一谈到golang,大家的第一感觉就是高并发,高性能。但是语言本身的优势是不是,就让程序员觉得编写高性能的处理系统变得轻而易举,水到渠成呢。下面这篇文章给大家的提醒便是,我们只有在充分理解语言本身的特性,并巧妙加以利用的前提下,才能写出高性能、高并发的处理程序,才能为企业节省成本,为客户提供好的服务。
Malwarebytes的首席架构师Marcio Castilho分享了他在公司高速发展过程中,开发高性能数据处理系统的经历。整个过程向我们详细展示了如何不断的优化与提升系统性能的过程,值得我们思考与学习。大佬也不是一下子就给出最优方案的。
首先作者的目标是能够处理来自数百万个端点的大量POST请求,然后将接收到的JSON 请求体,写入Amazon S3,以便map-reduce稍后对这些数据进行操作。这个场景和我们现在的很多互联网系统的场景是一样的。传统的处理方式是,使用队列等中间件,做缓冲,消峰,然后后端一堆worker来异步处理。因为作者也做了两年GO开发了,经过讨论他们决定使用GO来完成这项工作。
下面是Marcio给出的本能第一反应的解决方案,和大家的思路是不是一致的。首先他给出了负载(Payload)还有负载集合(PayloadCollection)的定义,然后他写了一个处理web请求的Handler(payloadHandler)。在payloadHandler里面,由于把负载上传S3比较耗时,所以针对每个负载,启动GO的协程来异步上传。具体的实现,大家可以看下面48-50行贴出的代码。
type PayloadCollection struct {
windowsVersion string `json:"version"`
Token string `json:"token"`
Payloads []Payload `json:"data"`
}
type Payload struct {
// [redacted]
}
func (p *Payload) UploadToS3() error {
// the storageFolder method ensures that there are no name collision in
// case we get same timestamp in the key name
storage_path := fmt.Sprintf("%v/%v", p.storageFolder, time.Now().UnixNano())
bucket := S3Bucket
b := new(bytes.Buffer)
encodeErr := json.NewEncoder(b).Encode(payload)
if encodeErr != nil {
return encodeErr
}
// Everything we post to the S3 bucket should be marked 'private'
var acl = s3.Private
var contentType = "Application/octet-stream"
return bucket.PutReader(storage_path, b, int64(b.Len()), contentType, acl, s3.Options{})
}
func payloadHandler(w http.ResponseWriter, r *http.Request) {
if r.Method != "POST" {
w.WriteHeader(http.StatusMethodNotAllowed)
return
}
// Read the body into a string for json decoding
var content = &PayloadCollection{}
err := json.NewDecoder(io.LimitReader(r.Body, MaxLength)).Decode(&content)
if err != nil {
w.Header().Set("Content-Type", "application/json; charset=UTF-8")
w.WriteHeader(http.StatusBadRequest)
return
}
// Go through each payload and queue items individually to be posted to S3
for _, payload := range content.Payloads {
go payload.UploadToS3() // <----- DON'T DO THIS
}
w.WriteHeader(http.StatusOK)
}
那结果怎么样呢?Marcio和他的同事们低估了请求的量级,而且上面的实现方法,又无法控制GO协程的生成数量,这个版本部署到生产后,很快就崩溃了。Marcio毕竟是牛逼架构师,他很快根据问题给出了新的解决方案。
第一个版本的假设是,请求的生命周期都是很短的,不会有长时间的阻塞操作耗费资源。在这个前提下,我们可以根据请求不停的生成GO协程来处理请求。但是事实并非如此,Marcio转变思路,引入队列的思想。创建了Buffered Channel,把请求缓冲起来,然后再通过一个同步处理器从Channel里面把请求取出,上传S3.这是典型的生产者-消费者模型。

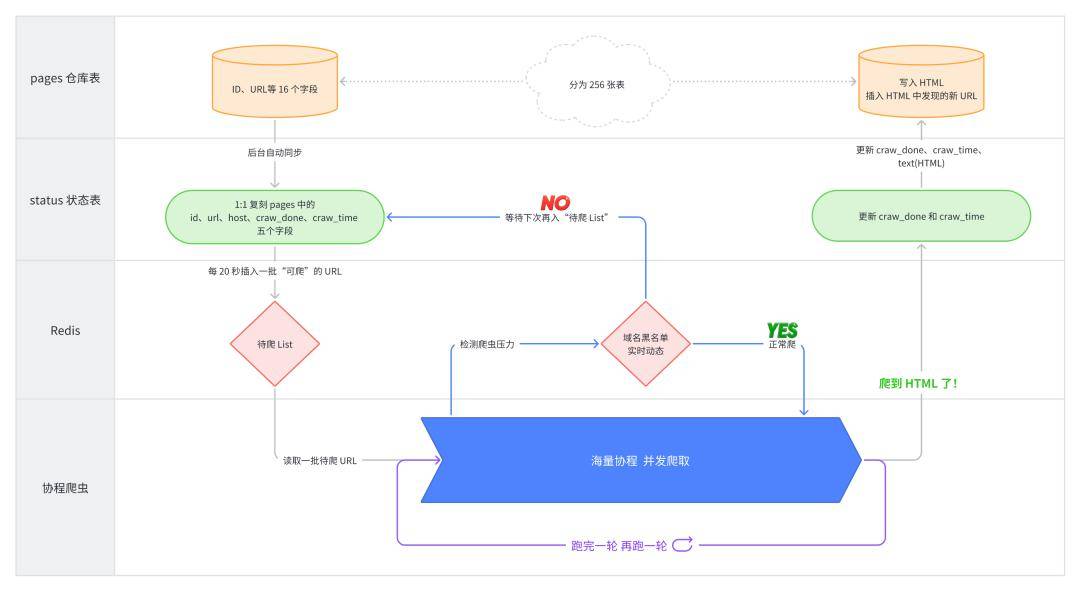
处理流程
这个版本的问题是,首先同步处理器的处理能力有限,他的处理能力比不上请求到达的速度。很快Buffered Channel就会满了,然后后续的客户请求都会被阻塞。在Marcio他们部署这个有缺陷的版本几分钟后,延迟率会以固定的速率增加。

