[0:7,0:6].T.reshape(-1,2)
axis = np.float32([[3,0,0], [0,3,0], [0,0,-3]]).reshape(-1,3)
现在,像往常一样,我们加载每个图像。搜索7x6网格。如果找到,我们将使用子角像素对其进行优化。然后使用函数cv.solvePnPRansac()计算旋转和平移。一旦有了这些变换矩阵,就可以使用它们将轴点投影到图像平面上。简而言之,我们在图像平面上找到与3D空间中(3,0,0),(0,3,0),(0,0,3)中的每一个相对应的点。一旦获得它们,就可以使用draw()函数从第一个角到这些点中的每个点绘制线条。完毕!!!
for fname in glob.glob('left*.jpg'):
img = cv.imread(fname)
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
ret, corners = cv.findChessboardCorners(gray, (7,6),None)
if ret == True:
corners2 = cv.cornerSubPix(gray,corners,(11,11),(-1,-1),criteria)
# 找到旋转和平移矢量。
ret,rvecs, tvecs = cv.solvePnP(objp, corners2, mtx, dist)
# 将3D点投影到图像平面
imgpts, jac = cv.projectPoints(axis, rvecs, tvecs, mtx, dist)
img = draw(img,corners2,imgpts)
cv.imshow('img',img)
k = cv.waitKey(0) & 0xFF
if k == ord('s'):
cv.imwrite(fname[:6]+'.png', img)
cv.destroyAllWindows()
请参阅下面的一些结果。请注意,每个轴长3个long单位。
如果要绘制立方体,请如下修改draw()函数和轴点。 修改后的draw()函数:
def draw(img, corners, imgpts):
imgpts = np.int32(imgpts).reshape(-1,2)
# 用绿色绘制底层
img = cv.drawContours(img, [imgpts[:4]],-1,(0,255,0),-3)
# 用蓝色绘制高
for i,j in zip(range(4),range(4,8)):
img = cv.line(img, tuple(imgpts[i]), tuple(imgpts[j]),(255),3)
# 用红色绘制顶层
img = cv.drawContours(img, [imgpts[4:]],-1,(0,0,255),3)
return img
修改的轴点。它们是3D空间中多维数据集的8个角:
axis = np.float32([[0,0,0], [0,3,0], [3,3,0], [3,0,0], [0,0,-3],[0,3,-3],[3,3,-3],[3,0,-3] ])
查看以下结果:
如果您对图形,增强现实等感兴趣,则可以使用OpenGL渲染更复杂的图形。
在本节中
当我们使用针孔相机拍摄图像时,我们失去了重要信息,即图像深度。 或者图像中的每个点距相机多远,因为它是3D到2D转换。 因此,是否能够使用这些摄像机找到深度信息是一个重要的问题。 答案是使用不止一台摄像机。 在使用两台摄像机(两只眼睛)的情况下,我们的眼睛工作方式相似,这称为立体视觉。 因此,让我们看看OpenCV在此字段中提供了什么。
(通过Gary Bradsky学习OpenCV在该领域有很多信息。)
在深入图像之前,让我们首先了解多视图几何中的一些基本概念。在本节中,我们将讨论对极几何。请参见下图,该图显示了使用两台摄像机拍摄同一场景的图像的基本设置。
如果仅使用左摄像机,则无法找到与图像中的点相对应的3D点,因为线上的每个点都投影到图像平面上的同一点。但也要考虑正确的形象。现在,直线$OX$上的不同点投射到右侧平面上的不同点($x'$)。因此,使用这两个图像,我们可以对正确的3D点进行三角剖分。这就是整个想法。
不同点的投影在右平面$OX$上形成一条线(line$l'$)。我们称其为对应于该点的Epiline。这意味着,要在正确的图像上找到该点,请沿着该轮廓线搜索。它应该在这条线上的某处(以这种方式考虑,可以在其他图像中找到匹配点,而无需搜索整个图像,只需沿着Epiline搜索即可。因此,它可以提供更好的性能和准确性)。这称为对极约束。类似地,所有点在另一幅图像中将具有其对应的Epiline。该平面称为对极面。
$O$和$O'$是相机中心。从上面给出的设置中,您可以看到在点处的左侧图像上可以看到右侧摄像机$O'$的投影。它称为极点。极点是穿过相机中心和图像平面的线的交点。左摄像机的极点也同理。在某些情况下,您将无法在图像中找到极点,它们可能位于图像外部(这意味着一个摄像机看不到另一个摄像机)。
所有的极线都通过其极点。因此,要找到中心线的位置,我们可以找到许多中心线并找到它们的交点。
因此,在节中,我们将重点放在寻找对极线和极线。但是要找到它们,我们需要另外两种成分,即基础矩阵(F)和基本矩阵(E),基础矩阵包含有关平移和旋转的信息,这些信息在全局坐标中描述了第二个摄像头相对于第一个摄像头的位置。参见下图(图像由Gary Bradsky提供:Learning OpenCV):
但是我们会更喜欢在像素坐标中进行测量,对吧? 基本矩阵除包含有关两个摄像头的内在信息之外,还包含与基本矩阵相同的信息,因此我们可以将两个摄像头的像素坐标关联起来。(如果我们使用的是校正后的图像,并用焦距除以标准化该点,$F=E$)。简而言之,基本矩阵F将一个图像中的点映射到另一图像中的线(上)。这是从两个图像的匹配点计算得出的。 至少需要8个这样的点才能找到基本矩阵(使用8点算法时)。 选择更多点并使用RANSAC将获得更可靠的结果。
因此,首先我们需要在两个图像之间找到尽可能多的匹配项,以找到基本矩阵。为此,我们将SIFT描述符与基于FLANN的匹配器和比率测试结合使用。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img1 = cv.imread('myleft.jpg',0) #索引图像 # left image
img2 = cv.imread('myright.jpg',0) #训练图像 # right image
sift = cv.SIFT()
# 使用SIFT查找关键点和描述符
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
# FLANN 参数
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks=50)
flann = cv.FlannBasedMatcher(index_params,search_params)
matches = flann.knnMatch(des1,des2,k=2)
good = []
pts1 = []
pts2 = []
# 根据Lowe的论文进行比率测试
for i,(m,n) in enumerate(matches):
if m.distance < 0.8*n.distance:
good.append(m)
pts2.append(kp2[m.trainIdx].pt)
pts1.append(kp1[m.queryIdx].pt)
现在,我们获得了两张图片的最佳匹配列表。 让我们找到基本面矩阵。
pts1 = np.int32(pts1)
pts2 = np.int32(pts2)
F, mask = cv.findFundamentalMat(pts1,pts2,cv.FM_LMEDS)
# 我们只选择内点
pts1 = pts1[mask.ravel()==1]
pts2 = pts2[mask.ravel()==1]
接下来,我们找到Epilines。在第二张图像上绘制与第一张图像中的点相对应的Epilines。因此,在这里提到正确的图像很重要。我们得到了一行线。因此,我们定义了一个新功能来在图像上绘制这些线条。
def drawlines(img1,img2,lines,pts1,pts2):
''' img1 - 我们在img2相应位置绘制极点生成的图像
lines - 对应的极点 '''
r,c = img1.shape
img1 = cv.cvtColor(img1,cv.COLOR_GRAY2BGR)
img2 = cv.cvtColor(img2,cv.COLOR_GRAY2BGR)
for r,pt1,pt2 in zip(lines,pts1,pts2):
color = tuple(np.random.randint(0,255,3).tolist())
x0,y0 = map(int, [0, -r[2]/r[1] ])
x1,y1 = map(int, [c, -(r[2]+r[0]*c)/r[1] ])
