今天,我们来了解下 linux 系统的革命性通用执行引擎-eBPF,之所以聊着玩意,因为它确实牛逼,作为一项底层技术,在现在的云原生生态领域中起着举足轻重的作用。截至目前,业界使用范围最广的 K8S CNI 网络方案 Calico 已宣布支持 eBPF,而作为第一个实现了Kube-Proxy 所有功能的 K8S 网络方案——Cilium 也是基于 eBPF 技术。因此,只有了解其底层机制,才能有助于更好、更易地融入容器生态中。
作为一种颠覆性技术,eBPF 最早出现在 3.18 内核中,eBPF 新的设计针对现代硬件进行了优化,所以 eBPF 生成的指令集比旧的 BPF 解释器生成的机器码执行得更快。扩展版本也增加了虚拟机中的寄存器数量,将原有的 2 个 32 位寄存器增加到 10 个 64 位寄存器。由于寄存器数量和宽度的增加,开发人员可以使用函数参数自由交换更多的信息,编写更复杂的程序。总之,这些改进使得 eBPF 版本的速度比原来的 BPF 提高了 4 倍。
基于原本的想法,eBPF 实现的最初目标是优化处理网络过滤器的内部 BPF 指令集。然而,作为 BPF 技术的转折点,eBPF 已经开始扩展至用户空间。使得 eBPF 不再局限于网络栈,已经成为内核顶级的子系统。eBPF 程序架构强调安全性和稳定性,看上去更像内核模块,但与内核模块不同,eBPF 程序不需要重新编译内核,并且可以确保 eBPF 程序运行完成,而不会造成系统的崩溃。
具体参考如下示意图:
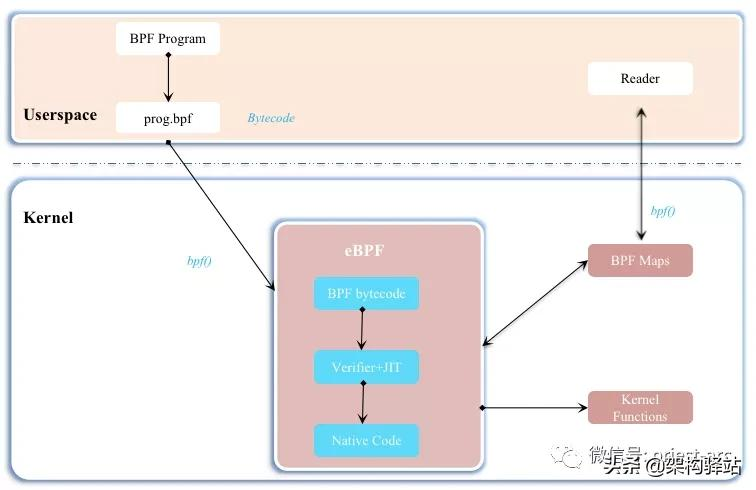
eBPF 是一套通用执行引擎,提供了可基于系统或程序事件高效安全执行特定代码的通用能力,通用能力的使用者不再局限于内核开发者,除此之外,eBPF 可由执行字节码指令、存储对象和 Helper 帮助函数组成,字节码指令在内核执行前必须通过 BPF 验证器 Verfier 的验证,同时在启用 BPF JIT 模式的内核中,会直接将字节码指令转成内核可执行的本地指令运行。
同时,eBPF 也逐渐在观测(跟踪、性能调优等)、安全和网络等领域发挥重要的角色。Facebook、NetFlix 、CloudFlare 等知名互联网公司内部广泛采用基于 eBPF 技术的各种程序用于性能分析、问题排查、负载均衡、DDoS 攻击预防等等,据相关信息显示,在 Facebook 的机器上内置一系列基于 eBPF 的相关工具集。
相对于系统的性能分析和观测,eBPF 技术在网络技术中的表现,更为抢眼,BPF 技术与 XDP(eXpress Data Path) 和 TC(Traffic Control) 组合可以实现功能更加强大的网络功能,更可为 SDN 软件定义网络提供基础支撑。XDP 只作用与网络包的 Ingress 层面,BPF 钩子位于网络驱动中尽可能早的位置,无需进行原始包的复制就可以实现最佳的数据包处理性能,挂载的 BPF 程序是运行过滤的理想选择,可用于丢弃恶意或非预期的流量、进行 DDOS 攻击保护等场景;而 TC Ingress 比 XDP 技术处于更高层次的位置,BPF 程序在 L3 层之前运行,可以访问到与数据包相关的大部分元数据,是本地节点处理的理想的地方,可以用于流量监控或者 L3/L4 的端点策略控制,同时配合 TC egress 则可实现对于容器环境下更高维度和级别的网络结构。关于 XDP 技术架构,可参考如下结构示意图:
