ES6 说自己的宗旨是“凡是新加入的特性,势必已在其它语言中得到强有力的实用性证明。”——TRUE!如果你大概浏览下 ES6 的新特性,事实上它们都不是什么新东西,而是在其他语言中已经被广泛认可和采用的,还有就是多年工程实践的结果,比如,JAVAScript 框架 jQuery、Undercore、AnjularJS、Backbone、React、Ember、Polymer、Knockout 和 Browserify、RequireJS、Webpack,以及NPM 和 Bower,涉及到 JavaScript 的库和框架、模块打包器及测试、任务调度器、包和工作流管理等方面,以前需要用这些三方框架来实现,有些现在则不用了。因为,ES6 本身就具备。所以,以后写 JS 代码,或多或少跟像 Java、C# 等这些服务器端语言有点像~
如果你嫌内容太长,可以大概浏览一下也行~你会发现服务器编程语言很多特性,现在在前端也能使用了~
JavaScript是ECMAScript的实现和扩展,由ECMA(一个类似W3C的标准组织)参与进行标准化。ECMAScript定义了:
ECMAScript标准不定义html或css的相关功能,也不定义类似DOM(文档对象模型)的Web API,这些都在其他的标准中定义。
ECMAScript涵盖了各种环境中JS的使用场景,无论是浏览器环境还是类似node.js的非浏览器环境。
2015年6月,ECMAScript语言规范第6版最终草案提请Ecma大会审查,这意味着什么呢?——我们将迎来最新的JavaScript核心语言标准。
早在2009年,上一版的ES5,自那时起,ES标准委员会一直在紧锣密鼓地筹备新的JS语言标准——ES6。
ES6是一次重大的版本升级,与此同时,由于ES6秉承着最大化兼容已有代码的设计理念,你过去编写的JS代码将继续正常运行。事实上,许多浏览器已经支持部分ES6特性,并将继续努力实现其余特性。这意味着,在一些已经实现部分特性的浏览器中,你的JS代码已经可以正常运行。如果到目前为止你尚未遇到任何兼容性问题,那么你很有可能将不会遇到这些问题,浏览器正飞速实现各种新特性。
ECMAScript标准的历史版本分别是1、2、3、5。
为什么没有版4?其实,的确曾经计划发布具有大量新特性的版4,但最终因想法太过激进而惨遭废除(这一版标准中曾经有一个极其复杂的支持泛型和类型推断的内建静态类型系统)。步子不能迈得太大~
ES4饱受争议,当标准委员会最终停止开发ES4时,其成员同意发布一个相对谦和的ES5版本,随后继续制定一些更具实质性的新特性。这一明确的协商协议最终命名为“Harmony”,因此,ES5规范中包含这样两句话:
ECMAScript是一门充满活力的语言,并在不断进化中。
未来版本的规范中将持续进行重要的技术改进。
2009年的版5,引入了Object.create()、Object.defineProperty()、getters 和 setters、严格模式以及JSON对象。我已经使用过所有这些新特性,并且非常喜欢。但这些改进并没有影响我编写JS代码的方式,对我来说,最大的革新就是新的数组方法:.map()、. filter()。
但ES6并非如此!经过持续几年的磨砺,它已成为JS有史以来最实质的升级,新的语言和库特性就像无主之宝,等待有识之士的发掘。新特性涵盖范围甚广,小到受欢迎的语法糖,例如箭头函数(arrow functions)和简单的字符串插值(string interpolation),大到烧脑的新概念,例如代理(proxies)和生成器(generators)。
ES6将彻底改变你编写JS代码的方式!
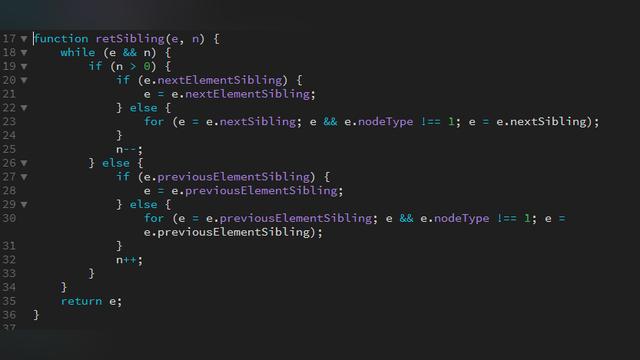
下面从一个经典的“遗漏特性”说起,十年来我一直期待在JavaScript中看到的它——ES6迭代器(iterators)和新的for-of循环!
如何遍历数组?20年前JavaScript刚萌生时,你可能这样实现数组遍历:
for (var index = 0; index < myArray.length; index++) {
console.log(myArray[index]);
}
自 ES5 正式发布后,你可以使用内建的 forEach 方法来遍历数组:
myArray.forEach(function (value) {
console.log(value);
});
这段代码看起来更简洁,但有一个小缺陷:不能使用 break 语句中断循环,也不能使用 return 语句返回到外层函数。
当然,如果只用 for 循环的语法来遍历数组元素,那么,你一定想尝试一下 for-in 循环:
for (var index in myArray) {
console.log(myArray[index]);
}
但这绝对是一个糟糕的选择,为什么呢?
目前来看,成千上万的Web网站依赖 for-in 循环,其中一些网站甚至将其用于数组遍历。如果想通过修正for-in循环增加数组遍历支持会让这一切变得更加混乱,因此,标准委员会在ES6中增加了一种新的循环语法来解决目前的问题。像下面那样:
for (var value of myArray) {
console.log(value);
}
是的,与之前的内建方法相比,这种循环方式看起来是否有些眼熟?那好,我们将要探究一下 for-of 循环的外表下隐藏着哪些强大的功能。现在,只需记住:
for-in循环用来遍历对象属性。for-of循环用来遍历数据—例如数组中的值。
但是,不仅如此!
for-of循环也可以遍历其它的集合。for-of循环不仅支持数组,还支持大多数类数组对象,例如DOM NodeList对象。for-of循环也支持字符串遍历,它将字符串视为一系列的Unicode字符来进行遍历:
for (var chr of "") {
alert(chr);
}
它同样支持遍历 Map 和 Set 对象。
对不起,你一定没听说过Map和Set对象。他们是ES6中新增的类型。我们将在后面讲解这两个新的类型。如果你曾在其它语言中使用过Map和Set,你会发现ES6中并无太大出入。
举个例子,Set 对象可以自动排除重复项:
// 基于单词数组创建一个set对象
var uniquewords = new Set(words);
生成 Set 对象后,你可以轻松遍历它所包含的内容:
for (var word of uniqueWords) {
console.log(word);
}
Map 对象稍有不同。数据由键值对组成,所以你需要使用解构(destructuring)来将键值对拆解为两个独立的变量:
for (var [key, value] of phoneBookMap) {
console.log(key + "'s phone number is: " + value);
}
解构也是ES6的新特性,我们将在后面讲解。
现在,你只需记住:未来的JS可以使用一些新型的集合类,甚至会有更多的类型陆续诞生,而for-of就是为遍历所有这些集合特别设计的循环语句。
for-of循环不支持普通对象,但如果你想迭代一个对象的属性,你可以用for-in循环(这也是它的本职工作)或内建的Object.keys()方法:
// 向控制台输出对象的可枚举属性
for (var key of Object.keys(someObject)) {
console.log(key + ": " + someObject[key]);
}
“能工摹形,巧匠窃意。”——巴勃罗·毕加索
ES6始终坚持这样的宗旨:凡是新加入的特性,势必已在其它语言中得到强有力的实用性证明。
for-of 循环这个新特性,像极了 C++、Java、C# 以及 Python 中的 foreach 循环语句。与它们一样,for-of循环支持语言和标准库中提供的几种不同的数据结构。它同样也是这门语言中的一个扩展点。
正如其它语言中的for/foreach语句一样,for-of循环语句通过方法调用来遍历各种集合。数组、Maps对象、Sets对象以及其它在我们讨论的对象有一个共同点,它们都有一个迭代器方法。
你可以给任意类型的对象添加迭代器方法。
当你为对象添加myObject.toString()方法后,就可以将对象转化为字符串,同样地,当你向任意对象添加myObject[Symbol.iterator]()方法,就可以遍历这个对象了。
举个例子,假设你正在使用jQuery,尽管你非常钟情于里面的.each()方法,但你还是想让jQuery对象也支持for-of循环,可以这样做:
// 因为jQuery对象与数组相似
// 可以为其添加与数组一致的迭代器方法
jQuery.prototype[Symbol.iterator] = Array.prototype[Symbol.iterator];
好的,我知道你在想什么,那个[Symbol.iterator]语法看起来很奇怪,这段代码到底做了什么呢?这里通过Symbol处理了一下方法的名称。标准委员会可以把这个方法命名为.iterator()方法,但是如果你的代码中的对象可能也有一些.iterator()方法,这一定会让你感到非常困惑。于是在ES6标准中使用symbol来作为方法名,而不是使用字符串。
你大概也猜到了,Symbols是ES6中的新类型,我们会在后续的文章中讲解。现在,你需要记住,基于新标准,你可以定义一个全新的 symbol,就像Symbol.iterator,如此一来可以保证不与任何已有代码产生冲突。这样做的代价是,这段代码的语法看起来会略显生硬,但是这微乎其微代价却可以为你带来如此多的新特性和新功能,并且你所做的这一切可以完美地向后兼容。
所有拥有[Symbol.iterator]()的对象被称为可迭代的。在接下来的文章中你会发现,可迭代对象的概念几乎贯穿于整门语言之中,不仅是for-of循环,还有Map和Set构造函数、解构赋值,以及新的展开操作符。
现在,你将无须亲自从零开始实现一个对象迭代器,我们会在下一篇文章详细讲解。为了帮助你理解本文,我们简单了解一下迭代器(如果你跳过这一章,你将错过非常精彩的技术细节)。
for-of循环首先调用集合的[Symbol.iterator]()方法,紧接着返回一个新的迭代器对象。迭代器对象可以是任意具有.next()方法的对象;for-of循环将重复调用这个方法,每次循环调用一次。举个例子,这段代码是我能想出来的最简单的迭代器:
var zeroesForeverIterator = {
[Symbol.iterator]: function () {
return this;
},
next: function () {
return {done: false, value: 0};
}
};
每一次调用.next()方法,它都返回相同的结果,返回给for-of循环的结果有两种可能:(a) 我们尚未完成迭代;(b) 下一个值为0。这意味着(value of zeroesForeverIterator) {}将会是一个无限循环。当然,一般来说迭代器不会如此简单。
这个迭代器的设计,以及它的.done和.value属性,从表面上看与其它语言中的迭代器不太一样。在Java中,迭代器有分离的.hasNext()和.next()方法。在Python中,他们只有一个.next() 方法,当没有更多值时抛出StopIteration异常。但是所有这三种设计从根本上讲都返回了相同的信息。
迭代器对象也可以实现可选的.return()和.throw(exc)方法。如果for-of循环过早退出会调用.return()方法,异常、 break语句或return语句均可触发过早退出。如果迭代器需要执行一些清洁或释放资源的操作,可以在.return()方法中实现。大多数迭代器方法无须实现这一方法。.throw(exc)方法的使用场景就更特殊了:for-of循环永远不会调用它。但是我们还是会在下一篇文章更详细地讲解它的作用。
现在我们已了解所有细节,可以写一个简单的for-of循环然后按照下面的方法调用重写被迭代的对象。
首先是for-of循环:
for (VAR of ITERABLE) {
// do something
}
然后是一个使用以下方法和少许临时变量实现的与之前大致相当的示例:
var $iterator = ITERABLE[Symbol.iterator]();
var $result = $iterator.next();
while (!$result.done) {
VAR = $result.value;
// do something
$result = $iterator.next();
}
这段代码没有展示.return()方法是如何处理的,我们可以添加这部分代码,但我认为这对于我们正在讲解的内容来说过于复杂了。for-of循环用起来很简单,但是其背后有着非常复杂的机制。
目前,对于for-of循环新特性,所有最新版本Firefox都(部分)支持(译注:从FF 13开始陆续支持相关功能,FF 36 - FF 40基本支持大部分特性),在Chrome中可以通过访问 chrome://flags 并启用“实验性JavaScript”来支持。微软的Spartan浏览器支持,但是IE不支持。如果你想在web环境中使用这种新语法,同时需要支持 IE和Safari,你可以使用Babel或google的Traceur这些编译器来将你的ES6代码翻译为Web友好的ES5代码。
而在服务端,你不需要类似的编译器,io.js中默认支持ES6新语法(部分),在Node中需要添加--harmony选项来启用相关特性。
{done: true}
for-of 循环的使用远没有结束。
在ES6中有一种新的对象与for-of循环配合使用非常契合,后面将讲解。我认为这种新特性是ES6种最梦幻的地方——ES6 的生成器:generators,如果你尚未在类似Python和C#的语言中遇到它,你一开始很可能会发现它令人难以置信,但是这是编写迭代器最简单的方式,在重构中非常有用,并且它很可能改变我们书写异步代码的方式,无论是在浏览器环境还是服务器环境 。
为什么说是“最具魔力的”?对于初学者来说,此特性与JS之前已有的特性截然不同,可能会觉得有点晦涩难懂。但是,从某种意义上来说,它使语言内部的常态行为变得更加强大,如果这都不算有魔力,我不知道还有什么能算。
不仅如此,此特性可以极大地简化代码,它甚至可以帮助你逃离“回调地狱”。
既然新特性如此神奇,那么就一起深入了解它的魔力吧!