img1 = cv.line(img1, (x0,y0), (x1,y1), color,1)
img1 = cv.circle(img1,tuple(pt1),5,color,-1)
img2 = cv.circle(img2,tuple(pt2),5,color,-1)
return img1,img2
现在,我们在两个图像中都找到了Epiline并将其绘制。
# 在右图(第二张图)中找到与点相对应的极点,然后在左图绘制极线
lines1 = cv.computeCorrespondEpilines(pts2.reshape(-1,1,2), 2,F)
lines1 = lines1.reshape(-1,3)
img5,img6 = drawlines(img1,img2,lines1,pts1,pts2)
# 在左图(第一张图)中找到与点相对应的Epilines,然后在正确的图像上绘制极线
lines2 = cv.computeCorrespondEpilines(pts1.reshape(-1,1,2), 1,F)
lines2 = lines2.reshape(-1,3)
img3,img4 = drawlines(img2,img1,lines2,pts2,pts1)
plt.subplot(121),plt.imshow(img5)
plt.subplot(122),plt.imshow(img3)
plt.show()
以下是我们得到的结果:
您可以在左侧图像中看到所有极点都收敛在右侧图像的外部。那个汇合点就是极点。 为了获得更好的结果,应使用具有良好分辨率和许多非平面点的图像。
在本节中,
在上一节中,我们看到了对极约束和其他相关术语等基本概念。我们还看到,如果我们有两个场景相同的图像,则可以通过直观的方式从中获取深度信息。下面是一张图片和一些简单的数学公式证明了这种想法。
上图包含等效三角形。编写它们的等式将产生以下结果:
$$ disparity = x - x' = frac{Bf}{Z} $$
$x$和$x'$是图像平面中与场景点3D相对应的点与其相机中心之间的距离。$B$是两个摄像机之间的距离(我们知道),$f$是摄像机的焦距(已经知道)。简而言之,上述方程式表示场景中某个点的深度与相应图像点及其相机中心的距离差成反比。因此,利用此信息,我们可以得出图像中所有像素的深度。
因此,它在两个图像之间找到了对应的匹配项。我们已经看到了Epiline约束如何使此操作更快,更准确。一旦找到匹配项,就会发现差异。让我们看看如何使用OpenCV做到这一点。
下面的代码片段显示了创建视差图的简单过程。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
imgL = cv.imread('tsukuba_l.png',0)
imgR = cv.imread('tsukuba_r.png',0)
stereo = cv.StereoBM_create(numDisparities=16, blockSize=15)
disparity = stereo.compute(imgL,imgR)
plt.imshow(disparity,'gray')
plt.show()
下面的图像包含原始图像(左)及其视差图(右)。如你所见,结果受到高度噪声的污染。通过调整numDisparities和blockSize的值,可以获得更好的结果。
当你熟悉StereoBM时,会有一些参数,可能需要微调参数以获得更好,更平滑的结果。参数:
在本章中,我们将了解k近邻(kNN)算法的原理。
kNN是可用于监督学习的最简单的分类算法之一。这个想法是在特征空间中搜索测试数据的最近邻。我们将用下面的图片来研究它。
在图像中,有两个族,蓝色正方形和红色三角形。我们称每一种为类。他们的房屋显示在他们的城镇地图中,我们称之为特征空间。 (你可以将要素空间视为投影所有数据的空间。例如,考虑一个2D坐标空间。每个数据都有两个要素,x和y坐标。你可以在2D坐标空间中表示此数据,对吧?现在假设如果有三个要素,则需要3D空间;现在考虑N个要素,需要N维空间,对吗?这个N维空间就是其要素空间。在我们的图像中,你可以将其视为2D情况。有两个功能)。
现在有一个新成员进入城镇并创建了一个新房屋,显示为绿色圆圈。他应该被添加到这些蓝色/红色家族之一中。我们称该过程为分类。我们所做的?由于我们正在处理kNN,因此让我们应用此算法。
一种方法是检查谁是他的最近邻。从图像中可以明显看出它是红色三角形家族。因此,他也被添加到了红色三角形中。此方法简称为“最近邻”,因为分类仅取决于最近邻。
但这是有问题的。红三角可能是最近的。但是,如果附近有很多蓝色方块怎么办?然后,蓝色方块在该地区的权重比红色三角更大。因此,仅检查最接近的一个是不够的。相反,我们检查一些k近邻的族。那么,无论谁占多数,新样本都属于那个族。在我们的图像中,让我们取k=3,即3个最近族。他有两个红色和一个蓝色(有两个等距的蓝色,但是由于k = 3,我们只取其中一个),所以他又应该加入红色家族。但是,如果我们取k=7怎么办?然后,他有5个蓝色族和2个红色族。太好了!!现在,他应该加入蓝色族。因此,所有这些都随k的值而变化。更有趣的是,如果k=4怎么办?他有2个红色邻居和2个蓝色邻居。这是一个平滑!因此最好将k作为奇数。由于分类取决于k个最近的邻居,因此该方法称为k近邻。
同样,在kNN中,我们确实在考虑k个邻居,但我们对所有人都给予同等的重视,对吧?这公平吗?例如,以k=4的情况为例。我们说这是平局。但是请注意,这两个红色族比其他两个蓝色族离他更近。因此,他更应该被添加到红色。那么我们如何用数学解释呢?我们根据每个家庭到新来者的距离来给他们一些权重。对于那些靠近他的人,权重增加,而那些远离他的人,权重减轻。然后,我们分别添加每个族的总权重。谁得到的总权重最高,新样本归为那一族。这称为modified kNN。
那么你在这里看到的一些重要内容是什么?
现在让我们在OpenCV中看到它。
就像上面一样,我们将在这里做一个简单的例子,有两个族(类)。然后在下一章中,我们将做一个更好的例子。
因此,在这里,我们将红色系列标记为Class-0(因此用0表示),将蓝色系列标记为Class-1(用1表示)。我们创建25个族或25个训练数据,并将它们标记为0类或1类。我们借助Numpy中的Random Number Generator来完成所有这些工作。
然后我们在Matplotlib的帮助下对其进行绘制。红色系列显示为红色三角形,蓝色系列显示为蓝色正方形。
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
# 包含(x,y)值的25个已知/训练数据的特征集
trainData = np.random.randint(0,100,(25,2)).astype(np.float32)
# 用数字0和1分别标记红色或蓝色
responses = np.random.randint(0,2,(25,1)).astype(np.float32)
# 取红色族并绘图
red = trainData[responses.ravel()==0]
plt.scatter(red[:,0],red[:,1],80,'r','^')
# 取蓝色族并绘图
blue = trainData[responses.ravel()==1]
plt.scatter(blue[:,0],blue[:,1],80,'b','s')
plt.show()
你会得到与我们的第一张图片相似的东西。由于你使用的是随机数生成器,因此每次运行代码都将获得不同的数据。
接下来启动kNN算法,并传递trainData和响应以训练kNN(它会构建搜索树)。
然后,我们将在OpenCV中的kNN的帮助下将一个新样本带入一个族并将其分类。在进入kNN之前,我们需要了解测试数据(新样本数据)上的知识。我们的数据应为浮点数组,其大小为$number of testdatatimes number of features$。然后我们找到新加入的最近邻。我们可以指定我们想要多少个邻居。它返回:
因此,让我们看看它是如何工作的。新样本被标记为绿色。
newcomer = np.random.randint(0,100,(1,2)).astype(np.float32)
plt.scatter(newcomer[:,0],newcomer[:,1],80,'g','o')
knn = cv.ml.KNearest_create()
knn.train(trainData, cv.ml.ROW_SAMPLE, responses)
ret, results, neighbours ,dist = knn.findNearest(newcomer, 3)
print( "result: {}n".format(results) )
print( "neighbours: {}n".format(neighbours) )
print( "distance: {}n".format(dist) )
plt.show()
我得到了如下的结果:
result: [[ 1.]]
neighbours: [[ 1. 1. 1.]]
distance: [[ 53. 58. 61.]]
