理解TCP滑动窗口是如何工作的,对于理解TCP的其他知识是至关重要的。
相比于更为简单,同为传输层协议的UDP而言,TCP提供了对传输数据的质量保证。
在可靠性上,TCP确保传输的数据不丢失、不重复,也不会产生乱序。
同时,TCP还提供了流量控制,用于控制数据发送的速度,防止较快主机导致较慢主机的缓冲区溢出。
接下来,从不可靠的协议开始说起,看看TCP面向流的滑动窗口机制是如何演化而来的。
对于不可靠的协议(例如IP、UDP),当数据发出去之后,可能到达目的地,也可能丢失。
如果没有提供消息反馈的机制,那么发送方将无法获知数据是否已成功的送达目的地,因而也无法对丢失的数据进行重传。
没有消息反馈机制,是造成传输不可靠,没有流控的一个主要原因。

为了能够在一个不可靠协议的基础之上,进行可靠的数据传输,引入了消息反馈机制。
发送方发送一条信息,当接收方收到数据之后,给发送方返回一个接收成功的反馈信息。
简单的实现流程如下:
但是这个简单的机制,可能存在2个问题:
以上2种情况,都有可能导致主机A一直处于等待确认消息的状态,但却永远也等不到。
为了解决这个问题,当主机A发送一条消息之后,可以同时启动一个计时器。这个计时器的时间要足够长,让消息能够送达主机B,同时让确认消息也能够返回给主机A。
如果在确认消息到达主机A之前,计时器超时了。那么,主机A会认为发送消息的过程中遇到了问题(可能是丢失了,或者网络堵塞导致包延迟),于是就重传该消息。
由于这种对消息的确认机制,既包含了对消息已收到的确认应答,也包含了发生超时后对消息的重传,因此被称为支持重传的确认机制(PAR,Positive Acknowledgment with Retransmission)。

基于PAR机制,能够给数据传输提供基本的可靠性保证。
但PAR机制存在一个缺点,就是在任何时候,只能有一条消息是未被确认的。这会使得系统变得非常慢,因为后续消息的发送都得等待前一条消息的确认。
PAR机制比较适用于传输少量数据,或者交互不是很频繁的协议。由于PAR传输效率低下,因此也不适用于像TCP这样的协议。
为了解决传输效率低下的问题,引入了消息标识。
当发送方发送消息的时候,为这个消息增加一个唯一标识。接收方在收到消息之后,返回的确认消息也带上该消息标识。
这样,发送方就可以针对不同的消息使用不同的标识。发送方可以同时发送多条消息,在收到确认消息之后,只要根据消息标识进行匹配,确认对应的消息即可。
以上,只是从发送方的角度,解决了发送方的发送速率问题(在任何时候,只能有一条消息是未被确认的)。
我们再换个角度,原来是发送一个消息,接收方处理完,返回确认消息后,等待下一条消息。这个过程,对于接收方来说,并不会存在什么问题。
在引入消息标识之后,发送方可以同时发送多条消息了。但如果发送过快,接收方可能由于处理不过来,被压垮了。
因此,对于接收方来说,需要保证在自己能够正常接收处理数据的情况下,通过一种机制,来通知发送方尽量不要发送得太快,发送的数据尽量按照自己的处理能力来。
比较容易想到的,就是在接收方返回确认消息的时候,将接收方的发送限制信息带上,传递给发送方。
发送方在收到确认消息中的发送限制字段时,就可以按照接收方的要求来控制自己的发送速率。
有了这个发送限制,接收方就可以根据自己的实际负载情况,进行动态反馈以调整发送速率,最优化发送性能。
增加了消息标识和发送限制之后,可以认为是PAR机制的一个增强版。
对于数据的传输,现在可以提供可靠性、效率和基本的数据流控了。