我们从一个示例开始:
function* quips(name) {
yield "你好 " + name + "!";
yield "希望你能喜欢这篇介绍ES6的译文";
if (name.startsWith("X")) {
yield "你的名字 " + name + " 首字母是X,这很酷!";
}
yield "我们下次再见!";
}
这是一只会说话的猫,这段代码很可能代表着当今互联网上最重要的一类应用。(试着点击这个链接,与这只猫互动一下,如果你感到有些困惑,回到这里继续阅读)。
这段代码看起来很像一个函数,我们称之为生成器函数,它与普通函数有很多共同点,但是二者有如下区别:
这就是普通函数和生成器函数之间最大的区别,普通函数不能自暂停,生成器函数可以。
当你调用quips()生成器函数时发生了什么?
> var iter = quips("jorendorff");
[object Generator]
> iter.next()
{ value: "你好 jorendorff!", done: false }
> iter.next()
{ value: "希望你能喜欢这篇介绍ES6的译文", done: false }
> iter.next()
{ value: "我们下次再见!", done: false }
> iter.next()
{ value: undefined, done: true }
你大概已经习惯了普通函数的使用方式,当你调用它们时,它们立即开始运行,直到遇到return或抛出异常时才退出执行,作为JS程序员你一定深谙此道。
生成器调用看起来非常类似:quips("jorendorff")。但是,当你调用一个生成器时,它并非立即执行,而是返回一个已暂停的生成器对象(上述实例代码中的iter)。你可将这个生成器对象视为一次函数调用,只不过立即冻结了,它恰好在生成器函数的最顶端的第一行代码之前冻结了。
每当你调用生成器对象的.next()方法时,函数调用将其自身解冻并一直运行到下一个yield表达式,再次暂停。
这也是在上述代码中我们每次都调用iter.next()的原因,我们获得了quips()函数体中yield表达式生成的不同的字符串值。
调用最后一个iter.next()时,我们最终抵达生成器函数的末尾,所以返回结果中done的值为true。抵达函数的末尾意味着没有返回值,所以返回结果中value的值为undefined。
现在回到会说话的猫的demo页面,尝试在循环中加入一个yield,会发生什么?
如果用专业术语描述,每当生成器执行yields语句,生成器的堆栈结构(本地变量、参数、临时值、生成器内部当前的执行位置)被移出堆栈。然而,生成器对象保留了对这个堆栈结构的引用(备份),所以稍后调用.next()可以重新激活堆栈结构并且继续执行。
值得特别一提的是,生成器不是线程,在支持线程的语言中,多段代码可以同时运行,通通常导致竞态条件和非确定性,不过同时也带来不错的性能。生成器则完全不同。当生成器运行时,它和调用者处于同一线程中,拥有确定的连续执行顺序,永不并发。与系统线程不同的是,生成器只有在其函数体内标记为yield的点才会暂停。
现在,我们了解了生成器的原理,领略过生成器的运行、暂停恢复运行的不同状态。那么,这些奇怪的功能究竟有何用处?
上周,我们学习了ES6的迭代器,它是ES6中独立的内建类,同时也是语言的一个扩展点,通过实现[Symbol.iterator]()和.next()两个方法你就可以创建自定义迭代器。
实现一个接口不是一桩小事,我们一起实现一个迭代器。举个例子,我们创建一个简单的range迭代器,它可以简单地将两个数字之间的所有数相加。首先是传统C的for(;;)循环:
// 应该弹出三次 "ding"
for (var value of range(0, 3)) {
alert("Ding! at floor #" + value);
}
使用ES6的类的解决方案(如果不清楚语法细节,无须担心,我们将在接下来的文章中为你讲解):
class RangeIterator {
constructor(start, stop) {
this.value = start;
this.stop = stop;
}
[Symbol.iterator]() { return this; }
next() {
var value = this.value;
if (value < this.stop) {
this.value++;
return {done: false, value: value};
} else {
return {done: true, value: undefined};
}
}
}
// 返回一个新的迭代器,可以从start到stop计数。
function range(start, stop) {
return new RangeIterator(start, stop);
}
查看代码运行情况。
这里的实现类似Java或Swift中的迭代器,不是很糟糕,但也不是完全没有问题。我们很难说清这段代码中是否有bug,这段代码看起来完全不像我们试图模仿的传统for (;;)循环,迭代器协议迫使我们拆解掉循环部分。
此时此刻你对迭代器可能尚无感觉,他们用起来很酷,但看起来有些难以实现。
你大概不会为了使迭代器更易于构建从而建议我们为JS语言引入一个离奇古怪又野蛮的新型控制流结构,但是既然我们有生成器,是否可以在这里应用它们呢?一起尝试一下:
function* range(start, stop) {
for (var i = start; i < stop; i++)
yield i;
}
查看代码运行情况。
以上4行代码实现的生成器完全可以替代之前引入了一整个RangeIterator类的23行代码的实现。可行的原因是:生成器是迭代器。所有的生成器都有内建.next()和[Symbol.iterator]()方法的实现。你只须编写循环部分的行为。
我们都非常讨厌被迫用被动语态写一封很长的邮件,不借助生成器实现迭代器的过程与之类似,令人痛苦不堪。当你的语言不再简练,说出的话就会变得难以理解。RangeIterator的实现代码很长并且非常奇怪,因为你需要在不借助循环语法的前提下为它添加循环功能的描述。所以生成器是最好的解决方案!
我们如何发挥作为迭代器的生成器所产生的最大效力?
l 使任意对象可迭代。编写生成器函数遍历这个对象,运行时yield每一个值。然后将这个生成器函数作为这个对象的[Symbol.iterator]方法。
l 简化数组构建函数。假设你有一个函数,每次调用的时候返回一个数组结果,就像这样:
// 拆分一维数组icons
// 根据长度rowLength
function splitIntoRows(icons, rowLength) {
var rows = [];
for (var i = 0; i < icons.length; i += rowLength) {
rows.push(icons.slice(i, i + rowLength));
}
return rows;
}
使用生成器创建的代码相对较短:
function* splitIntoRows(icons, rowLength) {
for (var i = 0; i < icons.length; i += rowLength) {
yield icons.slice(i, i + rowLength);
}
}
行为上唯一的不同是,传统写法立即计算所有结果并返回一个数组类型的结果,使用生成器则返回一个迭代器,每次根据需要逐一地计算结果。
举个例子,假设你需要一个等效于Array.prototype.filter并且支持DOM NodeLists的方法,可以这样写:
function* filter(test, iterable) {
for (var item of iterable) {
if (test(item))
yield item;
}
}
你看,生成器魔力四射!借助它们的力量可以非常轻松地实现自定义迭代器,记住,迭代器贯穿ES6的始终,它是数据和循环的新标准。
以上只是生成器的冰山一角,最重要的功能请继续观看!
这是我以前写的一些JS代码:
};
})
});
});
});
});
可能你已经见过类似的代码,异步API通常需要一个回调函数,这意味着你需要为每一次任务执行编写额外的异步函数。所以如果你有一段代码需要完成三个任务,你将看到类似的三层级缩进的代码,而非简单的三行代码。
后来我就这样写了:
}).on('close', function () {
done(undefined, undefined);
}).on('error', function (error) {
done(error);
});
异步API拥有错误处理规则,不支持异常处理。不同的API有不同的规则,大多数的错误规则是默认的;在有些API里,甚至连成功提示都是默认的。
这些是到目前为止我们为异步编程所付出的代价,我们正慢慢开始接受异步代码不如等效同步代码美观又简洁的这个事实。
生成器为你提供了避免以上问题的新思路。
实验性的Q.async()尝试结合promises使用生成器产生异步代码的等效同步代码。举个例子:
// 制造一些噪音的同步代码。
function makeNoise() {
shake();
rattle();
roll();
}
// 制造一些噪音的异步代码。
// 返回一个Promise对象
// 当我们制造完噪音的时候会变为resolved
function makeNoise_async() {
return Q.async(function* () {
yield shake_async();
yield rattle_async();
yield roll_async();
});
}
二者主要的区别是,异步版必须在每次调用异步函数的地方添加yield关键字。
在Q.async版本中添加一个类似if语句的判断或try/catch块,如同向同步版本中添加类似功能一样简单。与其它异步代码编写方法相比,这种方法更自然,不像学一门新语言一样辛苦。
如果你已经看到这里,你可以试着阅读来自James Long的更深入地讲解生成器的文章。
生成器为我们提供了一个新的异步编程模型思路,这种方法更适合人类的大脑。相关工作正在不断展开。此外,更好的语法或许会有帮助,ES7中有一个有关异步函数的提案,它基于promises和生成器构建,并从C#相似的特性中汲取了大量灵感。
在服务器端,现在你可以在io.js中使用ES6(在Node中你需要使用 –harmony 这个命令行选项)。
在浏览器端,到目前为止只有Firefox 27+和Chrome 39+支持了ES6生成器。如果要在web端使用生成器,你需要使用Babel或Traceur来将你的ES6代码转译为Web友好的ES5。
起初,JS中的生成器由Brendan Eich实现,他的设计参考了Python生成器,而此Python生成器则受到Icon的启发。他们早在2006年就在Firefox 2.0中移植了相关代码。但是,标准化的道路崎岖不平,相关语法和行为都在原先的基础上有所改动。Firefox和Chrome中的ES6生成器都是由编译器hacker Andy Wingo实现的。这项工作由Bloomberg赞助支持(没听错,就是大名鼎鼎的那个彭博!)。
生成器还有更多未提及的特性,例如:.throw()和.return()方法、可选参数.next()、yield*表达式语法。由于行文过长,估计观众已然疲乏,我们应该学习一下生成器,暂时yield在这里,剩下的干货择机为大家献上。
下一次,我们变换一下风格,由于我们接连搬了两座大山:迭代器和生成器,下次就一起研究下不会改变你编程风格的ES6特性好不?就是一些简单又实用的东西,你一定会喜笑颜开哒!你还别说,在什么都要“微”一下的今天,ES6当然要有微改进了!
在第三篇文章中,我们着重讲解了生成器的基本行为。你可能对此感到陌生,但是并不难理解。生成器函数与普通函数有很多相似之处,它们之间最大的不同是,普通函数一次执行完毕,而生成器函数体每次执行一部分,每当执行到一个yield表达式的时候就会暂停。
尽管在那篇文章中我们进行过详细解释,但我们始终未把所有特性结合起来给大家讲解示例。现在就让我们出发吧!
function* somewords() {
yield "hello";
yield "world";
}
for (var word of somewords()) {
alert(word);
}
这段脚本简单易懂,但是如果你把代码中不同的比特位当做戏剧中的任务,你会发现它变得如此与众不同。穿上新衣的代码看起来是这样的:
(译者注:下面这是原作者创作的一个剧本,他将ES6中的各种函数和语法拟人化,以讲解生成器(Generator)的实现原理)
for loop女士独自站在舞台上,戴着一顶安全帽,手里拿着一个笔记板,上面记载着所有的事情。
for loop:
(电话响起)
somewords()!
generator出现:这是一位高大的、有着一丝不苟绅士外表的黄铜机器人。
它看起来足够友善,但给人的感觉仍然是冷冰冰的金属。
for loop:
(潇洒地拍了拍她的手)
好吧!我们去找些事儿做吧。
(对generator说)
.next()!
generator动了起来,就像突然拥有了生命。
generator:
{value: "hello", done: false}
然而猝不及防的,它以一个滑稽的姿势停止了动作。
for loop:
alert!
alert小子飞快冲进舞台,眼睛大睁,上气不接下气。我们感觉的到他一向如此。
for loop:
对user说“hello”。
alert小子转身冲下舞台。
alert:
(舞台下,大声尖叫)
一切都静止了!
你正在访问的页面说,
“hello”!
停留了几秒钟后,alert小子跑回舞台,穿过所有人滑停在for loop女士身边。
alert:
user说ok。
for loop:
(潇洒地拍了拍她的手)
好吧!我们去找些事儿做吧。
(回到generator身边)
.next()!
generator又一次焕发生机。
generator:
{value: "world", done: false}
它换了个姿势又一次冻结。
for loop:
alert!
alert:
(已经跑起来)
正在搞定!
(舞台下,大声尖叫)
一切都静止了!
你正在访问的页面说,
“world”!
又一次暂停,然后alert突然跋涉回到舞台,垂头丧气的。
alert:
user再一次说ok,但是…
但是请阻止这个页面
创建额外的对话。
他噘着嘴离开了。
for loop:
(潇洒地拍了拍她的手)
好吧!我们去找些事儿做吧。
(回到generator身边)
.next()!
generator第三次焕发生机。
generator:
(庄严的)
{value: undefined, done: true}
它的头低下了,光芒从它的眼里消失。它不再移动。
for loop
我的午餐时间到了。
她离开了。
一会儿,garbage collector(垃圾收集器)老头进入,捡起了奄奄一息的generator,将它带下舞台。
好吧,这一出戏不太像哈姆雷特,但你应该可以想象得出来。
正如你在戏剧中看到的,当生成器对象第一次出现时,它立即暂停了。每当调用它的.next()方法,它都会苏醒并向前执行一部分。
所有动作都是单线程同步的。请注意,无论何时永远只有一个真正活动的角色,角色们不会互相打断,亦不会互相讨论,他们轮流讲话,只要他们的话没有说完都可以继续说下去。(就像莎士比亚一样!)