系统部署后的延迟
Marcio引入了2层Channel,一个Channel用于缓存请求,是一个全局Channel,本文中就是下面的JobQueue,一个Channel用于控制每个请求队列并发多少个worker.从下面的代码可以看到,每个Worker都有两个关键属性,一个是WorkerPool(这个也是一个全局的变量,即所有的worker的这个属性都指向同一个,worker在创建后,会把自身的JobChannel写入WorkerPool完成注册),一个是JobChannel(用于缓存分配需要本worker处理的请求作业)。web处理请求payloadHandler,会把接收到的请求放到JobQueue后,就结束并返回。
var (
MaxWorker = os.Getenv("MAX_WORKERS")
MaxQueue = os.Getenv("MAX_QUEUE")
)
// Job represents the job to be run
type Job struct {
Payload Payload
}
// A buffered channel that we can send work requests on.
var JobQueue chan Job
// Worker represents the worker that executes the job
type Worker struct {
WorkerPool chan chan Job
JobChannel chan Job
quit chan bool
}
func NewWorker(workerPool chan chan Job) Worker {
return Worker{
WorkerPool: workerPool,
JobChannel: make(chan Job),
quit: make(chan bool)}
}
// Start method starts the run loop for the worker, listening for a quit channel in
// case we need to stop it
func (w Worker) Start() {
go func() {
for {
// register the current worker into the worker queue.
w.WorkerPool <- w.JobChannel
select {
case job := <-w.JobChannel:
// we have received a work request.
if err := job.Payload.UploadToS3(); err != nil {
log.Errorf("Error uploading to S3: %s", err.Error())
}
case <-w.quit:
// we have received a signal to stop
return
}
}
}()
}
// Stop signals the worker to stop listening for work requests.
func (w Worker) Stop() {
go func() {
w.quit <- true
}()
}
func payloadHandler(w http.ResponseWriter, r *http.Request) {
if r.Method != "POST" {
w.WriteHeader(http.StatusMethodNotAllowed)
return
}
// Read the body into a string for json decoding
var content = &PayloadCollection{}
err := json.NewDecoder(io.LimitReader(r.Body, MaxLength)).Decode(&content)
if err != nil {
w.Header().Set("Content-Type", "application/json; charset=UTF-8")
w.WriteHeader(http.StatusBadRequest)
return
}
// Go through each payload and queue items individually to be posted to S3
for _, payload := range content.Payloads {
// let's create a job with the payload
work := Job{Payload: payload}
// Push the work onto the queue.
JobQueue <- work
}
w.WriteHeader(http.StatusOK)
}
请求任务都放到JobQueue里面了,如何监听队列,并触发请求呢。这个地方又出现了Dispatcher,我们在另一篇文章中有详细探讨(基于dispatcher模式的事件与数据分发处理器的Go语言实现:
https://www.toutiao.com/article/7186518439215841827/)。在系统启动的时候,我们会通过NewDispatcher生成Dispatcher,并调用它的Run方法。
type Dispatcher struct {
// A pool of workers channels that are registered with the dispatcher
WorkerPool chan chan Job
}
func NewDispatcher(maxWorkers int) *Dispatcher {
pool := make(chan chan Job, maxWorkers)
return &Dispatcher{WorkerPool: pool}
}
func (d *Dispatcher) Run() {
// starting n number of workers
for i := 0; i < d.maxWorkers; i++ {
worker := NewWorker(d.pool)
worker.Start()
}
go d.dispatch()
}
func (d *Dispatcher) dispatch() {
for {
select {
case job := <-JobQueue:
// a job request has been received
go func(job Job) {
// try to obtAIn a worker job channel that is available.
// this will block until a worker is idle
jobChannel := <-d.WorkerPool
// dispatch the job to the worker job channel
jobChannel <- job
}(job)
}
}
}
Dispatcher与Worker的关系如下图所示:

第三方案整体流程
1.客户请求到Handler。
2.Handler把请求作业写入JobQueue。
3.Dispatcher的dispatcher方法,从全局JobQueue中读取Job。
4.Dispatcher的dispatcher方法同时也从WorkerPool中读取JobChannel(属于某一个Worker,即每一个Worker都有一个JobChannel)。
5.Dispatcher把获得的Job写入JobChannel,即分配某个Worker。
6.Worker从自己的JobChannel中获取作业并执行。执行完成后,空闲后,把自己的JobChannel再次写入WorkerPool等待分配。
这样实现后,效果明显,同时需要的机器数量大幅降低了,从100台降低到20台。

第三方案效果

部署机器变化
这里的两层,一层是全局JobQueue,缓存任务。第二个是每个Worker都有自己的执行队列,一台机器可以创建多个Worker。这样就提升了处理能力。
|
方案思想 |
实现难度 |
方案问题 |
|
GO协程原生方法 |
简单 |
无法应对大规模请求,无法控制协程数量 |
|
GO 单层Channel |
简单 |
当处理能力达不到请求速率后,队列满,系统崩溃 |
|
GO两层Channel |
复杂 |
|
参考资料:
http://marcio.io/2015/07/handling-1-million-requests-per-minute-with-golang/。
https://Github.com/ReGYChang/zero/blob/main/pkg/utils/worker_pool.go。