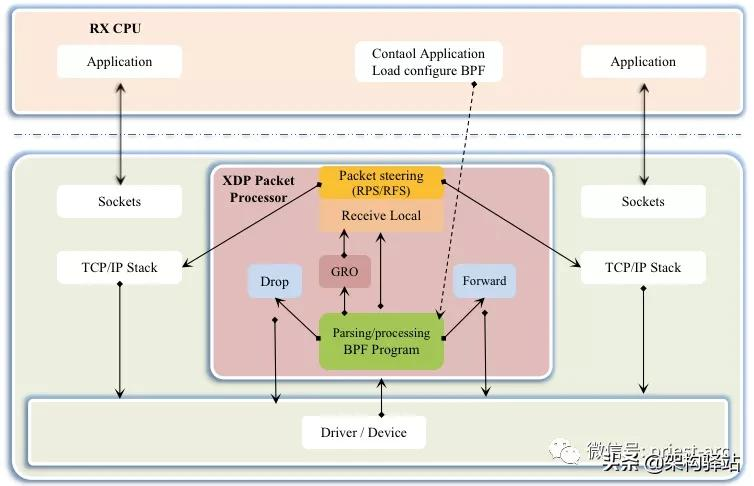
基于 Linux 系统生态体系,eBPF 有着得天独厚的优势,高效、生产安全且内核中内置,特别的可以在内核中完成数据分析聚合比如直方图,与将数据发送到用户空间分析聚合相比,能够节省大量的数据复制传递带来的 CPU 消耗。在解析 eBPF 之前,首先,我们先看下BPF 架构示意图,具体如下所示:
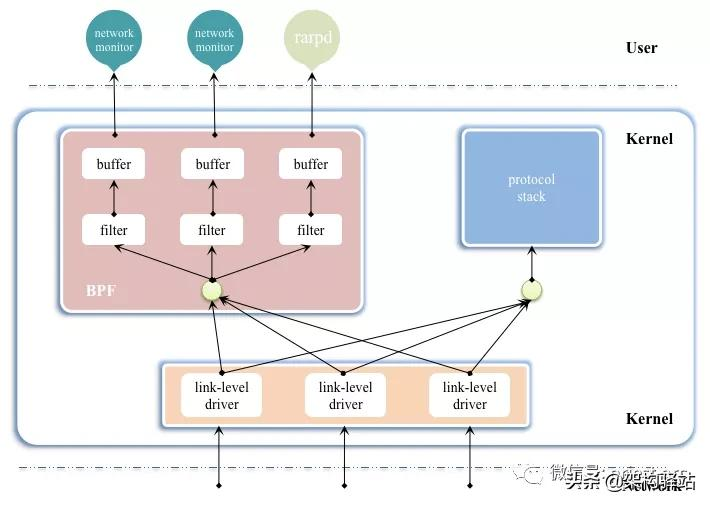
接下来基于上述架构图,我们可以清晰的看到,BPF 主要工作在内核层,其本质是类 Unix 系统上数据链路层的一种原始接口,提供原始链路层封包的收发。BPF 在数据包过滤上引入了两大革新:
基于这些巨大的改进,目前,几乎所有的 (类)Unix 系统都选择采用 BPF 作为网络数据包过滤技术,直到今天,许多 Unix 内核的派生系统中(包括 Linux 内核)仍基于此实现方式。举个简单的示例,Linux 操作系统上的 Tcpdump 底层采用的就是 BPF 作为包过滤技术。
接下来,我们再了解下 eBPF 的整体架构,具体如下图所示:
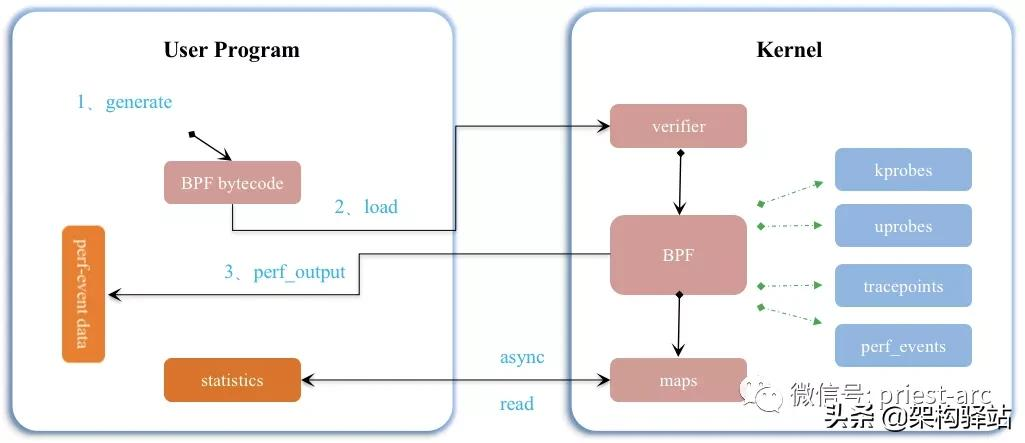
基于上述架构图,我们可以看到,整个 eBPF 主要分为 2 部分组件:User Program (用户空间程序)和 Kernel (内核程序)。针对两部分组件,简要介绍如下:
User Program (用户空间程序):负责加载 BPF 字节码至内核,基于特殊场景需求,也可能需要负责读取内核回传的统计信息或者事件详情。
Kernel (内核程序):内核中的 BPF 字节码负责在内核中执行特定事件,基于特定场景需要,也会将执行的结果通过 Maps 或者 Perf-Event 事件发送至用户空间。
在此架构参考示意图中,用户空间程序与内核 BPF 字节码程序可以基于 Map 结构实现双向通信,这为内核中运行的 BPF 字节码程序提供了更加灵活的控制。
我们再看下 User Program (用户空间程序)与 Kernel (内核程序)的 BPF 字节码交互的流程,具体如下所示:
1、在User Program (用户空间程序)中,基于LLVM 或者 GCC 工具将编写的 BPF 代码程序编译成 BPF 字节码
2、使用加载程序 Loader 将字节码加载至内核,内核使用验证器(Verfier) 组件保证执行字节码的安全性,以避免对内核造成灾难,在确认字节码安全后将其加载对应的内核模块执行;BPF 观测技术相关的程序类型可能是
Kprobes/Uprobes/Tracepoint/Perf_events 中的一个或多个。
针对 BPF 相关的程序类型进行简要解析,具体如下:
Kprobes:实现内核中动态跟踪。Kprobes 可以跟踪到 Linux 内核中的导出函数入口或返回点,但是不是稳定 ABI 接口,可能会因为内核版本变化导致,导致跟踪失效。