每当for-of循环遍历生成器时,这出戏的某个版本就展开了。这些.next()方法调用序列永远不会在你的代码的任何角落出现,在剧本里我把它们都放在舞台上了,但是对于你和你的程序而言,所有这一切都应该在幕后完成,因为生成器和for-of循环就是被设计成通过迭代器接口联结工作的。
所以,总结一下到目前为止所有的一切:
我在第1部分没有提到这些繁琐的生成器特性:
如果你不理解这些特性存在得意义,就很难对它们提起兴趣,更不用说理解它们的实现细节,所以我选择直接跳过。但是当我们深入学习生成器时,势必要仔细了解这些特性的方方面面。
你或许曾使用过这样的模式:
function dothings() {
setup();
try {
// ... 做一些事情
} finally {
cleanup();
}
}
dothings();
清理(cleanup)过程包括关闭连接或文件,释放系统资源,或者只是更新dom来关闭“运行中”的加载动画。我们希望无论任务成功完成与否都触发清理操作,所以执行流入到finally代码块。
那么生成器中的清理操作看起来是什么样的呢?
function* producevalues() {
setup();
try {
// ... 生成一些值
} finally {
cleanup();
}
}
for (var value of producevalues()) {
work(value);
}
这段代码看起来很好,但是这里有一个问题:我们没在try代码块中调用work(value),如果它抛出异常,我们的清理步骤会如何执行呢?
或者假设for-of循环包含一条break语句或return语句。清理步骤又会如何执行呢?
放心,清理步骤无论如何都会执行,ES6已经为你做好了一切。
我们第一次讨论迭代器和for-of循环时曾说过,迭代器接口支持一个可选的.return()方法,每当迭代在迭代器返回{done:true}之前退出都会自动调用这个方法。生成器支持这个方法,mygenerator.return()会触发生成器执行任一finally代码块然后退出,就好像当前的生成暂停点已经被秘密转换为一条return语句一样。
注意,.return()方法并不是在所有的上下文中都会被自动调用,只有当使用了迭代协议的情况下才会触发该机制。所以也有可能生成器没执行finally代码块就直接被垃圾回收了。
如何在舞台上模拟这些特性?生成器被冻结在一个需要一些配置的任务(例如,建造一幢摩天大楼)中间。突然有人抛出一个错误!for循环捕捉到这个错误并将它放置在一遍,她告诉生成器执行.return()方法。生成器冷静地拆除了所有脚手架并停工。然后for循环取回错误,继续执行正常的异常处理过程。
到目前为止,我们在剧本中看到的生成器(generator)和使用者(user)之间的对话非常有限,现在换一种方式继续解释:
在这里使用者主导一切流程,生成器根据需要完成它的任务,但这不是使用生成器进行编程的唯一方式。
在第1部分中我曾经说过,生成器可以用来实现异步编程,完成你用异步回调或promise链所做的一切。我知道你一定想知道它是如何实现的,为什么yield的能力(这可是生成器专属的特殊能力)足够应对这些任务。毕竟,异步代码不仅产生(yield)数据,还会触发事件,比如从文件或数据库中调用数据,向服务器发起请求并返回事件循环来等待异步过程结束。生成器如何实现这一切?它又是如何不借助回调力量从文件、数据库或服务器中接受数据?
为了开始找出答案,考虑一下如果.next()的调用者只有一种方法可以传值返回给生成器会发生什么?仅仅是这一点改变,我们就可能创造一种全新的会话形式:
事实上,生成器的.next()方法接受一个可选参数,参数稍后会作为yield表达式的返回值出现在生成器中。那就是说,yield语句与return语句不同,它是一个只有当生成器恢复时才会有值的表达式。
var results = yield getdataandlatte(request.areacode);
这一行代码完成了许多功能:
下面这段代码完整地展示了这一行代码完整的上下文会话:
function* handle(request) {
var results = yield getdataandlatte(request.areacode);
results.coffee.drink();
var target = mosturgentrecord(results.data);
yield updatestatus(target.id, "ready");
}
yield仍然保持着它的原始含义:暂停生成器,返回值给调用者。但是确实也发生了变化!这里的生成器期待来自调用者的非常具体的支持行为,就好像调用者是它的行政助理一样。
普通函数则与之不同,通常更倾向于满足调用者的需求。但是你可以借助生成器创造一段对话,拓展生成器与其调用者之间可能存在的关系。
这个行政助理生成器运行器可能是什么样的?它大可不必很复杂,就像这样:
function rungeneratoronce(g, result) {
var status = g.next(result);
if (status.done) {
return; // phew!
}
// 生成器请我们去获取一些东西并且
// 当我们搞定的时候再回调它
doasynchronousworkincludingespressomachineoperations(
status.value,
(error, nextresult) => rungeneratoronce(g, nextresult));
}
为了让这段代码运行起来,我们必须创建一个生成器并且运行一次,像这样:
rungeneratoronce(handle(request), undefined);
在之前的文章中,我一个库的示例中提到Q.async(),在那个库中,生成器是可以根据需要自动运行的异步过程。rungeneratoronce正式这样的一个具体实现。事实上,生成器一般会生成Promise对象来告诉调用者要做的事情,而不是生成字符串来大声告诉他们。
如果你已经理解了Promise的概念,现在又理解了生成器的概念,你可以尝试修改rungeneratoronce的代码来支持Promise。这个任务不简单,但是一旦成功,你将能够用Promise线性书写复杂的异步算法,而不仅仅通过.then()方法或回调函数来实现异步功能。
你是否有看到rungeneratoronce的错误处理过程?答案一定是没有,因为上面的示例中直接忽略了错误!
是的,那样做不好,但是如果我们想要以某种方法给生成器报告错误,可以尝试一下这个方法:当有错误产生时,不要继续调用generator.next(result)方法,而应该调用generator.throw(error)方法来抛出yield表达式,进而像.return()方法一样终止生成器的执行。但是如果当前的生成暂停点在一个try代码块中,那么会catch到错误并执行finally代码块,生成器就恢复执行了。
另一项艰巨的任务来啦,你需要修改rungeneratoronce来确保.throw()方法能够被恰当地调用。请记住,生成器内部抛出的异常总是会传播到调用者。所以无论生成器是否捕获错误,generator.throw(error)都会抛出error并立即返回给你。
当生成器执行到一个yield表达式并暂停后可以实现以下功能:
看起来生成器函数与普通函数的复杂度相当,只有.return()方法显得不太一样。
事实上,yield与函数调用有许多共通的地方。当你调用一个函数,你就暂时停止了,对不对?你调用的函数取得主导权,它可能返回值,可能抛出错误,或者永远循环下去。
我再展示一个特性。假设我们写一个简单的生成器函数联结两个可迭代对象:
function* concat(iter1, iter2) {
for (var value of iter1) {
yield value;
}
for (var value of iter2) {
yield value;
}
}
es6支持这样的简写方式:
function* concat(iter1, iter2) {
yield* iter1;
yield* iter2;
}
普通yield表达式只生成一个值,而yield*表达式可以通过迭代器进行迭代生成所有的值。
这个语法也可以用来解决另一个有趣的问题:在生成器中调用生成器。在普通函数中,我们可以从将一个函数重构为另一个函数并保留所有行为。很显然我们也想重构生成器,但我们需要一种调用提取出来的子例程的方法,我们还需要确保,子例程能够生成之前生成的每一个值。yield*可以帮助我们实现这一目标。
function* factoredoutchunkofcode() { ... }
function* refactoredfunction() {
...
yield* factoredoutchunkofcode();
...
}
考虑一下这样一个场景:一个黄铜机器人将子任务委托给另一个机器人,函数对组织同步代码来说至关重要,所以这种思想可以使基于生成器特性的大型项目保持简洁有序。
ES6引入了一种新型的字符串字面量语法,我们称之为模板字符串(template strings)。除了使用反撇号字符 ` 代替普通字符串的引号 ' 或 " 外,它们看起来与普通字符串并无二致。在最简单的情况下,它们与普通字符串的表现一致:
context.fillText(`Ceci n'est pas une chaîne.`, x, y);
但我们不能说:“原来只是被反撇号括起来的普通字符串啊”。模板字符串为JavaScript提供了简单的字符串插值功能,从此以后,你可以通过一种更加美观、更加方便的方式向字符串中插值了。这在 Java 和 C# 中早已经有了,不用再用 + 符号连接字符串,用起来很方便~
模板字符串的使用方式成千上万,但最让我暖心的是将其应用于毫不起眼的错误消息提示:
function authorize(user, action) {
if (!user.hasPrivilege(action)) {
throw new Error(
`用户 ${user.name} 未被授权执行 ${action} 操作。`);
}
}
在这个示例中,${user.name} 和 ${action} 被称为模板占位符,JavaScript将把user.name和action的值插入到最终生成的字符串中,例如:用户jorendorff未被授权打冰球。(这是真的,我还没有获得冰球许可证。)
到目前为止,我们所了解到的仅仅是比 + 运算符更优雅的语法,下面是你可能期待的一些特性细节:
与普通字符串不同的是,模板字符串可以多行书写:
$("#warning").html(`
<h1>小心!>/h1>
<p>未经授权打冰球可能受罚
将近${maxPenalty}分钟。</p>
`);
模板字符串中所有的空格、新行、缩进,都会原样输出在生成的字符串中。
好啦,我说过要让你们轻松掌握模板字符串,从现在起难度会加大,你可以到此为止,去喝一杯咖啡,慢慢消化之前的知识。真的,及时回头不是一件令人感到羞愧的事情。Lopes Gonçalves曾经向我们证明过,船只不会被海妖碾压,也不会从地球的边缘坠落下去,他最终跨越了赤道,但是他有继续探索整个南半球么?并没有,他回家了,吃了一顿丰盛的午餐,你一定不排斥这样的感觉。
当然,模板字符串也并非事事包揽:
模板字符串没有内建循环语法,所以你无法通过遍历数组来构建类似HTML中的表格,甚至它连条件语句都不支持。你当然可以使用模板套构(template inception)的方法实现,但在我看来这方法略显愚钝啊。
不过,ES6为JS开发者和库设计者提供了一个很好的衍生工具,你可以借助这一特性突破模板字符串的诸多限制,我们称之为标签模板(tagged templates)。
标签模板的语法非常简单,在模板字符串开始的反撇号前附加一个额外的标签即可。我们的第一个示例将添加一个SaferHTML标签,我们要用这个标签来解决上述的第一个限制:自动转义特殊字符。
请注意,ES6标准库不提供类似SaferHTML功能,我们将在下面自己来实现这个功能。
var message =
SaferHTML`<p>${bonk.sender} 向你示好。</p>`;
这里用到的标签是一个标识符SaferHTML;也可以使用属性值作为标签,例如:SaferHTML.escape;还可以是一个方法调用,例如:SaferHTML.escape({unicodeControlCharacters: false})。精确地说,任何ES6的成员表达式(MemberExpression)或调用表达式(CallExpression)都可作为标签使用。
可以看出,无标签模板字符串简化了简单字符串拼接,标签模板则完全简化了函数调用!
上面的代码等效于:
var message =
SaferHTML(templateData, bonk.sender);
templateData是一个不可变数组,存储着模板所有的字符串部分,由JS引擎为我们创建。因为占位符将标签模板分割为两个字符串的部分,所以这个数组内含两个元素,形如Object.freeze(["<p>", " has sent you a bonk.</p>"]。
(事实上,templateData中还有一个属性,在这篇文章中我们不会用到,但是它是标签模板不可分割的一环:templateData.raw,它同样是一个数组,存储着标签模板中所有的字符串部分,如果我们查看源码将会发现,在这里是使用形如n的转义序列分行,而在templateData中则为真正的新行,标准标签String.raw会用到这些原生字符串。)
如此一来,SaferHTML函数就可以有成千上万种方法来解析字符串和占位符。
在继续阅读以前,可能你苦苦思索到底用SaferHTML来做什么,然后着手尝试去实现它,归根结底,它只是一个函数,你可以在Firefox的开发者控制台里测试你的成果。
以下是一种可行的方案(在gist中查看):
function SaferHTML(templateData) {
var s = templateData[0];
for (var i = 1; i < arguments.length; i++) {
var arg = String(arguments[i]);
// 转义占位符中的特殊字符。
s += arg.replace(/&/g, "&")
.replace(/</g, "<")
.replace(/</g, ">");
// 不转义模板中的特殊字符。
s += templateData[i];
}
return s;
}
通过这样的定义,标签模板SaferHTML`<p>${bonk.sender} 向你示好。</p>` 可能扩展为字符串 "<p>ES6<3er 向你示好。</p>"。即使一个恶意命名的用户,例如“黑客Steve<script>alert('xss');< /script>”,向其他用户发送一条骚扰信息,无论如何这条信息都会被转义为普通字符串,其他用户不会受到潜在攻击的威胁。
(顺便一提,如果你感觉上述代码中在函数内部使用参数对象的方式令你感到枯燥乏味,不妨期待下一篇,ES6中的另一个新特性一定会让你眼前一亮!)