它说我们的新样本有3个近邻,全部来自Blue家族。因此,他被标记为蓝色家庭。从下面的图可以明显看出:
如果你有大量数据,则可以将其作为数组传递。还获得了相应的结果作为数组。
# 10个新加入样本
newcomers = np.random.randint(0,100,(10,2)).astype(np.float32)
ret, results,neighbours,dist = knn.findNearest(newcomer, 3)
# 结果包含10个标签
在本章中
我们的目标是构建一个可以读取手写数字的应用程序。为此,我们需要一些train_data和test_data。OpenCV带有一个图片digits.png(在文件夹opencv/samples/data/中),其中包含5000个手写数字(每个数字500个)。每个数字都是20x20的图像。因此,我们的第一步是将图像分割成5000个不同的数字。对于每个数字,我们将其展平为400像素的一行。那就是我们的训练集,即所有像素的强度值。这是我们可以创建的最简单的功能集。我们将每个数字的前250个样本用作train_data,然后将250个样本用作test_data。因此,让我们先准备它们。
import numpy as np
import cv2 as cv
img = cv.imread('digits.png')
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
# 现在我们将图像分割为5000个单元格,每个单元格为20x20
cells = [np.hsplit(row,100) for row in np.vsplit(gray,50)]
# 使其成为一个Numpy数组。它的大小将是(50,100,20,20)
x = np.array(cells)
# 现在我们准备train_data和test_data。
train = x[:,:50].reshape(-1,400).astype(np.float32) # Size = (2500,400)
test = x[:,50:100].reshape(-1,400).astype(np.float32) # Size = (2500,400)
# 为训练和测试数据创建标签
k = np.arange(10)
train_labels = np.repeat(k,250)[:,np.newaxis]
test_labels = train_labels.copy()
# 初始化kNN,训练数据,然后使用k = 1的测试数据对其进行测试
knn = cv.ml.KNearest_create()
knn.train(train, cv.ml.ROW_SAMPLE, train_labels)
ret,result,neighbours,dist = knn.findNearest(test,k=5)
# 现在,我们检查分类的准确性
#为此,将结果与test_labels进行比较,并检查哪个错误
matches = result==test_labels
correct = np.count_nonzero(matches)
accuracy = correct*100.0/result.size
print( accuracy )
因此,我们的基本OCR应用程序已准备就绪。这个特定的例子给我的准确性是91%。一种提高准确性的选择是添加更多数据进行训练,尤其是错误的数据。因此,与其每次启动应用程序时都找不到该培训数据,不如将其保存,以便下次我直接从文件中读取此数据并开始分类。您可以借助一些Numpy函数(例如np.savetxt,np.savez,np.load等)来完成此操作。请查看其文档以获取更多详细信息。
# 保存数据
np.savez('knn_data.npz',train=train, train_labels=train_labels)
# 现在加载数据
with np.load('knn_data.npz') as data:
print( data.files )
train = data['train']
train_labels = data['train_labels']
在我的系统中,它需要大约4.4 MB的内存。由于我们使用强度值(uint8数据)作为特征,因此最好先将数据转换为np.uint8,然后再将其保存。在这种情况下,仅占用1.1 MB。然后在加载时,您可以转换回float32。
接下来,我们将对英语字母执行相同的操作,但是数据和功能集会稍有变化。在这里,OpenCV代替了图像,而在opencv/samples/cpp/文件夹中附带了一个数据文件
letter-recognitiontion.data。如果打开它,您将看到20000行,乍一看可能看起来像垃圾。实际上,在每一行中,第一列是一个字母,这是我们的标签。接下来的16个数字是它的不同功能。这些功能是从UCI机器学习存储库获得的。您可以在此页面中找到这些功能的详细信息。 现有20000个样本,因此我们将前10000个数据作为训练样本,其余10000个作为测试样本。我们应该将字母更改为ASCII字符,因为我们不能直接使用字母。
import cv2 as cv
import numpy as np
# 加载数据,转换器将字母转换为数字
data= np.loadtxt('letter-recognition.data', dtype= 'float32', delimiter = ',',
converters= {0: lambda ch: ord(ch)-ord('A')})
# 将数据分为两个,每个10000个以进行训练和测试
train, test = np.vsplit(data,2)
# 将火车数据和测试数据拆分为特征和响应
responses, trainData = np.hsplit(train,[1])
labels, testData = np.hsplit(test,[1])
# 初始化kNN, 分类, 测量准确性
knn = cv.ml.KNearest_create()
knn.train(trainData, cv.ml.ROW_SAMPLE, responses)
ret, result, neighbours, dist = knn.findNearest(testData, k=5)
correct = np.count_nonzero(result == labels)
accuracy = correct*100.0/10000
print( accuracy )
它给我的准确性为93.22%。同样,如果要提高准确性,则可以迭代地在每个级别中添加错误数据。
在这一章中
考虑下面的图像,它具有两种数据类型,红色和蓝色。在kNN中,对于测试数据,我们用来测量其与所有训练样本的距离,并以最小的距离作为样本。测量所有距离都需要花费大量时间,并且需要大量内存来存储所有训练样本。但是考虑到图像中给出的数据,我们是否需要那么多?
考虑另一个想法。我们找到一条线$f(x)=ax_1 + bx_2+c$,它将两条数据都分为两个区域。当我们得到一个新的test_data $X$时,只需将其替换为$f(x)$即可。如果$f(X)> 0$,则属于蓝色组,否则属于红色组。我们可以将此行称为“决策边界”。它非常简单且内存高效。可以将这些数据用直线(或高维超平面)一分为二的数据称为线性可分离数据。
因此,在上图中,你可以看到很多这样的行都是可能的。我们会选哪一个?非常直观地,我们可以说直线应该从所有点尽可能远地经过。为什么?因为传入的数据中可能会有噪音。此数据不应影响分类准确性。因此,走最远的分离线将提供更大的抗干扰能力。因此,SVM要做的是找到到训练样本的最小距离最大的直线(或超平面)。请参阅下面图像中穿过中心的粗线。
因此,要找到此决策边界,你需要训练数据。那么需要全部吗?并不用。仅接近相反组的那些就足够了。在我们的图像中,它们是一个蓝色填充的圆圈和两个红色填充的正方形。我们可以称其为支撑向量,通过它们的线称为支撑平面。它们足以找到我们的决策边界。我们不必担心所有数据。它有助于减少数据量。
接下来,找到了最能代表数据的前两个超平面。例如,蓝色数据由$w^Tx+b_0>-1$表示,红色数据由$wTx+b_0<-1$表示,其中$w$是权重向量($w=[w_1,w_2,...,w_n]$),$x$是特征向量($x =[x_1,x_2,...,x_n]$)。$b_0$是偏置。权重矢量确定决策边界的方向,而偏置点确定其位置。现在,将决策边界定义为这些超平面之间的中间,因此表示为$w^Tx + b_0 = 0$。从支持向量到决策边界的最小距离由$distance_{support vectors}=frac{1}{|w|}$给出。间隔是此距离的两倍,因此我们需要最大化此间隔。也就是说,我们需要使用一些约束来最小化新函数$L(w,b_0)$,这些约束可以表示如下:
其中$t_i$是每类的标签,t_i∈[-1,1]
考虑一些不能用直线分成两部分的数据。例如,考虑一维数据,其中'X'位于-3和+3,而'O'位于-1和+1。显然,它不是线性可分离的。但是有解决这些问题的方法。如果我们可以使用函数$f(x)=x^2$映射此数据集,则在线性可分离的9处获得'X',在1处获得'O'。
否则,我们可以将此一维数据转换为二维数据。我们可以使用$f(x)=(x,x^2)$函数来映射此数据。然后,'X'变成(-3,9)和(3,9),而'O'变成(-1,1)和(1,1)。这也是线性可分的。简而言之,低维空间中的非线性可分离数据更有可能在高维空间中变为线性可分离。
通常,可以将d维空间中的点映射到某个D维空间$(D> d)$,以检查线性可分离性的可能性。有一个想法可以通过在低维输入(特征)空间中执行计算来帮助在高维(内核)空间中计算点积。我们可以用下面的例子来说明。
考虑二维空间中的两个点,$p=(p_1,p_2)$和$q=(q_1,q_2)$。令$ϕ$为映射函数,它将二维点映射到三维空间,如下所示:
让我们定义一个核函数$K(p,q)$,该函数在两点之间做一个点积,如下所示:
这意味着,可以使用二维空间中的平方点积来实现三维空间中的点积。这可以应用于更高维度的空间。因此,我们可以从较低尺寸本身计算较高尺寸的特征。一旦将它们映射,我们将获得更高的空间。
除了所有这些概念之外,还存在分类错误的问题。因此,仅找到具有最大间隔的决策边界是不够的。我们还需要考虑分类错误的问题。有时,可能会找到间隔较少但分类错误减少的决策边界。无论如何,我们需要修改我们的模型,以便它可以找到具有最大间隔但分类错误较少的决策边界。最小化标准修改为:$min |w|^2+C$(分类错误的样本到其正确区域的距离)下图显示了此概念。对于训练数据的每个样本,定义一个新的参数$ξ_i$。它是从其相应的训练样本到其正确决策区域的距离。对于那些未分类错误的样本,它们落在相应的支撑平面上,因此它们的距离为零。
因此,新的优化函数为:
如何选择参数C?显然,这个问题的答案取决于训练数据的分布方式。尽管没有一般性的答案,但考虑以下规则是很有用的:
在本章中,我们将重新识别手写数据集,但是使用SVM而不是kNN。
在kNN中,我们直接使用像素强度作为特征向量。这次我们将使用定向梯度直方图(HOG)作为特征向量。
在这里,在找到HOG之前,我们使用其二阶矩对图像进行偏斜校正。因此,我们首先定义一个函数deskew(),该函数获取一个数字图像并将其校正。下面是deskew()函数:
def deskew(img):
m = cv.moments(img)
if abs(m['mu02']) < 1e-2:
return img.copy()
skew = m['mu11']/m['mu02']
M = np.float32([[1, skew, -0.5*SZ*skew], [0, 1, 0]])
img = cv.warpAffine(img,M,(SZ, SZ),flags=affine_flags)
return img
下图显示了应用于零图像的上偏移校正功能。左图像是原始图像,右图像是偏移校正后的图像。
接下来,我们必须找到每个单元格的HOG描述符。为此,我们找到了每个单元在X和Y方向上的Sobel导数。然后在每个像素处找到它们的大小和梯度方向。该梯度被量化为16个整数值。将此图像划分为四个子正方形。对于每个子正方形,计算权重大小方向的直方图(16个bin)。因此,每个子正方形为你提供了一个包含16个值的向量。(四个子正方形的)四个这样的向量共同为我们提供了一个包含64个值的特征向量。这是我们用于训练数据的特征向量。
def hog(img):
gx = cv.Sobel(img, cv.CV_32F, 1, 0)
gy = cv.Sobel(img, cv.CV_32F, 0, 1)
mag, ang = cv.cartToPolar(gx, gy)
bins = np.int32(bin_n*ang/(2*np.pi)) # quantizing binvalues in (0...16)
bin_cells = bins[:10,:10], bins[10:,:10], bins[:10,10:], bins[10:,10:]
mag_cells = mag[:10,:10], mag[10:,:10], mag[:10,10:], mag[10:,10:]
hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)]
hist = np.hstack(hists) # hist is a 64 bit vector
return hist
最后,与前面的情况一样,我们首先将大数据集拆分为单个单元格。对于每个数字,保留250个单元用于训练数据,其余250个数据保留用于测试。完整的代码如下,你也可以从此处下载:
#!/usr/bin/env python
import cv2 as cv
import numpy as np
SZ=20
bin_n = 16 # Number of bins
affine_flags = cv.WARP_INVERSE_MAP|cv.INTER_LINEAR
def deskew(img):
m = cv.moments(img)
if abs(m['mu02']) < 1e-2:
return img.copy()
skew = m['mu11']/m['mu02']
M = np.float32([[1, skew, -0.5*SZ*skew], [0, 1, 0]])
img = cv.warpAffine(img,M,(SZ, SZ),flags=affine_flags)
return img
def hog(img):
gx = cv.Sobel(img, cv.CV_32F, 1, 0)
gy = cv.Sobel(img, cv.CV_32F, 0, 1)
mag, ang = cv.cartToPolar(gx, gy)
bins = np.int32(bin_n*ang/(2*np.pi)) # quantizing binvalues in (0...16)
bin_cells = bins[:10,:10], bins[10:,:10], bins[:10,10:], bins[10:,10:]
mag_cells = mag[:10,:10], mag[10:,:10], mag[:10,10:], mag[10:,10:]
hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)]
hist = np.hstack(hists) # hist is a 64 bit vector
return hist
img = cv.imread('digits.png',0)
if img is None:
raise Exception("we need the digits.png image from samples/data here !")