Uprobes:用户级别的动态跟踪。与 Kprobes 类似,只是跟踪用户程序中的函数。
Tracepoints:内核中静态跟踪。tracepoints 是内核开发人员维护的跟踪点,能够提供稳定的 ABI 接口,但是由于是研发人员维护,数量和场景可能受限。
Perf_events:定时采样和 PMC。
3、内核中运行的 BPF 字节码程序可以使用两种方式将测量数据回传至用户空间,具体,Maps 方式可用于将内核中实现的统计摘要信息(比如测量延迟、堆栈信息)等回传至用户空间;Perf-event 则用于将内核采集的事件实时发送至用户空间,用户空间程序实时读取分析。
从本质上来讲,eBPF 催生了一种全新的软件开发方式。基于这种方式,我们不仅能够对内核行为进行编程,而且依据场景需求还能编写跨多个子系统的处理逻辑,而传统上这些子系统是完全独立、 无法用一套逻辑来处理的。
当前,市面上eBPF 相关的知名的开源项目包括但不限于以下:
1、Facebook 高性能 4 层负载均衡器 Katran。
2、Cilium 为下一代微服务 ServiceMesh 所打造的具备 API 感知和安全高效的容器网络方案,底层主要使用 XDP 和 TC 等相关技术。
3、CloudFlare 公司开源的 eBPF Exporter 和 bpf-tools:eBPF Exporter 将 eBPF 技术与监控 Prometheus 紧密结合起来,而bpf-tools 可用于网络问题分析和排查。
4、IO Visor 项目开源的 BCC、 BPFTrace 和 Kubectl-Trace:BCC 提供了更高阶的抽象,可以让用户采用 Python、C++ 和 Lua 等高级语言快速开发 BPF 程序;BPFTrace 采用类似于 awk 语言快速编写 eBPF 程序;Kubectl-Trace 则提供了在 kubernetes 集群中使用 BPF 程序调试的方便操作。
由于 eBPF 还在快速发展期,内核中的功能也日趋增强及完善,因此,在实际的业务场景中,我们一般推荐基于 Linux 4.4+ (4.9 以上效能会更佳) 内核的来使用 eBPF。部分 Linux Event 和 BPF 版本支持见下图:
除上述较为知名的 eBPF 相关的开源项目外,还有越来越多的新兴项目如雨后脆笋一样开始蓬勃发展,并逐步在各种社区布局、开发以及优化完善,成为一股暖流,冲向广阔的市场。
接下来,我们针对 eBPF 所涉及的各方面进行简要解析,主要从网络、安全、性能追踪以及观测及监控等4个维度进行,具体如下所示。
网络
其实,刚才前面针对网络这部分已经有所描述,现在对其进行简要概括,具体,eBPF 的两大特色:可编程和高性能,使它能满足所有的网络包处理需求。可编程意味着无需离开内核中的包处理上下文,就能添加额外的协议解析器或任何转发逻辑, 以满足不断变化的需求。高性能的 JIT 编译器使 eBPF 程序能达到几乎与原生编译的内核态代码一样的执行性能。
安全