仅一个简单的示例不足以说明标签模板的灵活性,我们一起回顾下我们之前有关模板字符串限制的列表,看一下你还能做些什么不一样的事情。
事实上,你可以做的比那更好。
站在安全角度来说,我实现的SaferHTML函数相当脆弱,你需要通过多种不同的方式将HTML不同部分的特殊字符转义,SaferHTML就无法做到全部转义。但是稍加努力,你就可以写出一个更加智能的SaferHTML函数,它可以针对templateData中字符串中的HTML位进行解析,分析出哪一个占位符是纯HTML;哪一个是元素内部属性,需要转义'和";哪一个是URL的query字符串,需要进行URL转义而非HTML转义,等等。智能SaferHTML函数可以将每个占位符都正确转义。
HTML的解析速度很慢,这种方法听起来是否略显牵强?幸运的是,当模板重新求值的时候标签模板的字符串部分是不改变的。SaferHTML可以缓存所有的解析结果,来加速后续的调用。(缓存可以按照ES6的另一个特性——WeakMap的形式进行存储,我们将在未来的文章中继续深入讨论。)
i18n`Hello ${name}, you have ${amount}:c(CAD) in your bank account.`
// => Hallo Bob, Sie haben 1.234,56 $CA auf Ihrem Bankkonto.
注意观察这个示例中的运行细节,name和amount都是JavaScript,进行正常插值处理,但是有一段与众不同的代码,:c(CAD),Jack将它放入了模板的字符串部分。JavaScript理应由JavaScript引擎进行处理,字符串部分由Jack的 i18n标签进行处理。使用者可以通过i18n的文档了解到,:c(CAD)代表加拿大元的货币单位。
这就是标签模板的大部分实际应用了。
// 基于纯粹虚构的模板语言
// ES6标签模板。
var libraryHtml = hashTemplate`
<ul>
#for book in ${myBooks}
<li><i>#{book.title}</i> by #{book.author}</li>
#end
</ul>
`;
标签模板带来的灵活性远不止于此,要记住,标签函数的参数不会自动转换为字符串,它们如返回值一样,可以是任何值,标签模板甚至不一定要是字符串!你可以用自定义的标签来创建正则表达式、DOM树、图片、以promises为代表的整个异步过程、JS数据结构、GL着色器……
标签模板以开放的姿态欢迎库设计者们来创建强有力的领域特定语言。这些语言可能看起来不像JS,但是它们仍可以无缝嵌入到JS中并与JS的其它语言特性智能交互。我不知道这一特性将会带领我们走向何方,但它蕴藏着无限的可能性,这令我感到异常兴奋!
在服务器端,io.js支持ES6的模板字符串。
在浏览器端,Firefox 34+支持模板字符串。它们由去年夏天的实习生项目组里的Guptha Rajagopal实现。模板字符串同样在Chrome 41+中得以支持,但是IE和Safari都不支持。到目前为止,如果你想要在web端使用模板字符串的功能,你将需要Babel或Traceur协助你完成ES6到ES5的代码转译,你也可以在TypeScript中立即使用这一特性。
嗯?
哦…这是个好问题。
(这一章节与JavaScript无关,如果你不使用Markdown,可以跳过这一章。)
对于模板字符串而言,Markdown和JavaScript现在都使用`字符来表示一些特殊的事物。事实上,在Markdown中,反撇号用来分割在内联文本中间的代码片段。
这会带来许多问题!如果你在Markdown中写这样的文档:
To display a message, write `alert(`hello world!`)`.
它将这样显示:
To display a message, write alert(hello world!).
请注意,输出文本中的反撇号消失了。Markdown将所有的四个反撇号解释为代码分隔符并用HTML标签将其替换掉。
为了避免这样的情况发生,我们要借助Markdown中的一个鲜为人知的特性,你可以使用多行反撇号作为代码分隔符,就像这样:
To display a message, write ``alert(`hello world!`)``.
在这个Gist有具体代码细节,它由Markdown写成,所以你可以直接查看源代码。
我们通常使用可变参函数来构造API,可变参函数可接受任意数量的参数。例如,String.prototype.concat方法就可以接受任意数量的字符串参数。ES6提供了一种编写可变参函数的新方式——不定参数。
我们通过一个简单的可变参数函数containsAll给大家演示不定参数的用法。函数containsAll可以检查一个字符串中是否包含若干个子串,例如:containsAll("banana", "b", "nan")返回true,containsAll("banana", "c", "nan")返回false。
首先使用传统方法来实现这个函数:
function containsAll(haystack) {
for (var i = 1; i < arguments.length; i++) {
var needle = arguments[i];
if (haystack.indexOf(needle) === -1) {
return false;
}
}
return true;
}
在这个实现中,我们用到了神奇的arguments对象,它是一个类数组对象,其中包含了传递给函数的所有参数。这段代码实现了我们的需求,但它的可读性却不是最理想的。函数的参数列表中只有一个参数 haystack,我们无法一眼就看出这个函数实际上接受了多个参数。另外,我们一定要注意,应该从1开始迭代,而不是从0开始,因为 arguments[0]相当于参数haystack。如果我们想要在haystack前后添加另一个参数,我们一定要记得更新循环体。不定参数恰好可以解决可读性与参数索引的问题。下面是用ES6不定参数特性实现的containsAll函数:
function containsAll(haystack, ...needles) {
for (var needle of needles) {
if (haystack.indexOf(needle) === -1) {
return false;
}
}
return true;
}
这一版containsAll函数与前者有相同的行为,但这一版中使用了一个特殊的...needles语法。我们来看一下调用 containsAll("banana", "b", "nan")之后的函数调用过程,与之前一样,传递进来的第一个参数"banana"赋值给参数haystack,needles前的省略号表明它是一个不定参数,所有传递进来的其它参数都被放到一个数组中,赋值给变量needles。对于我们的调用示例而言,needles被赋值为["b", "nan"],后续的函数执行过程一如往常。(注意啦,我们已经使用过ES6中for-of循环。)
在所有函数参数中,只有最后一个才可以被标记为不定参数。函数被调用时,不定参数前的所有参数都正常填充,任何“额外的”参数都被放进一个数组中并赋值给不定参数。如果没有额外的参数,不定参数就是一个空数组,它永远不会是undefined。
通常来说,函数调用者不需要传递所有可能存在的参数,没有被传递的参数可由感知到的默认参数进行填充。JavaScript有严格的默认参数格式,未被传值的参数默认为undefined。ES6引入了一种新方式,可以指定任意参数的默认值。
下面是一个简单的示例(反撇号表示模板字符串,上周已经讨论过。):
function animalSentence(animals2="tigers", animals3="bears") {
return `Lions and ${animals2} and ${animals3}! Oh my!`;
}
默认参数的定义形式为[param1[ = defaultValue1 ][, ..., paramN[ = defaultValueN ]]],对于每个参数而言,定义默认值时=后的部分是一个表达式,如果调用者没有传递相应参数,将使用该表达式的值作为参数默认值。相关示例如下:
animalSentence(); // Lions and tigers and bears! Oh my!
animalSentence("elephants"); // Lions and elephants and bears! Oh my!
animalSentence("elephants", "whales"); // Lions and elephants and whales! Oh my!
默认参数有几个微妙的细节需要注意:
function animalSentenceFancy(animals2="tigers",
animals3=(animals2 == "bears") ? "sealions" : "bears")
{
return `Lions and ${animals2} and ${animals3}! Oh my!`;
}
现在,animalSentenceFancy("bears")将返回“Lions and bears and sealions. Oh my!”。
function myFunc(a=42, b) {...}
是合法的,并且等效于
function myFunc(a=42, b=undefined) {...}
现在我们已经看到了arguments对象可被不定参数和默认参数完美代替,移除arguments后通常会使代码更易于阅读。除了破坏可读性外,众所周知,针对arguments对象对JavaScript虚拟机进行的优化会导致一些让你头疼不已的问题。
我们期待着不定参数和默认参数可以完全取代arguments,要实现这个目标,标准中增加了相应的限制:在使用不定参数或默认参数的函数中禁止使用arguments对象。曾经实现过arguments的引擎不会立即移除对它的支持,当然,现在更推荐使用不定参数和默认参数。
Firefox早在第15版的时候就支持了不定参数和默认参数。
不幸的是,尚未有其它已发布的浏览器支持不定参数和默认参数。V8引擎最近增添了针对不定参数的实验性的支持,并且有一个开放状态的V8 issue给实现默认参数使用,JSC同样也有一个开放的issue来给不定参数和默认参数使用。
Babel和Traceur编译器都支持默认参数,所以从现在起就可以开始使用。
解构赋值允许你使用类似数组或对象字面量的语法将数组和对象的属性赋给各种变量。这种赋值语法极度简洁,同时还比传统的属性访问方法更为清晰。
通常来说,你很可能这样访问数组中的前三个元素:
var first = someArray[0];
var second = someArray[1];
var third = someArray[2];
如果使用解构赋值的特性,将会使等效的代码变得更加简洁并且可读性更高:
var [first, second, third] = someArray;
SpiderMonkey(Firefox的JavaScript引擎)已经支持解构的大部分功能,但是仍不健全。你可以通过bug 694100跟踪解构和其它ES6特性在SpiderMonkey中的支持情况。
以上是数组解构赋值的一个简单示例,其语法的一般形式为:
[ variable1, variable2, ..., variableN ] = array;
这将为variable1到variableN的变量赋予数组中相应元素项的值。如果你想在赋值的同时声明变量,可在赋值语句前加入var、let或const关键字,例如:
var [ variable1, variable2, ..., variableN ] = array;
let [ variable1, variable2, ..., variableN ] = array;
const [ variable1, variable2, ..., variableN ] = array;
事实上,用变量来描述并不恰当,因为你可以对任意深度的嵌套数组进行解构:
var [foo, [[bar], baz]] = [1, [[2], 3]];
console.log(foo);
// 1
console.log(bar);
// 2
console.log(baz);
// 3
此外,你可以在对应位留空来跳过被解构数组中的某些元素:
var [,,third] = ["foo", "bar", "baz"];
console.log(third);
// "baz"
而且你还可以通过“不定参数”模式捕获数组中的所有尾随元素:
var [head, ...tail] = [1, 2, 3, 4];
console.log(tail);
// [2, 3, 4]
当访问空数组或越界访问数组时,对其解构与对其索引的行为一致,最终得到的结果都是:undefined。
console.log([][0]);
// undefined
var [missing] = [];
console.log(missing);
// undefined
请注意,数组解构赋值的模式同样适用于任意迭代器:
function* fibs() {
var a = 0;
var b = 1;
while (true) {
yield a;
[a, b] = [b, a + b];
}
}
var [first, second, third, fourth, fifth, sixth] = fibs();
console.log(sixth);
// 5
通过解构对象,你可以把它的每个属性与不同的变量绑定,首先指定被绑定的属性,然后紧跟一个要解构的变量。
var robotA = { name: "Bender" };
var robotB = { name: "Flexo" };
var { name: nameA } = robotA;
var { name: nameB } = robotB;
console.log(nameA);
// "Bender"
console.log(nameB);
// "Flexo"
当属性名与变量名一致时,可以通过一种实用的句法简写:
var { foo, bar } = { foo: "lorem", bar: "ipsum" };
console.log(foo);
// "lorem"
console.log(bar);
// "ipsum"
与数组解构一样,你可以随意嵌套并进一步组合对象解构:
var complicatedObj = {
arrayProp: [
"ZApp",
{ second: "Brannigan" }
]
};
var { arrayProp: [first, { second }] } = complicatedObj;
console.log(first);
// "Zapp"
console.log(second);
// "Brannigan"
当你解构一个未定义的属性时,得到的值为undefined:
var { missing } = {};
console.log(missing);
// undefined
请注意,当你解构对象并赋值给变量时,如果你已经声明或不打算声明这些变量(亦即赋值语句前没有let、const或var关键字),你应该注意这样一个潜在的语法错误:
{ blowUp } = { blowUp: 10 };
// Syntax error 语法错误
为什么会出错?这是因为JavaScript语法通知解析引擎将任何以{开始的语句解析为一个块语句(例如,{console}是一个合法块语句)。解决方案是将整个表达式用一对小括号包裹:
({ safe } = {});
// No errors 没有语法错误
当你尝试解构null或undefined时,你会得到一个类型错误:
var {blowUp} = null;
// TypeError: null has no properties(null没有属性)
然而,你可以解构其它原始类型,例如:布尔值、数值、字符串,但是你将得到undefined:
var {wtf} = NaN;
console.log(wtf);
// undefined
你可能对此感到意外,但经过进一步审查你就会发现,原因其实非常简单。当使用对象赋值模式时,被解构的值需要被强制转换为对象。大多数类型都可以被转换为对象,但null和undefined却无法进行转换。当使用数组赋值模式时,被解构的值一定要包含一个迭代器。
当你要解构的属性未定义时你可以提供一个默认值:
var [missing = true] = [];
console.log(missing);
// true
var { message: msg = "Something went wrong" } = {};
console.log(msg);
// "Something went wrong"
var { x = 3 } = {};
console.log(x);
// 3
(译者按:Firefox目前只实现了这个特性的前两种情况,第三种尚未实现。详情查看bug 932080。)
作 为开发者,我们需要实现设计良好的API,通常的做法是为函数为函数设计一个对象作为参数,然后将不同的实际参数作为对象属性,以避免让API使用者记住 多个参数的使用顺序。我们可以使用解构特性来避免这种问题,当我们想要引用它的其中一个属性时,大可不必反复使用这种单一参数对象。
function removeBreakpoint({ url, line, column }) {
// ...