cells = [np.hsplit(row,100) for row in np.vsplit(img,50)]
# First half is trainData, remaining is testData
train_cells = [ i[:50] for i in cells ]
test_cells = [ i[50:] for i in cells]
deskewed = [list(map(deskew,row)) for row in train_cells]
hogdata = [list(map(hog,row)) for row in deskewed]
trainData = np.float32(hogdata).reshape(-1,64)
responses = np.repeat(np.arange(10),250)[:,np.newaxis]
svm = cv.ml.SVM_create()
svm.setKernel(cv.ml.SVM_LINEAR)
svm.setType(cv.ml.SVM_C_SVC)
svm.setC(2.67)
svm.setGamma(5.383)
svm.train(trainData, cv.ml.ROW_SAMPLE, responses)
svm.save('svm_data.dat')
deskewed = [list(map(deskew,row)) for row in test_cells]
hogdata = [list(map(hog,row)) for row in deskewed]
testData = np.float32(hogdata).reshape(-1,bin_n*4)
result = svm.predict(testData)[1]
mask = result==responses
correct = np.count_nonzero(mask)
print(correct*100.0/result.size)
这种特殊的方法给我们近94%的准确性。你可以为SVM的各种参数尝试不同的值,以检查是否可以实现更高的精度。或者,你可以阅读有关此领域的技术论文并尝试实施它们。
在本章中,我们将了解K-Means聚类的概念,其工作原理等。
我们将用一个常用的例子来处理这个问题。
考虑一家公司,该公司将向市场发布新型号的T恤。显然,他们将不得不制造不同尺寸的模型,以满足各种规模的人们的需求。因此,该公司会记录人们的身高和体重数据,并将其绘制到图形上,如下所示:
公司无法制作所有尺寸的T恤。取而代之的是,他们将人划分为小,中和大,并仅制造这三种适合所有人的模型。可以通过k均值聚类将人员分为三组,并且算法可以为我们提供最佳的3种大小,这将满足所有人员的需求。如果不是这样,公司可以将人员分为更多的组,可能是五个,依此类推。查看下面的图片:
该算法是一个迭代过程。我们将在图像的帮助下逐步解释它。 考虑如下一组数据(您可以将其视为T恤问题)。我们需要将此数据分为两类。
步骤:1 -算法随机选择两个质心$C_1$和$C_2$(有时,将任何两个数据作为质心)。 步骤:2 -计算每个点到两个质心的距离。如果测试数据更接近$C_1$,则该数据标记为“0”。如果它更靠近$C_2$,则标记为“1”(如果存在更多质心,则标记为“2”,“3”等)。
在我们的示例中,我们将为所有标记为红色的“0”和标记为蓝色的所有“1”上色。因此,经过以上操作,我们得到以下图像。
步骤:3 -接下来,我们分别计算所有蓝点和红点的平均值,这将成为我们的新质心。即$C_1$和$C_2$转移到新计算的质心。(请记住,显示的图像不是真实值,也不是真实比例,仅用于演示)。
再次,使用新的质心执行步骤2,并将标签数据设置为'0'和'1'。
所以我们得到如下结果:
现在,迭代步骤2和步骤3,直到两个质心都收敛到固定点。(或者可以根据我们提供的标准(例如最大的迭代次数或达到特定的精度等)将其停止。)**这些点使测试数据与其对应质心之间的距离之和最小**。或者简单地说,$C_1↔Red_Points$和$C_2↔Blue_Points$之间的距离之和最小。
最终结果如下所示:
因此,这仅仅是对K-Means聚类的直观理解。有关更多详细信息和数学解释,请阅读任何标准的机器学习教科书或查看其他资源中的链接。它只是K-Means聚类的宏观层面。此算法有很多修改,例如如何选择初始质心,如何加快迭代过程等。
输出参数
考虑一下,你有一组仅具有一个特征(即一维)的数据。例如,我们可以解决我们的T恤问题,你只用身高来决定T恤的尺寸。因此,我们首先创建数据并将其绘制在Matplotlib中
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
x = np.random.randint(25,100,25)
y = np.random.randint(175,255,25)
z = np.hstack((x,y))
z = z.reshape((50,1))
z = np.float32(z)
plt.hist(z,256,[0,256]),plt.show()
因此,我们有了“ z”,它是一个大小为50的数组,值的范围是0到255。我将“z”重塑为列向量。 如果存在多个功能,它将更加有用。然后我制作了np.float32类型的数据。 我们得到以下图像:
现在我们应用KMeans函数。在此之前,我们需要指定标准。我的标准是,每当运行10次算法迭代或达到epsilon = 1.0的精度时,就停止算法并返回答案。
# 定义终止标准 = ( type, max_iter = 10 , epsilon = 1.0 )
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
# 设置标志
flags = cv.KMEANS_RANDOM_CENTERS
# 应用K均值
compactness,labels,centers = cv.kmeans(z,2,None,criteria,10,flags)
这为我们提供了紧凑性,标签和中心。在这种情况下,我得到的中心分别为60和207。标签的大小将与测试数据的大小相同,其中每个数据的质心都将标记为“ 0”,“ 1”,“ 2”等。现在,我们根据标签将数据分为不同的群集。
A = z[labels==0]
B = z[labels==1]
现在我们以红色绘制A,以蓝色绘制B,以黄色绘制其质心。
# 现在绘制用红色'A',用蓝色绘制'B',用黄色绘制中心
plt.hist(A,256,[0,256],color = 'r')
plt.hist(B,256,[0,256],color = 'b')
plt.hist(centers,32,[0,256],color = 'y')
plt.show()
得到了以下结果:
在前面的示例中,我们仅考虑了T恤问题的身高。在这里,我们将同时考虑身高和体重,即两个特征。 请记住,在以前的情况下,我们将数据制作为单个列向量。每个特征排列在一列中,而每一行对应于一个输入测试样本。 例如,在这种情况下,我们设置了一个大小为50x2的测试数据,即50人的身高和体重。第一列对应于全部50个人的身高,第二列对应于他们的体重。第一行包含两个元素,其中第一个是第一人称的身高,第二个是他的体重。类似地,剩余的行对应于其他人的身高和体重。查看下面的图片:
现在,我直接转到代码:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
X = np.random.randint(25,50,(25,2))
Y = np.random.randint(60,85,(25,2))
Z = np.vstack((X,Y))
# 将数据转换未 np.float32
Z = np.float32(Z)
# 定义停止标准,应用K均值
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
ret,label,center=cv.kmeans(Z,2,None,criteria,10,cv.KMEANS_RANDOM_CENTERS)
# 现在分离数据, Note the flatten()
A = Z[label.ravel()==0]
B = Z[label.ravel()==1]
# 绘制数据
plt.scatter(A[:,0],A[:,1])
plt.scatter(B[:,0],B[:,1],c = 'r')
plt.scatter(center[:,0],center[:,1],s = 80,c = 'y', marker = 's')
plt.xlabel('Height'),plt.ylabel('Weight')
plt.show()
我们得到如下结果:
颜色量化是减少图像中颜色数量的过程。这样做的原因之一是减少内存。有时,某些设备可能会受到限制,因此只能产生有限数量的颜色。同样在那些情况下,执行颜色量化。在这里,我们使用k均值聚类进行颜色量化。
这里没有新内容要解释。有3个特征,例如R,G,B。因此,我们需要将图像重塑为Mx3大小的数组(M是图像中的像素数)。在聚类之后,我们将质心值(也是R,G,B)应用于所有像素,以使生成的图像具有指定数量的颜色。再一次,我们需要将其重塑为原始图像的形状。下面是代码:
import numpy as np
import cv2 as cv
img = cv.imread('home.jpg')
Z = img.reshape((-1,3))
# 将数据转化为np.float32
Z = np.float32(Z)
# 定义终止标准 聚类数并应用k均值
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
K = 8
ret,label,center=cv.kmeans(Z,K,None,criteria,10,cv.KMEANS_RANDOM_CENTERS)
# 现在将数据转化为uint8, 并绘制原图像
center = np.uint8(center)
res = center[label.flatten()]
res2 = res.reshape((img.shape))
cv.imshow('res2',res2)
cv.waitKey(0)
cv.destroyAllWindows()
我们可以看的K=8的结果
在本章中,
在前面的章节中,我们已经看到了许多图像平滑技术,例如高斯模糊,中值模糊等,它们在某种程度上可以消除少量噪声。在这些技术中,我们在像素周围采取了一个较小的邻域,并进行了一些操作,例如高斯加权平均值,值的中位数等来替换中心元素。简而言之,在像素处去除噪声是其周围的局部现象。 有噪声的性质。
通常认为噪声是零均值的随机变量。考虑一个有噪声的像素,$p=p_0+n$,其中$p_0$是像素的真实值,$n$是该像素中的噪声。你可以从不同的图像中获取大量相同的像素(例如N)并计算其平均值。理想情况下,由于噪声的平均值为零,因此应该得到$p = p_0$。
你可以通过简单的设置自己进行验证。将静态相机固定在某个位置几秒钟。这将为你提供很多帧或同一场景的很多图像。然后编写一段代码,找到视频中所有帧的平均值(这对你现在应该太简单了)。 比较最终结果和第一帧。你会看到噪声减少。不幸的是,这种简单的方法对摄像机和场景的运动并不稳健。通常,只有一张嘈杂的图像可用。
因此想法很简单,我们需要一组相似的图像来平均噪声。考虑图像中的一个小窗口(例如5x5窗口)。 很有可能同一修补程序可能位于图像中的其他位置。有时在它周围的一个小社区中。一起使用这些相似的补丁并找到它们的平均值怎么办?对于那个特定的窗口,这很好。请参阅下面的示例图片:
图像中的蓝色补丁看起来很相似。绿色补丁看起来很相似。因此,我们获取一个像素,在其周围获取一个小窗口,在图像中搜索相似的窗口,对所有窗口求平均,然后用得到的结果替换该像素。此方法是“非本地均值消噪”。与我们之前看到的模糊技术相比,它花费了更多时间,但是效果非常好。更多信息和在线演示可在其他资源的第一个链接中找到。
对于彩色图像,图像将转换为CIELAB色彩空间,然后分别对L和AB分量进行降噪。
OpenCV提供了此方法的四个变体。
常用参数为:
请访问其他资源中的第一个链接,以获取有关这些参数的更多详细信息。 我们将在此处演示2和3。剩下的留给你。
如上所述,它用于消除彩色图像中的噪点。(噪声可能是高斯的)。请参阅以下示例:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('die.png')
dst = cv.fastNlMeansDenoisingColored(img,None,10,10,7,21)
plt.subplot(121),plt.imshow(img)
plt.subplot(122),plt.imshow(dst)
plt.show()
以下是结果的放大版本。我的输入图像的高斯噪声为σ= 25。查看结果:
现在,我们将对视频应用相同的方法。第一个参数是噪声帧列表。第二个参数 imgToDenoiseIndex 指定我们需要去噪的帧,为此,我们在输入列表中传递帧的索引。第三是 temporalWindowSize,它指定要用于降噪的附近帧的数量。应该很奇怪。在那种情况下,总共使用 temporalWindowSize 帧,其中中心帧是要被去噪的帧。例如,你传递了一个5帧的列表作为输入。令 imgToDenoiseIndex = 2 , temporalWindowSize =3。然后使用 frame-1,frame-2 和 frame-3 去噪 frame-2。让我们来看一个例子。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
cap = cv.VideoCapture('vtest.avi') # 创建5个帧的列表
img = [cap.read()[1] for i in xrange(5)] # 将所有转化为灰度
gray = [cv.cvtColor(i, cv.COLOR_BGR2GRAY) for i in img] # 将所有转化为float64
gray = [np.float64(i) for i in gray] # 创建方差为25的噪声
noise = np.random.randn(*gray[1].shape)*10 # 在图像上添加噪声
noisy = [i+noise for i in gray] # 转化为unit8
noisy = [np.uint8(np.clip(i,0,255)) for i in noisy] # 对第三帧进行降噪
dst = cv.fastNlMeansDenoisingMulti(noisy, 2, 5, None, 4, 7, 35)
plt.subplot(131),plt.imshow(gray[2],'gray')
plt.subplot(132),plt.imshow(noisy[2],'gray')
plt.subplot(133),plt.imshow(dst,'gray') plt.show()
计算需要花费大量时间。结果,第一个图像是原始帧,第二个是噪声帧,第三个是去噪图像。
在本章中,
你们大多数人家里都会有一些旧的旧化照片,上面有黑点,一些笔触等。你是否曾经想过将其还原?我们不能简单地在绘画工具中擦除它们,因为它将简单地用白色结构代替黑色结构,这是没有用的。在这些情况下,将使用一种称为图像修复的技术。基本思想很简单:用附近的像素替换那些不良区域,使其看起来和邻近的协调。考虑下面显示的图像(摘自Wikipedia):
基于此目的设计了几种算法,OpenCV提供了其中两种。 两者都可以通过相同的函数进行访问,cv.inpaint()
第一种算法基于Alexandru Telea在2004年发表的论文“基于快速行进方法的图像修补技术”。它基于快速行进方法。考虑图像中要修复的区域。算法从该区域的边界开始,并进入该区域内部,首先逐渐填充边界中的所有内容。在要修复的邻域上的像素周围需要一个小的邻域。该像素被附近所有已知像素的归一化加权总和所代替。权重的选择很重要。那些位于该点附近,边界法线附近的像素和那些位于边界轮廓线上的像素将获得更大的权重。修复像素后,将使用快速行进方法将其移动到下一个最近的像素。FMM确保首先修复已知像素附近的那些像素,以便像手动启发式操作一样工作。通过使用标志cv.INPAINT_TELEA启用此算法。
第二种算法基于Bertalmio,Marcelo,Andrea L. Bertozzi和Guillermo Sapiro在2001年发表的论文“ Navier-Stokes,流体动力学以及图像和视频修补”。该算法基于流体动力学并利用了 偏微分方程。基本原理是启发式的。它首先沿着边缘从已知区域移动到未知区域(因为边缘是连续的)。它延续了等距线(线连接具有相同强度的点,就像轮廓线连接具有相同高程的点一样),同时在修复区域的边界匹配梯度矢量。为此,使用了一些流体动力学方法。获得它们后,将填充颜色以减少该区域的最小差异。通过使用标志cv.INPAINT_NS启用此算法。
我们需要创建一个与输入图像大小相同的掩码,其中非零像素对应于要修复的区域。其他一切都很简单。我的图像因一些黑色笔画而旧化(我手动添加了)。我使用“绘画”工具创建了相应的笔触。
import numpy as np
import cv2 as cv
img = cv.imread('messi_2.jpg')
mask = cv.imread('mask2.png',0)
dst = cv.inpaint(img,mask,3,cv.INPAINT_TELEA)
cv.imshow('dst',dst)
cv.waitKey(0)
cv.destroyAllWindows()
请参阅下面的结果。第一张图片显示了降级的输入。第二个图像是掩码。第三个图像是第一个算法的结果,最后一个图像是第二个算法的结果。
在本章中,我们将
高动态范围成像(HDRI或HDR)是一种用于成像和摄影的技术,可以比标准数字成像或摄影技术重现更大的动态亮度范围。虽然人眼可以适应各种光照条件,但是大多数成像设备每通道使用8位,因此我们仅限于256级。当我们拍摄现实世界的照片时,明亮的区域可能会曝光过度,而黑暗的区域可能会曝光不足,因此我们无法一次拍摄所有细节。HDR成像适用于每个通道使用8位以上(通常为32位浮点值)的图像,从而允许更大的动态范围。