eBPF 能够观测和理解所有的系统调用的能力,以及在 Packet 层和 Socket 层审视所有的网络操作的能力,基于此两者相结合,为系统安全提供了革命性的新思路。在此革命未发生之前,传统模式是基于系统调用过滤、网络层过滤和进程上下文跟踪是在完全独立的系统中完成的,而 eBPF 的出现则统一了可观测性和各层面的控制能力,使得我们有更加丰富的上下文和更精细的控制能力, 因而能创建更加安全的系统。
性能追踪
eBPF 程序能够加载到 Trace points、内核及用户空间应用程序中的 Probe points, 这种能力使我们对应用程序的运行时行为(Runtime Behavior)和系统本身 (System Itself)提供了史无前例的可观测性。应用端和系统端的这种观测能力相结合, 能在排查系统性能问题时提供强大的能力和独特的信息。BPF 使用了很多高级数据结构, 因此能非常高效地导出有意义的可观测数据,而不是像很多同类系统一样导出海量的原始采样数据。
观测及监控
相比于操作系统提供的静态计数器(Counters、Gauges),eBPF 能在内核中收集和聚合自定义 Metric, 并能从不同数据源来生成可观测数据。这既扩展了可观测性的深度,也显著减少了整体系统开销, 因为现在可以选择只收集需要的数据,并且后者是直方图或类似的格式,而非原始采样数据。
上面讲述了 eBPF 的相关特性以及优点,最后,我们再了解下在基于当前的技术以及业务场景下,eBPF 应用的局限性,具体如下:
1、现有的环境下,eBPF 程序不能调用任意的内核参数,只限于内核模块中列出的 BPF Helper 函数。
2、eBPF 字节码大小最初被限制为 4096 条指令,截止到内核 Linux 5.8 版本, 当前已将放宽至 100 万指令(
BPF_COMPLEXITY_LIMIT_INSNS),可参考源码所示:include/linux/bpf.h,对于无权限的BPF程序,仍然保留 4096 条限制 ( BPF_MAXINSNS );新版本的 eBPF 也支持了多个 eBPF 程序级联调用,虽然传递信息存在某些限制,但是可以通过组合实现更加强大的功能。
3、eBPF 堆栈大小被限制在 MAX_BPF_STACK,截止到内核 Linux 5.8 版本,被设置为 512;可参考源码所示: include/linux/filter.h,这个限制特别是在栈上存储多个字符串缓冲区时:一个char[256]缓冲区会消耗这个栈的一半。目前没有计划增加这个限制,解决方法是改用 bpf 映射存储,它实际上是无限的。
4、eBPF 程序不允许包含无法到达的指令,防止加载无效代码,延迟程序的终止。
5、eBPF 程序中循环次数限制且必须在有限时间内结束,这主要是用来防止在 kprobes 中插入任意的循环,导致锁住整个系统;解决办法包括展开循环,并为需要循环的常见用途添加辅助函数。Linux 5.3 在 BPF 中包含了对有界循环的支持,它有一个可验证的运行时间上限。
综上所述,虽然 eBPF 技术在当前的环境下影响力强大,但是为了保证内核的处理安全和及时响应,内核中的 eBPF 技术也被进行着诸多的限制,或许,随着技术的发展和内核演进,基于 eBPF,我们可能会找出一个更为性价比的综合解决方案。
- EOF -