}
这是一段来自Firefox开发工具JavaScript调试器(同样使用JavaScript实现——没错,就是这样!)的代码片段,它看起来非常简洁,我们会发现这种代码模式特别讨喜。
延伸一下之前的示例,我们同样可以给需要解构的对象属性赋予默认值。当我们构造一个提供配置的对象,并且需要这个对象的属性携带默认值时,解构特性就派上用场了。举个例子,jQuery的ajax函数使用一个配置对象作为它的第二参数,我们可以这样重写函数定义:
jQuery.ajax = function (url, {
async = true,
beforeSend = noop,
cache = true,
complete = noop,
crossDomain = false,
global = true,
// ... 更多配置
}) {
// ... do stuff
};
如此一来,我们可以避免对配置对象的每个属性都重复var foo = config.foo || theDefaultFoo;这样的操作。
(编者按:不幸的是,对象的默认值简写语法仍未在Firefox中实现,我知道,上一个编者按后的几个段落讲解的就是这个特性。点击bug 932080查看最新详情。)
ECMAScript 6中定义了一个迭代器协议,我们在《深入浅出ES6(二):迭代器和for-of循环》中已经详细解析过。当你迭代Maps(ES6标准库中新加入的一种对象)后,你可以得到一系列形如[key, value]的键值对,我们可将这些键值对解构,更轻松地访问键和值:
var map = new Map();
map.set(window, "the global");
map.set(document, "the document");
for (var [key, value] of map) {
console.log(key + " is " + value);
}
// "[object Window] is the global"
// "[object HTMLDocument] is the document"
只遍历键:
for (var [key] of map) {
// ...
}
或只遍历值:
for (var [,value] of map) {
// ...
}
JavaScript语言中尚未整合多重返回值的特性,但是无须多此一举,因为你自己就可以返回一个数组并将结果解构:
function returnMultipleValues() {
return [1, 2];
}
var [foo, bar] = returnMultipleValues();
或者,你可以用一个对象作为容器并为返回值命名:
function returnMultipleValues() {
return {
foo: 1,
bar: 2
};
}
var { foo, bar } = returnMultipleValues();
这两个模式都比额外保存一个临时变量要好得多。
function returnMultipleValues() {
return {
foo: 1,
bar: 2
};
}
var temp = returnMultipleValues();
var foo = temp.foo;
var bar = temp.bar;
或者使用CPS变换:
function returnMultipleValues(k) {
k(1, 2);
}
returnMultipleValues((foo, bar) => ...);
你是否尚未使用ES6模块?还用着CommonJS的模块呢吧!没问题,当我们导入CommonJS模块X时,很可能在模块X中导出了许多你根本没打算用的函数。通过解构,你可以显式定义模块的一部分来拆分使用,同时还不会污染你的命名空间:
const { SourceMapConsumer, SourceNode } = require("source-map");
(如果你使用ES6模块,你一定知道在import声明中有一个相似的语法。)
正如你所见,解构在许多独立小场景中非常实用。在Mozilla我们已经积累了许多有关解构的使用经验。十年前,Lars Hansen在Opera中引入了JS解构特性,Brendan Eich随后就给Firefox也增加了相应的支持,移植时版本为Firefox 2。所以我们可以肯定,渐渐地,你会在每天使用的语言中加入解构这个新特性,它可以让你的代码变得更加精简整洁。
箭头符号在JavaScript诞生时就已经存在,当初第一个JavaScript教程曾建议在HTML注释内包裹行内脚本,这样可以避免不支持JS的浏览器误将JS代码显示为文本。你会写这样的代码:
<script language="javascript">
<!--
document.bgColor = "brown"; // red
// -->
</script>
老式浏览器会将这段代码解析为两个不支持的标签和一条注释,只有新式浏览器才能识别出其中的JS代码。
为了支持这种奇怪的hack方式,浏览器中的JavaScript引擎将<!-- 这四个字符解析为单行注释的起始部分,我没开玩笑,这自始至终就是语言的一部分,直到现在仍然有效,这种注释符号不仅出现<script>标签后的首行,在JS代码的每个角落你都有可能见到它,甚至在Node中也是如此。
碰巧,这种注释风格首次在ES6中被标准化了,但在新标准中箭头被用来做其它事情。
箭头序列 –—> 同样是单行注释的一部分。古怪的是,在HTML中-->之前的字符是注释的一部分,而在JS中-->之后的部分才是注释。
你一定感到陌生的是,只有当箭头在行首时才会注释当前行。这是因为在其它上下文中,-->是一个JS运算符:“趋向于”运算符!
function countdown(n) {
while (n --> 0) // "n goes to zero"
alert(n);
blastoff();
}
上面这段代码可以正常运行,循环会一直重复直到n趋于0,这当然不是ES6中的新特性,它只不过是将两个你早已熟悉的特性通过一些误导性的手段结合在一起。你能理解么?通常来说,类似这种谜团都可以在Stack Overflow上找到答案。
当然,同样地,小于等于操作符<=也形似箭头,你可以在JS代码、隐藏的图片样式中找到更多类似的箭头,但是我们就不继续寻找了,你应该注意到我们漏掉了一种特殊的箭头。
<!--
单行注释
-->
“趋向于”操作符
<=
小于等于
=>
这又是什么?
=>到底是什么?我们今天就来一探究竟。
首先,我们谈论一些有关函数的事情。
JavaScript中有一个有趣的特性,无论何时,当你需要一个函数时,你都可以在想添加的地方输入这个函数。
举个例子,假设你尝试告诉浏览器用户点击一个特定按钮后的行为,你会这样写:
$("#confetti-btn").click(
jQuery的.click()方法接受一个参数:一个函数。没问题,你可以在这里输入一个函数:
$("#confetti-btn").click(function (event) {
playTrumpet();
fireConfettiCannon();
});
对于现在的我们来说,写出这样的代码相当自然,而回忆起在这种编程方式流行之前,这种写法相对陌生一些,许多语言中都没有这种特性。1958年,Lisp首先支持函数表达式,也支持调用lambda函数,而C++,Python、C#以及Java在随后的多年中一直不支持这样的特性。
现在截然不同,所有的四种语言都已支持lambda函数,更新出现的语言普遍都支持内建的lambda函数。我们必须要感谢JavaScript和早期的JavaScript程序员,他们勇敢地构建了重度依赖lambda函数的库,让这种特性被广泛接受。
令人伤感的是,随后在所有我提及的语言中,只有JavaScript的lambda的语法最终变得冗长乏味。
// 六种语言中的简单函数示例
function (a) { return a > 0; } // JS
[](int a) { return a > 0; } // C++
(lambda (a) (> a 0)) ;; Lisp
lambda a: a > 0 # Python
a => a > 0 // C#
a -> a > 0 // Java
ES6中引入了一种编写函数的新语法
// ES5
var selected = allJobs.filter(function (job) {
return job.isSelected();
});
// ES6
var selected = allJobs.filter(job => job.isSelected());
当你只需要一个只有一个参数的简单函数时,可以使用新标准中的箭头函数,它的语法非常简单:标识符=>表达式。你无需输入function和return,一些小括号、大括号以及分号也可以省略。
(我个人对于这个特性非常感激,不再需要输入function这几个字符对我而言至关重要,因为我总是不可避免地错误写成functoin,然后我就不得不回过头改正它。)
如果要写一个接受多重参数(也可能没有参数,或者是不定参数、默认参数、参数解构)的函数,你需要用小括号包裹参数list。
// ES5
var total = values.reduce(function (a, b) {
return a + b;
}, 0);
// ES6
var total = values.reduce((a, b) => a + b, 0);
我认为这看起来酷毙了。
正如你使用类似Underscore.js和Immutable.js这样的库提供的函数工具,箭头函数运行起来同样美不可言。事实上,Immutable的文档中的示例全都由ES6写成,其中的许多特性已经用上了箭头函数。
那么不是非常函数化的情况又如何呢?除表达式外,箭头函数还可以包含一个块语句。回想一下我们之前的示例:
// ES5
$("#confetti-btn").click(function (event) {
playTrumpet();
fireConfettiCannon();
});
这是它们在ES6中看起来的样子:
// ES6
$("#confetti-btn").click(event => {
playTrumpet();
fireConfettiCannon();
});
这是一个微小的改进,对于使用了Promises的代码来说箭头函数的效果可以变得更加戏剧性,}).then(function (result) { 这样的一行代码可以堆积起来。
注意,使用了块语句的箭头函数不会自动返回值,你需要使用return语句将所需值返回。
小提示:当使用箭头函数创建普通对象时,你总是需要将对象包裹在小括号里。
// 为与你玩耍的每一个小狗创建一个新的空对象
var chewToys = puppies.map(puppy => {}); // 这样写会报Bug!
var chewToys = puppies.map(puppy => ({})); //
用小括号包裹空对象就可以了。
不幸的是,一个空对象{}和一个空的块{}看起来完全一样。ES6中的规则是,紧随箭头的{被解析为块的开始,而不是对象的开始。因此,puppy => {}这段代码就被解析为没有任何行为并返回undefined的箭头函数。
更令人困惑的是,你的JavaScript引擎会将类似{key: value}的对象字面量解析为一个包含标记语句的块。幸运的是,{是唯一一个有歧义的字符,所以用小括号包裹对象字面量是唯一一个你需要牢记的小窍门。
普通function函数和箭头函数的行为有一个微妙的区别,箭头函数没有它自己的this值,箭头函数内的this值继承自外围作用域。
在我们尝试说明这个问题前,先一起回顾一下。
JavaScript中的this是如何工作的?它的值从哪里获取?这些问题的答案可都不简单,如果你对此倍感清晰,一定因为你长时间以来一直在处理类似的问题。
这个问题经常出现的其中一个原因是,无论是否需要,function函数总会自动接收一个this值。你是否写过这样的hack代码:
{
...
addAll: function addAll(pieces) {
var self = this;
_.each(pieces, function (piece) {
self.add(piece);
});
},
...
}
在这里,你希望在内层函数里写的是this.add(piece),不幸的是,内层函数并未从外层函数继承this的值。在内层函数里,this会是window或undefined,临时变量self用来将外部的this值导入内部函数。(另一种方式是在内部函数上执行.bind(this),两种方法都不甚美观。)
在ES6中,不需要再hackthis了,但你需要遵循以下规则:
// ES6
{
...
addAll: function addAll(pieces) {
_.each(pieces, piece => this.add(piece));
},
...
}
在ES6的版本中,注意addAll方法从它的调用者处获取了this值,内部函数是一个箭头函数,所以它继承了外围作用域的this值。
超赞的是,在ES6中你可以用更简洁的方式编写对象字面量中的方法,所以上面这段代码可以简化成:
// ES6的方法语法
{
...
addAll(pieces) {
_.each(pieces, piece => this.add(piece));
},
...
}
在方法和箭头函数之间,我再也不会错写functoin了,这真是一个绝妙的设计思想!
箭头函数与非箭头函数间还有一个细微的区别,箭头函数不会获取它们自己的arguments对象。诚然,在ES6中,你可能更多地会使用不定参数和默认参数值这些新特性。
我们已经讨论了许多箭头函数的实际用例,它还有一种可能的使用方法:将ES6箭头函数作为一个学习工具,来深入挖掘计算的本质,是否实用,终将取决于你自己。
1936年,Alonzo Church和Alan Turing各自开发了强大的计算数学模型,图灵将他的模型称为a-machines,但是每一个人都称其为图灵机。Church写的是函数模型,他的模型被称为lambda演算(λ-calculus)。这一成果也被Lisp借鉴,用LAMBDA来指示函数,这也是为何我们现在将函数表达式称为lambda函数。
用几句话解释清楚很难,但是我会努力阐释:lambda演算是第一代编程语言的一种形式,但毕竟存储程序计算机在十几二十年后才诞生,所以它原本不是为编程语言设计的,而是为了表达任意你想到的计算问题设计的一种极度简化的纯数学思想的语言。Church希望用这个模型来证明普遍意义的计算。
最终他发现,在他的系统中只需要一件东西:函数。
这种声明方式无与伦比,不借助对象、数组、数字、if语句、while循环、分号、赋值、逻辑运算符甚或是事件循环,只须使用函数就可以从0开始重建JavaScript能实现的每一种计算。
这是用Church的lambda标记写出来的数学家风格的“程序”示例:
fix = λf.(λx.f(λv.x(x)(v)))(λx.f(λv.x(x)(v)))
等效的JavaScript函数是这样的:
var fix = f => (x => f(v => x(x)(v)))
(x => f(v => x(x)(v)));
所以,在JavaScript中实现了一个可以运行的lambda演算,它根植于这门语言中。
Alonzo Church和lambda演算后继研究者们的故事,以及它是如何潜移默化地入驻每一门主流编程语言的,已经远超本文的讨论范围。但是如果你对计算机科学 的奠基感兴趣,或者你只是对一门只用函数就可以做许多类似循环和递归这样的事情的语言倍感兴趣,你可以在一个下雨的午后深入邱奇数(Church numerals)和不动点组合子(Fixed-point combinator),在你的Firefox控制台或Scratchpad中仔细研究一番。结合ES6的箭头函数以及其它强大的功能,JavaScript称得上是一门探索lambda演算的最好的语言。
早在2013年,我就在Firefox中实现了ES6箭头函数的功能,Jan de Mooij为其优化加快了执行速度。感谢Tooru Fujisawa以及ziyunfei(译者注:中国开发者,为Mozilla作了许多贡献)后续打的补丁。
微软Edge预览版中也实现了箭头函数的功能,如果你想立即在你的Web项目中使用箭头函数,可以使用Babel、Traceur或TypeScript,这三个工具均已实现相关功能。
你是否知道ES6中的Symbols是什么,它有什么作用呢?我相信你很可能不知道,那就让我们一探究竟!