获取HDR图像的方法有多种,但是最常见的一种方法是使用以不同曝光值拍摄的场景照片。要综合这些曝光,了解相机的响应功能以及估算算法的功能非常有用。合并HDR图像后,必须将其转换回8位才能在常规显示器上查看。此过程称为音调映射。当场景或摄像机的对象在两次拍摄之间移动时,还会增加其他复杂性,因为应记录并调整具有不同曝光度的图像。
在本教程中,我们展示了两种算法(Debevec,Robertson)来根据曝光序列生成和显示HDR图像,并演示了另一种称为曝光融合(Mertens)的方法,该方法可以生成低动态范围图像,并且不需要曝光时间数据。此外,我们估计相机响应函数(CRF)对于许多计算机视觉算法都具有重要价值。HDR流水线的每个步骤都可以使用不同的算法和参数来实现,因此请查看参考手册以了解所有内容。
在本教程中,我们将查看以下场景,其中有4张曝光图像,曝光时间分别为15、2.5、1 / 4和1/30秒。 (你可以从Wikipedia下载图像)
1. 将曝光图像加载到列表中
import cv2 as cv
import numpy as np
# 将曝光图像加载到列表中
img_fn = ["img0.jpg", "img1.jpg", "img2.jpg", "img3.jpg"]
img_list = [cv.imread(fn) for fn in img_fn]
exposure_times = np.array([15.0, 2.5, 0.25, 0.0333], dtype=np.float32)
2. 将曝光合成HDR图像 在此阶段,我们将曝光序列合并为一张HDR图像,显示了OpenCV中的两种可能性。 第一种方法是Debevec,第二种方法是Robertson。 请注意,HDR图像的类型为float32,而不是uint8,因为它包含所有曝光图像的完整动态范围。
# 将曝光合成HDR图像
merge_debevec = cv.createMergeDebevec()
hdr_debevec = merge_debevec.process(img_list, times=exposure_times.copy())
merge_robertson = cv.createMergeRobertson()
hdr_robertson = merge_robertson.process(img_list, times=exposure_times.copy())
3. 色调图HDR图像 我们将32位浮点HDR数据映射到[0..1]范围内。实际上,在某些情况下,该值可以大于1或小于0,因此请注意,我们稍后将必须裁剪数据以避免溢出。
# 色调图HDR图像
tonemap1 = cv.createTonemap(gamma=2.2)
res_debevec = tonemap1.process(hdr_debevec.copy())
4. 使用Mertens融合曝光 在这里,我们展示了一种替代算法,用于合并曝光图像,而我们不需要曝光时间。我们也不需要使用任何色调映射算法,因为Mertens算法已经为我们提供了[0..1]范围内的结果。
# 使用Mertens融合曝光
merge_mertens = cv.createMergeMertens()
res_mertens = merge_mertens.process(img_list)
5. 转为8-bit并保存 为了保存或显示结果,我们需要将数据转换为[0..255]范围内的8位整数。
# 转化数据类型为8-bit并保存
res_debevec_8bit = np.clip(res_debevec*255, 0, 255).astype('uint8')
res_robertson_8bit = np.clip(res_robertson*255, 0, 255).astype('uint8')
res_mertens_8bit = np.clip(res_mertens*255, 0, 255).astype('uint8')
cv.imwrite("ldr_debevec.jpg", res_debevec_8bit)
cv.imwrite("ldr_robertson.jpg", res_robertson_8bit)
cv.imwrite("fusion_mertens.jpg", res_mertens_8bit)
你可以看到不同的结果,但是请考虑到每种算法都有其他额外的参数,你应该将它们附加以达到期望的结果。 最佳实践是尝试不同的方法,然后看看哪种方法最适合你的场景。
Debevec:
Robertson:
Mertenes融合
摄像机响应功能(CRF)使我们可以将场景辐射度与测量强度值联系起来。CRF在某些计算机视觉算法(包括HDR算法)中非常重要。在这里,我们估计逆相机响应函数并将其用于HDR合并。
# 估计相机响应函数(CRF)
cal_debevec = cv.createCalibrateDebevec()
crf_debevec = cal_debevec.process(img_list, times=exposure_times)
hdr_debevec = merge_debevec.process(img_list, times=exposure_times.copy(), response=crf_debevec.copy())
cal_robertson = cv.createCalibrateRobertson()
crf_robertson = cal_robertson.process(img_list, times=exposure_times)
hdr_robertson = merge_robertson.process(img_list, times=exposure_times.copy(), response=crf_robertson.copy())
相机响应功能由每个颜色通道的256长度向量表示。 对于此序列,我们得到以下估计:
在本教程中,
使用基于Haar特征的级联分类器的对象检测是Paul Viola和Michael Jones在其论文“使用简单特征的增强级联进行快速对象检测”中于2001年提出的一种有效的对象检测方法。这是一种基于机器学习的方法,其中从许多正负图像中训练级联函数。然后用于检测其他图像中的对象。
在这里,我们将进行人脸检测。最初,该算法需要大量正图像(面部图像)和负图像(无面部图像)来训练分类器。 然后,我们需要从中提取特征。为此,使用下图所示的Haar功能。 它们就像我们的卷积核一样。 每个特征都是通过从黑色矩形下的像素总和中减去白色矩形下的像素总和而获得的单个值。
现在,每个内核的所有可能大小和位置都用于计算许多功能。(试想一下它产生多少计算?即使是一个24x24的窗口也会产生超过160000个特征)。对于每个特征计算,我们需要找到白色和黑色矩形下的像素总和。为了解决这个问题,他们引入了整体图像。无论你的图像有多大,它都会将给定像素的计算减少到仅涉及四个像素的操作。很好,不是吗?它使事情变得更快。
但是在我们计算的所有这些特征中,大多数都不相关。例如,考虑下图。第一行显示了两个良好的特征。选择的第一个特征似乎着眼于眼睛区域通常比鼻子和脸颊区域更暗的性质。选择的第二个特征依赖于眼睛比鼻梁更黑的属性。但是,将相同的窗口应用于脸颊或其他任何地方都是无关紧要的。那么,我们如何从16万多个功能中选择最佳特征?它是由Adaboost实现的。
为此,我们将所有特征应用于所有训练图像。对于每个特征,它会找到最佳的阈值,该阈值会将人脸分为正面和负面。显然,会出现错误或分类错误。我们选择错误率最低的特征,这意味着它们是对人脸和非人脸图像进行最准确分类的特征。 (此过程并非如此简单。在开始时,每个图像的权重均相等。在每次分类后,错误分类的图像的权重都会增加。然后执行相同的过程。将计算新的错误率。还要计算新的权重。继续进行此过程,直到达到所需的精度或错误率或找到所需的功能数量为止。
最终分类器是这些弱分类器的加权和。之所以称为弱分类,是因为仅凭它不能对图像进行分类,而是与其他分类一起形成强分类器。该论文说,甚至200个功能都可以提供95%的准确度检测。他们的最终设置具有大约6000个功能。 (想象一下,从160000多个功能减少到6000个功能。这是很大的收获)。
因此,现在你拍摄一张照片。取每个24x24窗口。向其应用6000个功能。检查是否有脸。哇..这不是效率低下又费时吗?是的。作者对此有一个很好的解决方案。
在图像中,大多数图像是非面部区域。因此,最好有一种简单的方法来检查窗口是否不是面部区域。如果不是,请一次性丢弃它,不要再次对其进行处理。相反,应将重点放在可能有脸的区域。这样,我们将花费更多时间检查可能的面部区域。
为此,他们引入了级联分类器的概念。不是将所有6000个功能部件应用到一个窗口中,而是将这些功能部件分组到不同的分类器阶段,并一一应用。 (通常前几个阶段将包含很少的功能)。如果窗口在第一阶段失败,则将其丢弃。我们不考虑它的其余功能。如果通过,则应用功能的第二阶段并继续该过程。经过所有阶段的窗口是一个面部区域。这个计划怎么样!