Symbols并非用来指代某种Logo。
它们也不是可以用作代码的小图标。
它们不是代替其它东西的文学手法。
它们更不可能被用来指代谐音词Cymbals(铙钹)。
(编程的时候最好不要演奏铙钹,它们太过吵闹,很可能导致你的程序崩溃。)
那么,Symbols到底是什么呢?
1997年JavaScript首次被标准化,那时只有六种原始类型,在ES6以前,JS程序中使用的每一个值都是以下几种类型之一:
每种类型都是多个值的集合,前五个集合是有限的。布尔类型只有两个值,true和false,不会再创造第三种布尔值;数字类型和字符串类型的值更多,标准指明一共有18,437,736,874,454,810,627种不同的数字(包括NaN, 亦即“Not a Number”的缩写,代表非数字),可能存在的字符串类型的值拥有无以匹敌的数量,我估算了一下大约是 (2144,115,188,075,855,872 − 1) ÷ 65,535种……当然,我很可能得出了一个错误的答案,但字符串类型值的集合一定是有限的。
然而,对象类型值的集合是无限的。每一个对象都像珍贵的雪花一样独一无二,每一次你打开一个Web页面,都会创建一堆对象。
ES6新特性中的symbol也是值,但它不是字符串,也不是对象,而是是全新的——第七种类型的原始值。
让我们一起探讨一下symbol的实际应用场景。
有时候你可以非常轻松地将别人的外部数据存储到一个JavaScript对象中。
举 个例子,假设你正在写一个JS库,可以通过CSS transitions使DOM元素在屏幕上移动。你可能会注意到,当你尝试在一个div元素上同时应用多重CSS transitions时并不会生效。实际效果是丑陋而又不连续的“跳闪”。你认为可以修复这个问题,但前提是你需要一种发现给定元素是否已经移动过的方 法。
应当如何解决这个问题呢?
一种方法是,用CSS API来告诉浏览器元素是否正在移动,但这样简直小题大做。在元素移动的第一时间内你的库就应该记录下移动的状态,所以它自然知道元素正在移动。
你真正想要的是一种持续跟踪某个元素正在移动的方法。你可以维护一个数组,记录所有正在移动的元素,每当你的库被调用来移动某个元素时,你可以检索数组来查看元素是否已经存在,亦即它是否正在移动中。
当然,如果数组非常大的话,线性搜索将会非常缓慢。
实际上你只想为元素设置一个标记:
if (element.isMoving) {
smoothAnimations(element);
}
element.isMoving = true;
这样也会有一些潜在的问题,事实上,你的代码很可能不是唯一一段操作DOM的代码。
当然你可以选择一个乏味而愚蠢的命名(其他人根本不会想用的那些名称)来解决最后的三个问题:
if (element.__$jorendorff_animation_library$PLEASE_DO_NOT_USE_THIS_PROPERTY$isMoving__) {
smoothAnimations(element);
}
element.__$jorendorff_animation_library$PLEASE_DO_NOT_USE_THIS_PROPERTY$isMoving__ = true;
这只会造成无畏的眼疲劳。
借助于密码学,你可以生成一个唯一的属性名称:
// 获取1024个Unicode字符的无意义命名
var isMoving = SecureRandom.generateName();
...
if (element[isMoving]) {
smoothAnimations(element);
}
element[isMoving] = true;
object[name]语法允许你使用几乎任何字符串作为属性名称。所以这个方法行之有效:冲突几乎是不可能的,并且你的代码看起来也很简洁。
但是这也将带来不良的调试体验。每当你在控制台输出(console.log())包含那个属性的元素时,你将会看到一堆巨大的字符串垃圾。假使你需要比这多得多的类似属性呢?你如何保持它们整齐划一?每当你重载的时候它们的命名甚至都不一样!
为什么这个问题如此困难?我们只想要一个小小的布尔值啊!
symbol是程序创建并且可以用作属性键的值,并且它能避免命名冲突的风险。
var mySymbol = Symbol();
调用Symbol()创建一个新的symbol,它的值与其它任何值皆不相等。
字符串或数字可以作为属性的键,symbol也可以,它不等同于任何字符串,因而这个以symbol为键的属性可以保证不与任何其它属性产生冲突。
obj[mySymbol] = "ok!"; // 保证不会冲突
console.log(obj[mySymbol]); // ok!
想要在上述讨论的场景中使用symbol,你可以这样做:
// 创建一个独一无二的symbol
var isMoving = Symbol("isMoving");
...
if (element[isMoving]) {
smoothAnimations(element);
}
element[isMoving] = true;
有关这段代码的一些解释:
symbol键的设计初衷是避免初衷,因此JavaScript中最常见的对象检查的特性会忽略symbol键。例如,for-in循环只会遍历对象的字符串键,symbol键直接跳过,Object.keys(obj)和Object.getOwnPropertyNames(obj)也是一样。但是symbols也不完全是私有的:用新的API Object.getOwnPropertySymbols(obj)就可以列出对象的symbol键。另一个新的API,Reflect.ownKeys(obj),会同时返回字符串键和symbol键。(我们将在随后的文章中讲解Reflect(反射) API)。
慢慢地我们会发现,越来越多的库和框架将大量使用symbol,语言本身也会将symbol应用于广泛的用途。
> typeof Symbol()
"symbol"
确切地说,symbol与其它类型并不完全相像。
symbol被创建后就不可变更,你不能为它设置属性(在严格模式下尝试设置属性会得到TypeError的错误)。他们可以用作属性名称,这些性质与字符串类似。
另一方面,每一个symbol都独一无二,不与其它symbol等同,即使二者有相同的描述也不相等;你可以轻松地创建一个新的symbol。这些性质与对象类似。
ES6中的symbol与Lisp和Ruby这些语言中更传统的symbol类似,但不像它们集成得那么紧密。在Lisp中,所有的标识符都是symbol;在JS中,标识符和大多数的属性键仍然是字符串,symbol只是一个额外的选项。
关于symbol的忠告:symbol不能被自动转换为字符串,这和语言中的其它类型不同。尝试拼接symbol与字符串将得到TypeError错误。
> var sym = Symbol("<3");
> "your symbol is " + sym
// TypeError: can't convert symbol to string
> `your symbol is ${sym}`
// TypeError: can't convert symbol to string
通过String(sym)或sym.toString()可以显示地将symbol转换为一个字符串,从而回避这个问题。
有三种获取symbol的方法。
如果你尚不确定symbol是否实用,最后这一章将向你展示symbol在实际应用中发挥的巨大作用,非常有趣!
在之前的文章《深入浅出ES6(二):迭代器和for-of循环》中,我们已经领略了借助ES6 symbol的力量避免代码冲突的方法,循环for (var item of myArray)首先调用myArray[Symbol.iterator](),当时我提到这种写法是为了替代myArray.iterator(),拥有更好的向后兼容性。
现在我们知道symbol到底是什么了,自然很容易理解为什么我们要创造一个symbol以及它为我们带来什么新特性。
ES6中还有其它几处使用了symbol的地方。(这些特性在Firefox里尚未实现。)
这些用例的应用范围都非常小,很难看到这些特性通过它们自身影响我们每日的代码,长期来看才能体现它们的价值。实际上,symbol是php和Python中的__doubleUnderscores在JavaScript语言环境中的改进版。标准将借助symbol的力量在未来向语言中添加新的钩子,同时无风险地将新特性添加到你已有的代码中。
symbol在Firefox 36和Chrome 38中均已被实现。Firefox中的实现由我亲自完成,所以如果你的symbol像铙钹(cymbals)一样行为异常,请直接联系我!
为了支持那些尚未支持原生ES6 symbol的浏览器,你可以使用一个polyfill,例如core.js。因为symbol与其它类型不尽相同,所以polyfill目前不是很完美。请阅读注意事项。
前段时间,官方名为“ECMA-262,第六版,ECMAScript 2015语言规范”的ES6规范终于结束了最后的征途,正式被认可为新的ECMA标准。让我们祝贺TC39等所有作出贡献人们,ES6终于定稿了!
更好的消息是,下次更新不需要再等六年了。委员会现在努力要求,大约每12个月完成一个新的版本。第七版提议已经开始。
现在是时候庆祝庆祝了,让我们来讨论一些很久以来我一直希望在JS里看到的东西——当然,它们以后仍然有改进的余地。
JS和其它编程语言有些特殊的差别,有时,它们会以令人惊奇的方式影响到这门语言的发展。
ES6模块就是个很好的例子。其它语言的模块化系统中,Racket做得特别棒,Python也很好。那么,当标准委员会决定在ES6中增加模块时,为什么他们不直接仿照一套已经存在的系统呢?
因为JS是不同的,因为它要在浏览器里运行。读取和写入都可能花费较长时间,所以,JS需要一套支持异步加载代码的模块化系统,同时,也不能允许在文件夹中挨个搜索,照搬已有的系统并不能解决问题。ES6的模块化系统需要一些新技术。
讨论这些问题对最终设计的影响,会是个有趣的故事,不过我们今天要讨论的并不是模块。
这篇文章是关于ES6标准中所谓“键值集合”的:Set,Map,WeakSet和WeakMap。它们在大多数方面和其它语言中的哈希表一样,不过,正因为JS是不同的,标准委员会在其中做了些有趣的权衡与调整。
熟悉JS一定会知道,我们已经有了一种类似哈希表的东西:对象(Object)。
一个普通的对象毕竟就只是一个开放的键值对集合。你可以进行获取、设置、删除、遍历——任何一个哈希表支持的操作。所以我们到底为什么要增加新的特性?
好吧,大多数程序简单地用对象来存储键值对就够了,对它们而言,没什么必要换用Map或Set。但是,直接这样使用对象有一些广为人知的问题:
ES6中又出现了新问题:纯粹的对象不可遍历,也就是,它们不能配合for-of循环或...操作符等语法。
嗯,确实很多程序里这些问题都不重要,直接用纯对象仍然是正确的选择。Map和Set是为其它场合准备的。
这些ES6中的集合本来就是为避免用户数据与内置方法冲突而设计的,所以它们不会把数据作为属性暴露出来。也就是说,obj.key或obj[key]不能再用来访问数据了,取而代之的是map.get(key)。同时,不像属性,哈希表的键值不能通过原型链来继承了。
好消息是,不像纯粹的Object,Map和Set有自己的方法了,并且,更多标准或自定义的方法可以无需担心冲突地加入。
一个Set是一群值的集合。它是可变的,能够增删元素。现在,还没说到它和数组的区别,不过它们的区别就和相似点一样多。
首先,和数组不同,一个Set不会包含相同元素。试图再次加入一个已有元素不会产生任何效果。
这个例子里元素都是字符串,不过Set是可以包含JS中任何类型的值的。同样,重复加入已有元素不会产生效果。
其次,Set的数据存储结构专门为一种操作作了速度优化:包含性检测。
> // 检查"zythum"是不是一个单词
> arrayOfWords.indexOf("zythum") !== -1 // 慢
true
> setOfWords.has("zythum") // 快
true
Set不能提供的则是索引。
> arrayOfWords[15000]
"anapanapa"
> setOfWords[15000] // Set不支持索引
undefined
以下是Set支持的所有操作:
在这些特性中,负责构造集合的new Set(iterable)是唯一一个在整个数据结构层面上操作的。你可以用它把数组转化为集合,在一行代码内去重;也可以传递一个生成器,函数会逐个遍历它,并把生成的值收录为一个集合;也可以用来复制一个已有的集合。
上周我答应过要给ES6中的新集合们挑挑刺,就从这里开始吧。尽管Set已经很不错了,还是有些被遗漏的方法,说不定补充到将来某个标准里会挺不错:
好消息是,这些都可以用ES6已经提供了的方法来实现。
一个Map对象由若干键值对组成,支持:
还有什么要抱怨的?以下是我觉得会有用而ES6还没提供的特性:
同样,这些特性也是很容易加上的。
到这里,还记不记得,开篇时我提到过运行于浏览器对语言特性设计的特殊影响?现在要好好谈一谈这个问题了。我已经有了三个例子,以下是前两个。
到目前为止,据我所知,ES6的集合类完全不支持下述这种有用的特性。
比如说,我们有若干 URL 对象组成的Set:
var urls = new Set;
urls.add(new URL(location.href)); // 两个 URL 对象。
urls.add(new URL(location.href)); // 它们一样么?
alert(urls.size); // 2
这两个 URL 应该按相同处理,毕竟它们有完全一样的属性。但在JavaScript中,它们是各自独立、互不相同的,并且,绝对没有办法来重载相等运算符。
其它一些语言就支持这一特性。在Java, Python, Ruby中,每个类都可以重载它的相等运算符;Scheme的许多实现中,每个哈希表可以使用不同的相等关系。C++则两者都支持。
但是,所有这些机制都需要编写者自行实现一个哈希函数并暴露出系统默认的哈希函数。在JS中,因为不得不考虑其它语言不必担心的互用性和安全性,委员会选择了不暴露——至少目前仍如此。
你多半觉得一台计算机具有确定性行为是理所应当的,但当我告诉别人遍历Map或Set的顺序就是其中元素的插入顺序时,他们总是很惊奇。没错,它就是确定的。
我们已经习惯了哈希表某些方面任性的行为,我们学会了接受它。不过,总有一些足够好的理由让我们希望尝试避免这种不确定性。2012年我写过:
在2012年2月以上种种意见被提出时,我是支持不确定遍历序的。然后,我决定用实验证明,保存插入序将过度降低哈希表的效率。我写了一个C++的小型基准测试,结果却令我惊奇地恰恰相反。
这就是我们最终为JS设计了按插入序遍历的哈希表的过程。
上篇文章我们讨论了一个JS动画库相关的例子。我们试着要为每个DOM对象设置一个布尔值类型的标识属性,就像这样:
if (element.isMoving) {
smoothAnimations(element);
}
element.isMoving = true;
不幸的是,这样给一个DOM对象增加属性不是个好主意。原因我们上次已经解释过了。
上次的文章里,我们接着展示了用Symbol解决这个问题的方法。但是,可以用集合来实现同样的效果么?也许看上去会像这样:
if (movingSet.has(element)) {
smoothAnimations(element);
}
movingSet.add(element);
这只有一个坏处。Map和Set都为内部的每个键或值保持了强引用,也就是说,如果一个DOM元素被移除了,回收机制无法取回它占用的内存,除非movingSet中也删除了它。在最理想的情况下,库在善后工作上对使用者都有复杂的要求,所以,这很可能引发内存泄露。
ES6给了我们一个惊喜的解决方案:用WeakSet而非Set。和内存泄露说再见吧!
也 就是说,这个特定情景下的问题可以用弱集合(weak collection)或Symbol两种方法解决。哪个更好呢?不幸的是,完整地讨论利弊取舍会把这篇文章拖得有些长。简而言之,如果能在整个网页的生 命周期内使用同一个Symbol,那就没什么问题;如果不得不使用一堆临时的Symbol,那就危险了,是时候考虑WeakMap来避免内存泄露了。
WeakMap和WeakSet被设计来完成与Map、Set几乎一样的行为,除了以下一些限制:
还要注意,这两种弱集合都不可迭代,除非专门查询或给出你感兴趣的键,否则不能获得一个弱集合中的项。
这些小心设计的限制让垃圾回收机制能回收仍在使用中的弱集合里的无效对象。这效果类似于弱引用或弱键字典,但ES6的弱集合可以在不暴露脚本中正在垃圾回收的前提下得到垃圾回收的效益。
弱集合实际上是用 ephemeron 表实现的。
简单说,一个WeakSet并不对其中对象保持强引用。当WeakSet中的一个对象被回收时,它会简单地被从WeakSet中移除。WeakMap也类似地不为它的键保持强引用。如果一个键仍被使用,相应的值也就仍被使用。
为什么要接受这些限制呢?为什么不直接在JS中引入弱引用呢?
再 次地,这是因为标准委员会很不愿意向脚本暴露未定义行为。孱弱的跨浏览器兼容性是互联网发展的痛苦之源。弱引用暴露了底层垃圾回收的实现细节——这正是与 平台相关的一个未定义行为。应用当然不应该依赖平台相关的细节,但弱引用使我们难于精确了解自己对测试使用的浏览器的依赖程度。这是件很不讲道理的事情。
相比之下,ES6的弱集合只包含了一套有限的特性,但它们相当牢靠。一个键或值被回收从不会被观测到,所以应用将不会依赖于其行为,即使只是缘于意外。
这是针对互联网的特殊考量引发了一个惊人的设计、进而使JS成为一门更好语言的一个例子。
总计四种集合类在Firefox、Chrome、Microsoft Edge、Safari中都已实现,要支持旧浏览器则需要 ES6 - Collections 之类来补全。
Firefox中的WeakMap 最初由 Andreas Gal 实现,他后来当了一段时间Mozilla的CTO。Tom Schuster实现了WeakSet,我实现了Map和Set。感谢Tooru Fujisawa贡献的几个相关补丁。
自ES6正式发布,人们已经开始讨论ES7:未来版本会保留哪些特性,新标准可能提供什么样的新特性。作为Web开发者,我们想知道如何发挥这一切的巨大能量。在深入浅出ES6系列之前的文章中,我们不断鼓励你开始在编码中加入ES6新特性,辅以一些有趣的工具,你完全可以从现在开始使用ES6:
如果你想在Web端使用这种新语法,你可以通过Babel或Google的Traceur将你的ES6代码转译为Web友好的ES5代码。
现在,我们将向你分步展示如何做到的这一切。上面提及的工具被称为转译器,你可以将它理解为源代码到源代码的编译器——一个在可比较的抽象层上操作不同编程语言相互转换的编译器。转译器允许我们用ES6编写代码,同时保证这些代码能在每一个浏览器中执行。
转译器使用起来非常简单,只需两步即可描述它所做的事情:
1,用ES6的语法编写代码。
let q = 99;
let myVariable = `${q} bottles of beer on the wall, ${q} bottles of beer.`;
2,用上面那段代码作为转译器的输入,经过处理后得到以下这段输出:
"use strict";
var q = 99;
var myVariable = "" + q + " bottles of beer on the wall, " + q + " bottles of beer."
这正是我们熟知的老式JavaScript,这段代码可以在任意浏览器中运行。
转译器内部从输入到输出的逻辑高度复杂,完全超出本篇文章的讲解范围。正如我们无须知道所有的内部引擎结构就可以驾驶一辆汽车,现在,我们同样可以将转译器视为一个能够处理我们代码的黑盒。
你可以通过几种不同的方法在项目中使用Babel,有一个命令行工具,在这个工具中可以使用如下形式的指令:
babel script.js --out-file script-compiled.js
Babel也提供支持在浏览器中使用的版本。你可以将Babel作为一个普通的库引入,然后将你的ES6代码放置在类型为text/babel的script标签中。
<script src="node_modules/babel-core/browser.js"></script>
<script type="text/babel">
// 你的ES6代码
</script>
随着代码库爆炸式增长,你开始将所有代码划分为多个文件和文件夹,但是这些方法并不能随之扩展。到那时,你将需要一个构建工具以及一种将Babel与构建管道整合在一起的方法。
在接下来的章节中,我们将要把Babel整合到构建工具Broccoli.js中,我们将在两个示例中编写并执行第一行ES6代码。如果你的代码无法正常运行,可以在这里(broccoli-babel-examples)查看完整的源代码。在这个仓库中你可以找到三个示例项目:
每一个项目都构建于前一个示例的基础之上,我们会从最小的项目开始,逐步得出一个一般的解决方案,为日后每一个雄心壮志的项目打下良好的开端。这篇文章只包含前两个示例,阅读文章后,你完全可以自行阅读第三个示例中的代码并加以理解。
如果你在想——我坐等浏览器支持这些新特性就好了啦——那么你一定会落后的!实现所有功能要花费很长时间,况且现在有成熟的转译器,而且 ECMAScript加快了发布新版本的周期(每年一版),我们将会看到新标准比统一的浏览器平台更新得更频繁。所以赶快加入我们,一起发挥新特性的巨大威力吧!
Broccoli是一个用来快速构建项目的工具,你可以用它对文件进行混淆与压缩,还可以通过众多的Broccoli插件实现许多其它功能。它帮助我们处理文件和目录,每当项目变更时自动执行指令,很大程度上减轻了我们的负担。你不妨将它视为:
类似Rails的asset管道,但是Broccoli运行在Node上且可以对接任意后端。
你可能已经猜到了,你需要安装Node 0.11或更高版本。
如果你使用unix系统,不要从包管理器(apt、yum等)中安装,这样可以避免在安装过程中使用root权限,最好使用当前的用户权限,通过上面的链接手动安装。在文章《不要sudo npm》中可以了解为什么不推荐使用root权限,文章中也给出了其它安装方案。
首先,我们要配置好Broccoli项目:
mkdir es6-fruits
cd es6-fruits
npm init
# 创建一个名为Brocfile.js的空文件
touch Brocfile.js
现在我们安装broccoli和broccoli-cli
# 安装broccoli库
npm install --save-dev broccoli
# 命令行工具
npm install -g broccoli-cli
创建src文件夹,在里面置入fruits.js文件。
mkdir src
vim src/fruits.js
用ES6语法在新文件中写一小段脚本。
let fruits = [
{id: 100, name: '草莓'},
{id: 101, name: '柚子'},
{id: 102, name: '李子'}
];
for (let fruit of fruits) {
let message = `ID: ${fruit.id} Name: ${fruit.name}`;
console.log(message);
}
console.log(`List total: ${fruits.length}`);
上面的代码示例使用了三个ES6特性:
保存文件,尝试执行脚本。
node src/fruits.js
目前这段代码不能正常运行,但是我们将会让它运行在Node与任何浏览器中。
let fruits = [
^^^^^^
SyntaxError: Unexpected identifier
现在,我们用Broccoli加载代码,然后用Babel处理它。编辑Brocfile.js文件并加入以下这段代码:
// 引入babel插件
var babel = require('broccoli-babel-transpiler');
// 获取源代码,执行转译指令(仅需1步)
fruits = babel('src'); // src/*.js
module.exports = fruits;
注意我们引入了包裹在Babel库中的Broccoli插件broccoli-babel-transpiler,所以我们一定要安装它:
npm install --save-dev broccoli-babel-transpiler
现在我们可以构建项目并执行脚本了:
broccoli build dist # 编译
node dist/fruits.js # 执行ES5
输出结果看起来应当是这样的:
ID: 100 Name: 草莓
ID: 101 Name: 柚子
ID: 102 Name: 李子
List total: 3
那很简单!你可以打开dist/fruits.js查看转译后代码。Babel转译器的一个优秀特性是它能够生产可读的代码。
在第二个示例中,我们将做进一步提升。首先,退出es6-fruits文件夹,然后使用上述配置项目一章中列出的步骤创建新目录es6-website。
在src文件夹中创建三个文件:src/index.html
<!DOCTYPE html>
<html>
<head>
<title>马上使用ES6</title>
</head>
<style>
body {
border: 2px solid #9a9a9a;
border-radius: 10px;
padding: 6px;
font-family: monospace;
text-align: center;
}
.color {
padding: 1rem;
color: #fff;
}
</style>
<body>
<h1>马上使用ES6</h1>
<div id="info"></div>
<hr>
<div id="content"></div>
<script src="//code.jquery.com/jquery-2.1.4.min.js"></script>
<script src="js/my-app.js"></script>
</body>
</html>src/print-info.js
function printInfo() {
$('#info')
.append('<p>用Broccoli和Babel构建的' +
'最小网站示例</p>');
}
$(printInfo);src/print-colors.js
// ES6生成器
function* hexRange(start, stop, step) {
for (var i = start; i < stop; i += step) {
yield i;
}
}
function printColors() {
var content$ = $('#content');
// 人为的示例
for ( var hex of hexRange(900, 999, 10) ) {
var newDiv = $('<div>')
.attr('class', 'color')
.css({ 'background-color': `#${hex}` })
.append(`hex code: #${hex}`);
content$.append(newDiv);
}
}
$(printColors);
你可能已经注意到function* hexRange,是的,那是ES6的生成器。这个特性目前尚未被所有浏览器支持。为了能够使用这个特性,我们需要一个polyfill,Babel中已经支持,我们很快将投入使用。
下一步是合并所有JS文件然后在网站中使用。最难的部分是编写Brocfile文件,这一次我们要安装4个插件:
npm install --save-dev broccoli-babel-transpiler
npm install --save-dev broccoli-funnel
npm install --save-dev broccoli-concat
npm install --save-dev broccoli-merge-trees
把它们投入使用:
// Babel转译器
var babel = require('broccoli-babel-transpiler');
// 过滤树(文件的子集)
var funnel = require('broccoli-funnel');
// 连结树
var concat = require('broccoli-concat');
// 合并树
var mergeTrees = require('broccoli-merge-trees');
// 转译源文件
var appJs = babel('src');
// 获取Babel库提供的polyfill文件
var babelPath = require.resolve('broccoli-babel-transpiler');
babelPath = babelPath.replace(//index.js$/, '');
babelPath += '/node_modules/babel-core';
var browserPolyfill = funnel(babelPath, {
files: ['browser-polyfill.js']
});
// 给转译后的文件树添加Babel polyfill
appJs = mergeTrees([browserPolyfill, appJs]);
// 将所有JS文件连结为一个单独文件
appJs = concat(appJs, {
// 我们指定一个连结顺序
inputFiles: ['browser-polyfill.js', '**/*.js'],
outputFile: '/js/my-app.js'
});
// 获取入口文件
var index = funnel('src', {files: ['index.html']});
// 获取所有的树
// 并导出最终单一的树
module.exports = mergeTrees([index, appJs]);
现在开始构建并执行我们的代码。
broccoli build dist
这次你在dist文件夹中应该看到以下结构:
$> tree dist/
dist/
├── index.html
└── js
└── my-app.js
那是一个静态网站,你可以用任意服务器伺服来验证那段代码正常运行。举个例子:
cd dist/
python -m SimpleHTTPServer
# 访问http://localhost:8000/
你应该可以看到:
上述第二个示例给出了一个通过Babel实现功能的思路,它可能足够你用上一阵子了。如果你想要更多有关ES6、Babel和Broccoli的内容,可以查看broccoli-babel-boilerplate,这个仓库中的代码可以提供Broccoli+Babel项目的配置,而且高出至少两个层次。这个样板可以文件处理模块、模块导入以及单元测试。
通过这些配置,你可以在示例es6-modules中亲自实践。Brocfile魔力无穷,与我们之前实现的非常类似。
正如你看到的,Babel和Broccoli对于在Web网站中应用ES6新特性非常实用。
请看这样一段代码:
var obj = new Proxy({}, {
get: function (target, key, receiver) {
console.log(`getting ${key}!`);
return Reflect.get(target, key, receiver);
},
set: function (target, key, value, receiver) {
console.log(`setting ${key}!`);
return Reflect.set(target, key, value, receiver);
}
});
代码乍一看有些复杂,使用了一些陌生的特性,稍后我会详细讲解每一部分。现在,一起来看一下我们创建的对象:
> obj.count = 1;
setting count!