作者的检测器具有6000多个特征,具有38个阶段,在前五个阶段具有1、10、25、25和50个特征。 (上图中的两个功能实际上是从Adaboost获得的最佳两个功能)。根据作者的说法,每个子窗口平均评估了6000多个特征中的10个特征。
因此,这是Viola-Jones人脸检测工作原理的简单直观说明。阅读本文以获取更多详细信息,或查看其他资源部分中的参考资料。
OpenCV提供了一种训练方法(请参阅Cascade分类器训练)或预先训练的模型,可以使用
cv::CascadeClassifier::load方法读取。预训练的模型位于OpenCV安装的data文件夹中,或在此处找到。
以下代码示例将使用预训练的Haar级联模型来检测图像中的面部和眼睛。首先,创建一个cv::CascadeClassifier并使用
cv::CascadeClassifier::load方法加载必要的XML文件。然后,使用
cv::CascadeClassifier::detectMultiScale方法完成检测,该方法返回检测到的脸部或眼睛的边界矩形。
本教程的代码如下所示。你也可以从这里下载
from __future__ import print_function
import cv2 as cv
import argparse
def detectAndDisplay(frame):
frame_gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
frame_gray = cv.equalizeHist(frame_gray)
#-- 检测面部
faces = face_cascade.detectMultiScale(frame_gray)
for (x,y,w,h) in faces:
center = (x + w//2, y + h//2)
frame = cv.ellipse(frame, center, (w//2, h//2), 0, 0, 360, (255, 0, 255), 4)
faceROI = frame_gray[y:y+h,x:x+w]
#-- 在每张面部上检测眼睛
eyes = eyes_cascade.detectMultiScale(faceROI)
for (x2,y2,w2,h2) in eyes:
eye_center = (x + x2 + w2//2, y + y2 + h2//2)
radius = int(round((w2 + h2)*0.25))
frame = cv.circle(frame, eye_center, radius, (255, 0, 0 ), 4)
cv.imshow('Capture - Face detection', frame)
parser = argparse.ArgumentParser(description='Code for Cascade Classifier tutorial.')
parser.add_argument('--face_cascade', help='Path to face cascade.', default='data/haarcascades/haarcascade_frontalface_alt.xml')
parser.add_argument('--eyes_cascade', help='Path to eyes cascade.', default='data/haarcascades/haarcascade_eye_tree_eyeglasses.xml')
parser.add_argument('--camera', help='Camera divide number.', type=int, default=0)
args = parser.parse_args()
face_cascade_name = args.face_cascade
eyes_cascade_name = args.eyes_cascade
face_cascade = cv.CascadeClassifier()
eyes_cascade = cv.CascadeClassifier()
#-- 1. 加载级联
if not face_cascade.load(cv.samples.findFile(face_cascade_name)):
print('--(!)Error loading face cascade')
exit(0)
if not eyes_cascade.load(cv.samples.findFile(eyes_cascade_name)):
print('--(!)Error loading eyes cascade')
exit(0)
camera_device = args.camera
#-- 2. 读取视频流
cap = cv.VideoCapture(camera_device)
if not cap.isOpened:
print('--(!)Error opening video capture')
exit(0)
while True:
ret, frame = cap.read()
if frame is None:
print('--(!) No captured frame -- Break!')
break
detectAndDisplay(frame)
if cv.waitKey(10) == 27:
break
结果
请确保程序会找到文件
haarcascade_frontalface_alt.xml和haarcascade_eye_tree_eyeglasses.xml的路径。它们位于opencv/data/ haarcascades中
使用弱分类器的增强级联包括两个主要阶段:训练阶段和检测阶段。对象检测教程中介绍了使用基于HAAR或LBP模型的检测阶段。本文档概述了训练自己的弱分类器的级联所需的功能。当前指南将逐步完成所有不同阶段:收集训练数据,准备训练数据并执行实际模型训练。
为了支持本教程,将使用几个官方的OpenCV应用程序:opencv_createsamples,opencv_annotation,opencv_traincascade和opencv_visualisation。
重要的事项
为了训练弱分类器的增强级联,我们需要一组正样本(包含您要检测的实际对象)和一组负样本(包含您不想检测的所有内容)。负样本集必须手动准备,而阳性样本集是使用opencv_createsamples应用程序创建的。
负样本 负样本取自任意图像,不包含要检测的对象。这些生成样本的负片图像应列在一个特殊的负片图像文件中,该文件每行包含一个图像路径(可以是绝对路径,也可以是相对路径)。注意,负样本和样本图像也称为背景样本或背景图像,在本文档中可以互换使用。
所描述的图像可能具有不同的尺寸。但是,每个图像都应等于或大于所需的训练窗口大小(与模型尺寸相对应,多数情况下是对象的平均大小),因为这些图像用于将给定的负像子采样为几个图像 具有此训练窗口大小的样本。
负样本描述文件的示例:目录结构:
/img
img1.jpg
img2.jpg
bg.txt
文件 bg.txt
img/img1.jpg
img/img2.jpg
您的一组负窗口样本将用于模型训练,在这种情况下,当尝试查找您感兴趣的对象时,可以增强不需要查找的内容。
正样本由opencv_createsamples应用程序创建。提升过程使用它们来定义在尝试找到感兴趣的对象时模型应实际寻找的内容。该应用程序支持两种生成正样本数据集的方式。
第一种方法采用带有公司徽标的单个对象图像,并通过随机旋转对象,更改图像强度以及将图像放置在任意背景上,从给定的对象图像中创建大量正样本。随机性的数量和范围可以通过opencv_createsamples应用程序的命令行参数来控制。
命令行参数:
当以此方式运行opencv_createsamples时,将使用以下过程创建示例对象实例:给定的源图像围绕所有三个轴随机旋转。 所选角度受-maxxangle,-maxyangle和-maxzangle限制。 然后,像素在[
bg_color-bg_color_threshold; bg_color + bg_color_threshold]范围内被设置为透明。白噪声被添加到前景的强度。如果指定了-inv键,则前景像素强度将反转。如果指定了-randinv键,则算法将随机选择是否应对该样本应用反演。最后,将获得的图像从背景描述文件放置到任意背景上,将其大小调整为由-w和-h指定的所需大小,并存储到由-vec命令行选项指定的vec文件中。
也可以从以前标记的图像的集合中获取正样本,这是构建鲁棒对象模型时的理想方式。该集合由类似于背景描述文件的文本文件描述。该文件的每一行都对应一个图像。该行的第一个元素是文件名,后跟对象注释的数量,后跟描述包围矩形(x,y,宽度,高度)的对象坐标的数字。
一个描述文件的示例:
目录结构:
/img
img1.jpg
img2.jpg info.dat
文件 info.dat
img/img1.jpg 1 140 100 45 45
img/img2.jpg 2 100 200 50 50 50 30 25 25
图像img1.jpg包含具有以下边界矩形坐标的单个对象实例:(140,100,45,45)。图像img2.jpg包含两个对象实例。
为了从此类集合创建正样本,应指定-info参数而不是-img:
请注意,在这种情况下,-bg,-bgcolor,-bgthreshold,-inv,-randinv,-maxxangle,-maxyangle和-maxzangle等参数将被简单地忽略并且不再使用。在这种情况下,样本创建的方案如下。通过从原始图像中切出提供的边界框,从给定图像中获取对象实例。然后将它们调整为目标样本大小(由-w和-h定义),并存储在由-vec参数定义的输出vec文件中。没有应用任何失真,因此仅有的影响参数是-w,-h,-show和-num。
也可以使用opencv_annotation工具完成手动创建-info文件的过程。这是一个开放源代码工具,用于在任何给定图像中直观地选择对象实例的关注区域。以下小节将详细讨论如何使用此应用程序。
额外事项
使用OpenCV中的集成标注工具 从OpenCV 3.x开始,社区一直在提供和维护开源注释工具,该工具用于生成-info文件。如果构建了OpenCV应用程序,则可以通过命令opencv_annotation访问该工具。
使用该工具非常简单。该工具接受几个必需参数和一些可选参数:
请注意,可选参数只能一起使用。可以使用的命令示例如下所示
opencv_annotation --annotations=/path/to/annotations/file.txt --images=/path/to/image/folder/
此命令将启动一个窗口,其中包含第一张图像和您的鼠标光标,这些窗口将用于注释。有关如何使用注释工具的视频,请参见此处。基本上,有几个按键可以触发一个动作。鼠标左键用于选择对象的第一个角,然后继续绘制直到您满意为止,并在单击鼠标第二次单击时停止。每次选择后,您有以下选择:
最后,您将获得一个可用的注释文件,该文件可以传递给opencv_createsamples的-info参数。
下一步是根据预先准备的正负数据集对弱分类器的增强级联进行实际训练。
按用途分组的opencv_traincascade应用程序的命令行参数:
常用参数
级联参数:
提升分类器参数:
opencv_traincascade应用程序完成工作后,经过训练的级联将保存在-data文件夹中的cascade.xml文件中。此文件夹中的其他文件是为中断培训而创建的,因此您可以在训练完成后将其删除。
训练完成后,您可以测试级联分类器!