> ++obj.count;
getting count!
setting count!
2
显示结果可能与我们的理解不太一样,为什么会输出“setting count”和“getting count”?其实,我们拦截了这个对象的属性访问方法,然后将“.”运算符重载了。
计算领域最好的的技巧是虚拟化,这种技术一般用来实现惊人的功能。它的工作机制如下:
你可能在《楚门的世界》和《黑客帝国》这类经典的计算机科学电影中见到过类似的hack方法,将世界划分为两个部分,主人公生活在内部世界,外部世界被精心编造的常态幻觉所替换。
为了满足向后兼容的规则,你需要巧妙地设计填补进去的图片,但是真正的技巧是正确地勾勒轮廓。
我所谓的轮廓是指一个API边界或接口,接口可以详细说明两段代码的交互方式以及交互双方对另一半的需求。所以如果一旦在系统中设计好了接口,轮廓自然就清晰了,这样就可以任意替换接口两侧的内容而不影响二者的交互过程。
如果没有现成的接口,就需要施展你的创意才华来创造新接口,有史以来最酷的软件hack总是会勾勒一些之前从未有过的API边界,然后通过大量的工程化实践将接口引入到现有的体系中去。
虚拟内存、硬件虚拟化、Docker、Valgrind、rr等不同抽象程度的项目都会基于现有的系统推动开发一些令人意想不到的新接口。在某些情况下,需要花费数年的时间、新的操作系统特性甚至是新的硬件来使新的边界良好运转。
最棒的虚拟化hack会带来对需要虚拟的东西的新的理解。想要编写一个API,你需要充分理解你所面向的对象,一旦你理解透彻,就能实现出令人惊异的成果。
而ES6则为JavaScript中最基本的概念“对象(object)”引入了虚拟化支持。
噢,我是说真的,请花费一点时间仔细想想这个问题的答案。当你清楚自己知道对象是什么的的时候再向下滚动。
这个问题于我而言太难了!我从未听到过一个非常满意的定义。
这会让你感到惊讶么?定义基础概念向来很困难——抽空看看欧几里得在《几何原本》中的前几个定义你就知道了。ECMAScript语言规范很棒,可是却将对象定义为“type对象的成员”,这种定义真的对我们没什么帮助。
后来,规范中又添加了一个定义:“对象是属性的集合”。这句话没错,目前来说可以这样定义,我们稍后继续讨论。
我之前说过,想要编写一个API,你需要充分理解你所面向的对象。所以在某种程度上,我也算对本文做出一个承诺,我们会一起深入理解对象的细节,然后一起实现酷炫的功能。
那么我们就跟随ECMAScript标准委员会的脚步,为JavaScript对象定义一个API,一个接口。问题是我们需要什么方法?对象又可以做什么呢?
这个问题的答案一定程度上取决于对象的类型:DOM元素对象可以做一部分事情,音频节点对象又可以做另外一部分事情,但是所有对象都会共享一些基础功能:
几乎所有处理对象的JS程序都是使用属性、原型和函数来完成的。甚至元素或声音节点对象的特殊行为也是通过调用继承自函数属性的方法来进行访问。
所以ECMAScript标准委员会定义了一个由14种内部方法组成的集合,亦即一个适用于所有对象的通用接口,属性、原型和函数这三种基础功能自然成为它们关注的核心。
我们可以在ES6标准列表5和6中找到全部的14种方法,我只会在这里讲解其中一部分。双方括号[[ ]]代表内部方法,在一般的JS代码中不可见,你可以调用、删除或覆写普通方法,但是无法操作内部方法。
可能你也可以猜到其它七个内部方法。
在整个ES6标准中,只要有可能,任何语法或对象相关的内建函数都是基于这14种内部方法构建的。ES6在对象的中枢系统周围划分了一个清晰的界限,你可以借助代理特性用任意JS代码替换标准中枢系统的内部方法。
既然我们马上要开始讨论覆写内部方法的相关问题,请记住,我们要讨论的是诸如obj.prop的核心语法、诸如Object.keys()的内建函数等的行为。
ES6规范定义了一个全新的全局构造函数:代理(Proxy)。它可以接受两个参数:目标对象(target)与句柄对象(handler)。请看一个简单的示例:
var target = {}, handler = {};
var proxy = new Proxy(target, handler);
我们先来探讨代理和目标对象之间的关系,然后再研究句柄对象的功用。
代理的行为很简单:将代理的所有内部方法转发至目标。简单来说,如果调用proxy.[[Enumerate]](),就会返回target.[[Enumerate]]()。
现在,让我们尝试执行一条能够触发调用proxy.[[Set]]()方法的语句。
proxy.color = "pink";
好的,刚刚都发生了什么?proxy.[[Set]]()应该调用target.[[Set]]()方法,然后在目标上创建一个新的属性。实际的结果如何?
> target.color
"pink"
是的,它做到了!对于所有其它内部方法而言同样可以做到。新创建的代理会尽可能与目标的行为一致。
当然,它们也不完全相同,你会发现proxy !== target。有时也有目标能够通过类型检测而代理无法通过的情况发生,举个例子,如果代理的目标是一个DOM元素,相应的代理就不是,此时类似document.body.appendChild(proxy)的操作会触发类型错误(TypeError)。
现在我们继续来讨论一个让代理充满魔力的功能:句柄对象。
句柄对象的方法可以覆写任意代理的内部方法。
举个例子,你可以定义一个handler.set()方法来拦截所有给对象属性赋值的行为:
var target = {};
var handler = {
set: function (target, key, value, receiver) {
throw new Error("请不要为这个对象设置属性。");
}
};
var proxy = new Proxy(target, handler);
> proxy.name = "angelina";
Error: 请不要为这个对象设置属性。
句柄方法的完整列表可以在MDN有关代理的页面上找到,一共有14种方法,与ES6中定义的14中内部方法一致。
所有句柄方法都是可选的,没被句柄拦截的内部方法会直接指向目标,与我们之前看到的别无二致。
到目前为止,我们对于代理的了解程度足够尝试去做一些奇怪的事情,实现一些不借助代理根本无法实现的功能。
我们的第一个实践,创建一个Tree()函数来实现以下特性:
> var tree = Tree();
> tree
{ }
> tree.branch1.branch2.twig = "green";
> tree
{ branch1: { branch2: { twig: "green" } } }
> tree.branch1.branch3.twig = "yellow";
{ branch1: { branch2: { twig: "green" },
branch3: { twig: "yellow" }}}
请注意,当我们需要时,所有中间对象branch1、branch2和branch3都可以自动创建。这固然很方便,但是如何实现呢?
在这之前,没有可以实现这种特性的方法,但是通过代理,我们只用寥寥几行就可以轻松实现,然后只需要接入tree.[[Get]]()就可以。如果你喜欢挑战,在继续阅读前可以尝试自己实现。
这里是我的解决方案:
function Tree() {
return new Proxy({}, handler);
}
var handler = {
get: function (target, key, receiver) {
if (!(key in target)) {
target[key] = Tree(); // 自动创建一个子树
}
return Reflect.get(target, key, receiver);
}
};
注意最后的Reflect.get()调用,在代理句柄方法中有一个极其常见的需求:只执行委托给目标的默认行为。所以ES6定义了一个新的反射(Reflect)对象,在其上有14种方法,你可以用它来实现这一需求。
我想我可能传达给你们一个错误的印象,也就是代理易于使用。接下来的这个示例可能会让你稍感困顿。
这一次我们的赋值语句更复杂:我们需要实现一个函数,readOnlyView(object),它可以接受任何对象作为参数,并返回一个与此对象行为一致的代理,该代理不可被变更,就像这样:
> var newMath = readOnlyView(Math);
> newMath.min(54, 40);
40
> newMath.max = Math.min;
Error: can't modify read-only view
> delete newMath.sin;
Error: can't modify read-only view
即使我们不会阻断内部方法的行为,但仍然要对其进行干预,所以第一步是拦截可能修改目标对象的五种内部方法。
function NOPE() {
throw new Error("can't modify read-only view");
}
var handler = {
// 覆写所有五种可变方法。
set: NOPE,
defineProperty: NOPE,
deleteProperty: NOPE,
dd preventExtensions: NOPE,
setPrototypeOf: NOPE
};
function readOnlyView(target) {
return new Proxy(target, handler);
}
这段代码可以正常运行,它借助只读视图阻止了赋值、属性定义等过程。
最大的问题是类似[[Get]]的一些方法可能仍然返回可变对象,所以即使一些对象x是只读视图,x.prop可能是可变的!这是一个巨大的漏洞。
我们需要添加一个handler.get()方法来堵上漏洞:
var handler = {
...
// 在只读视图中包裹其它结果。
get: function (target, key, receiver) {
// 从执行默认行为开始。
var result = Reflect.get(target, key, receiver);
// 确保返回一个不可变对象!
if (Object(result) === result) {
// result是一个对象。
return readOnlyView(result);
}
// result是一个原始原始类型,所以已经具备不可变的性质。
return result;
},
...
};
这仍然不够,getPrototypeOf和getOwnPropertyDescriptor这两个方法也需要进行同样的处理。
然而还有更多问题,当通过这种代理调用getter或方法时,传递给getter或方法的this的值通常是代理自身。但是正如我们之前所见,有时代理无法通过访问器和方法执行的类型检查。在这里用目标对象代替代理更好一些。聪明的小伙伴,你知道如何解决这个问题么?
由此可见,创建代理非常简单,但是创建一个具有直观行为的代理相当困难。
不变性的规则非常复杂,在此不展开详述,但是如果你看到类似“proxy can't report a non-existent property as non-configurable”这样的错误信息,就可以考虑从不变性的角度解决问题,最可能的补救方法是改变代理报告本身,或者在运行时改变目标对象来反射代理的报告指向。
我记得我们之前的见解是:“对象是属性的集合。”
我不喜欢这个定义,即使给定义叠加原型和可调用能力也不会让我改变看法。我认为“集合(collection)”这个词太危险了,不适合用作对象的定义。对象的句柄方法可以做任何事情,它们也可以返回随机结果。
ECMAScript标准委员会针对这个问题开展了许多研究,搞清楚了对象能做的事情,将那些方法进行标准化,并将虚拟化技术作为每个人都能使用的一等特性添加到语言的新标准中,为前端开发领域拓展了无限可能。
完善后的对象几乎可以表示任何事物。
对象是什么?可能现在最贴切的答案需要用12个内部方法进行定义:对象是在JS程序中拥有[[Get]]、[[Set]]等操作的实体。
我不太确定我们是否比之前更了解对象,但是我们绝对做了许多惊艳的事情,是的,我们实现了旧版JS根本做不到的功能。
不!在Web平台上无论如何都不行。目前只有Firefox和微软的Edge支持代理,而且还没有支持这一特性polyfill。
如果你想在Node.js或io.js环境中使用代理,首先你需要添加名为harmony-reflect的polyfill,然后在执行时启用一个非默认的选项(--harmony_proxies),这样就可以暂时使用V8中实现的老版本代理规范。
放轻松,让我们一起来做试验吧!为每一个对象创建成千上万个相似的副本镜像却不能调试?现在就解放自己!不过目前来看,请不要将欠考虑的有关代理的代码泄露到产品中,这非常危险。
代理特性在2010年由Andreas Gal首先实现,由Blake Kaplan进行代码审查。标准委员会后来完全重新设计了这个特性。Eddy Bruel在2012年实现了新标准。
我实现了反射(Reflect)特性,由Jeff Walden进行代码审查。Firefox Nightly已经支持除Reflect.enumerate()外的所有特性