有时,可视化经过训练的级联可能很有用,以查看其选择的功能以及其阶段的复杂程度。为此,OpenCV提供了一个opencv_visualisation应用程序。该应用程序具有以下命令:
当前可视化工具的某些限制
HAAR / LBP人脸模型的示例在安吉丽娜·朱莉(Angelina Jolie)的给定窗口上运行,该窗口具有与级联分类器文件相同的预处理–> 24x24像素图像,灰度转换和直方图均衡:每个阶段都会制作一个视频,每个特征都可视化:
每个阶段都会制作一个视频,以显示每个功能:
每个阶段都作为图像存储,以供将来对功能进行验证:
这项工作是由StevenPuttemans为OpenCV 3 Blueprints创建的,但是Packt Publishing同意将其集成到OpenCV中。
了解:
在OpenCV中,所有算法均以C ++实现。但是这些算法可以从不同的语言(例如Python,JAVA等)中使用。绑定生成器使这成为可能。这些生成器在C ++和Python之间建立了桥梁,使用户能够从Python调用C ++函数。为了全面了解后台发生的事情,需要对Python / C API有充分的了解。在官方Python文档中可以找到一个有关将C ++函数扩展到Python的简单示例[1]。因此,通过手动编写包装函数将OpenCV中的所有函数扩展到Python是一项耗时的任务。因此,OpenCV以更智能的方式进行操作。 OpenCV使用位于modules/python/src2中的一些Python脚本,从C ++头自动生成这些包装器函数。我们将调查他们的工作。
首先,modules/python / CMakeFiles.txt是一个CMake脚本,用于检查要扩展到Python的模块。它将自动检查所有要扩展的模块并获取其头文件。这些头文件包含该特定模块的所有类,函数,常量等的列表。
其次,将这些头文件传递到Python脚本
modules/python/src2/gen2.py。这是Python Binding生成器脚本。它调用另一个Python脚本module/python/src2/hdr_parser.py。这是标头解析器脚本。此标头解析器将完整的标头文件拆分为较小的Python列表。因此,这些列表包含有关特定函数,类等的所有详细信息。例如,将对一个函数进行解析以获取一个包含函数名称,返回类型,输入参数,参数类型等的列表。最终列表包含所有函数,枚举的详细信息,头文件中的structs,classs等。
但是标头解析器不会解析标头文件中的所有函数/类。开发人员必须指定应将哪些函数导出到Python。为此,在这些声明的开头添加了某些宏,这些宏使标头解析器可以标识要解析的函数。这些宏由对特定功能进行编程的开发人员添加。简而言之,开发人员决定哪些功能应该扩展到Python,哪些不应该。这些宏的详细信息将在下一个会话中给出。
因此头解析器将返回已解析函数的最终大列表。我们的生成器脚本(gen2.py)将为标头解析器解析的所有函数/类/枚举/结构创建包装函数(你可以在编译期间在build/modules/python/文件夹中以pyopencv_genic_*.h文件找到这些标头文件)。但是可能会有一些基本的OpenCV数据类型,例如Mat,Vec4i,Size。它们需要手动扩展。例如,Mat类型应扩展为Numpy数组,Size应扩展为两个整数的元组,等等。类似地,可能会有一些复杂的结构/类/函数等需要手动扩展。所有这些手动包装函数都放在
modules/python/src2/cv2.cpp中。
所以现在剩下的就是这些包装文件的编译了,这给了我们cv2模块。因此,当你调用函数时,例如在Python中说res = equalizeHist(img1,img2),你将传递两个numpy数组,并期望另一个numpy数组作为输出。因此,将这些numpy数组转换为cv::Mat,然后在C++中调用equalizeHist()函数。最终结果将res转换回Numpy数组。简而言之,几乎所有操作都是在C++中完成的,这给了我们几乎与C++相同的速度。
因此,这是OpenCV-Python bindings生成方式的基本形式。
头解析器根据添加到函数声明中的一些包装宏来解析头文件。 枚举常量不需要任何包装宏。 它们会自动包装。 但是其余的函数,类等需要包装宏。
使用CV_EXPORTS_W宏扩展功能。 一个例子如下所示。
CV_EXPORTS_W void equalizeHist( InputArray src, OutputArray dst );
标头解析器可以理解诸如InputArray,OutputArray等关键字的输入和输出参数。但是有时,我们可能需要对输入和输出进行硬编码。 为此,使用了CV_OUT,CV_IN_OUT等宏。
CV_EXPORTS_W void minEnclosingCircle( InputArray points,
CV_OUT Point2f& center, CV_OUT float& radius );
对于大类,也使用CV_EXPORTS_W。为了扩展类方法,使用CV_WRAP。同样,CV_PROP用于类字段。
class CV_EXPORTS_W CLAHE : public Algorithm
{
public:
CV_WRAP virtual void apply(InputArray src, OutputArray dst) = 0;
CV_WRAP virtual void setClipLimit(double clipLimit) = 0;
CV_WRAP virtual double getClipLimit() const = 0;
}
可以使用CV_EXPORTS_AS扩展重载的函数。 但是我们需要传递一个新名称,以便在Python中使用该名称调用每个函数。 以下面的积分函数为例。 提供了三个函数,因此每个函数在Python中都带有一个后缀。 类似地,CV_WRAP_AS可用于包装重载方法。
CV_EXPORTS_W void integral( InputArray src, OutputArray sum, int sdepth = -1 );
CV_EXPORTS_AS(integral2) void integral( InputArray src, OutputArray sum,
OutputArray sqsum, int sdepth = -1, int sqdepth = -1 );
CV_EXPORTS_AS(integral3) void integral( InputArray src, OutputArray sum,
OutputArray sqsum, OutputArray tilted,
int sdepth = -1, int sqdepth = -1 );
小类/结构使用CV_EXPORTS_W_SIMPLE进行扩展。 这些结构按值传递给C ++函数。 示例包括KeyPoint,Match等。它们的方法由CV_WRAP扩展,而字段由CV_PROP_RW扩展。
class CV_EXPORTS_W_SIMPLE DMatch
{
public:
CV_WRAP DMatch();
CV_WRAP DMatch(int _queryIdx, int _trainIdx, float _distance);
CV_WRAP DMatch(int _queryIdx, int _trainIdx, int _imgIdx, float _distance);
CV_PROP_RW int queryIdx; // query descriptor index
CV_PROP_RW int trainIdx; // train descriptor index
CV_PROP_RW int imgIdx; // train image index
CV_PROP_RW float distance;
};
可以使用CV_EXPORTS_W_MAP导出其他一些小类/结构,并将其导出到Python本机字典中。Moments()就是一个例子。
class CV_EXPORTS_W_MAP Moments
{
public:
CV_PROP_RW double m00, m10, m01, m20, m11, m02, m30, m21, m12, m03;
CV_PROP_RW double mu20, mu11, mu02, mu30, mu21, mu12, mu03;
CV_PROP_RW double nu20, nu11, nu02, nu30, nu21, nu12, nu03;
};
因此,这些是OpenCV中可用的主要扩展宏。通常,开发人员必须将适当的宏放在适当的位置。其余的由生成器脚本完成。有时,在某些特殊情况下,生成器脚本无法创建包装。此类函数需要手动处理,为此,你需要编写自己的pyopencv_*.hpp扩展标头,并将其放入模块的misc / python子目录中。但是大多数时候,根据OpenCV编码指南编写的代码将由生成器脚本自动包装。
更高级的情况涉及为Python提供C ++接口中不存在的其他功能,例如额外的方法,类型映射或提供默认参数。稍后,我们将以UMat数据类型为例。首先,要提供特定于Python的方法,CV_WRAP_PHANTOM的用法与CV_WRAP相似,不同之处在于它以方法标头作为参数,并且你需要在自己的pyopencv_*.hpp扩展名中提供方法主体。 UMat::queue()和UMat::context()是此类幻象方法的示例,这些幻象方法在C++接口中不存在,但在Python端处理OpenCL功能时需要使用。其次,如果一个已经存在的数据类型可以映射到你的类,则最好使用CV_WRAP_MAPPABLE以源类型作为其参数来指示这种容量,而不是精心设计自己的绑定函数。从Mat映射的UMat就是这种情况。最后,如果需要默认参数,但本机C++接口中未提供,则可以在Python端将其作为CV_WRAP_DEFAULT的参数提供。按照下面的UMat::getMat示例:
class CV_EXPORTS_W UMat
{
public:
// 你需要提供 `static bool cv_mappable_to(const Ptr<Mat>& src, Ptr<UMat>& dst)`
CV_WRAP_MAPPABLE(Ptr<Mat>);
/! returns the OpenCL queue used by OpenCV UMat.
// 你需要在资料夹代码中提供方法主体
CV_WRAP_PHANTOM(static void* queue());
// 你需要在资料夹代码中提供方法主体
CV_WRAP_PHANTOM(static void* context());
CV_WRAP_AS(get) Mat getMat(int flags CV_WRAP_DEFAULT(ACCESS_RW)) const;
};
原创:人工智能遇见磐创
编辑:IT智能化专栏编辑