在增加了消息标识和发送限制之后,整个消息的发送和确认过程,已经较为完善了。
但从传输的"数据"的角度来看,前面我们讲的,其实都是面向消息的。也就是说,发送和确认都是以消息为单位。
而实际上,TCP是面向字节流的,本身并没有消息的概念。TCP传输的数据,我们通常称之为报文段。具体如何识别并组装为一条完整的消息,是应用层的工作。
正因为如此,TCP是以字节为单位来处理数据流的。如果要对TCP传输的数据做标识,那就需要一个字节给一个标识。
这样一来,TCP每次就只能发送一个字节的数据,然后每次也只能确认一个字节的数据,这显然是不合理的。既浪费带宽,又降低了发送效率。
TCP的设计者确实也没有这么做,而是将数据划分为一个个数据段,每次可以发送一段数据。
对于每一段数据,使用一个序号来进行标识。每次确认数据的时候,也是确认一段数据而不是一个字节。
事实上,序号是报文段中数据字节的偏移量,表示数据字节的位置。
设想一个场景,主机A和主机B建立了一个新的连接:
所以,每台主机都需要跟踪哪些字节已经发送了,哪些字节还没有发送,哪些已经确认了。这个流程,和前面以消息为单位的发送限制机制很类似。
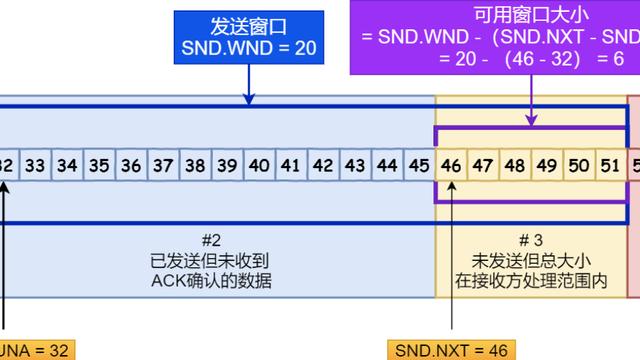
为此,TCP引入了缓冲区的概念,将发送方的缓冲区,划分为四个部分。

如图所示,发送方的缓冲区,被划分为四个部分,具体说明如下。
(Bytes Sent And Acknowledged)
对应于图中的 Category #1 部分,从第1到第31个字节,共31字节。
(Bytes Sent But Not Yet Acknowledged)
对应于图中的 Category #2 部分,从第32到第45个字节,共14字节。
(Bytes Not Yet Sent For Which Recipient Is Ready)
对应于图中的 Category #3 部分,从第46到第51个字节,共6字节。
这部分,代表发送方当前还可以发送的字节数,也是接收方当前还可以接收的字节数。
(Bytes Not Yet Sent For Which Recipient Is Not Ready)
对应于图中的 Category #4 部分,从第52到第95个字节,共44字节。
这部分字节,已经超出了接收方可以接收的最大窗口大小,因此暂不能发送。
黑色方框部分,表示发送窗口(Send Window),通常也简单的称为窗口。
发送窗口由两部分组成,对应于发送缓冲区的第二部分(Category #2,灰色方框内)和第三部分(Category #3,红色方框内)。
如图所示,发送窗口大小为20字节,第二、三部分分别为14字节和6字节。
窗口的左边缘为窗口的第1个字节(第32字节),右边缘为窗口的最后一个字节(第51字节)。
窗口的左边缘位置,决定了窗口的右边缘位置。左边缘是第一和第二部分的分界线,右边缘是第三和第四部分的分界线。
发送窗口的大小,决定了发送方可以同时发送的字节数,即未被接收方确认的字节数。
可用窗口(Usable Window),对应于缓冲区的第三部分(Category #3),即发送方当前仍可以发送的字节数。
如果在可用窗口内,发送了一些数据,将会改变发送窗口的位置,以及各部分的大小。
在上面的例子中,发送方的可用窗口为6字节。如果发送方将6个字节的数据发送出去,那么这6个字节将会变成未确认状态,合并到第二部分。
第二部分的范围变为,从第32到第51个字节,共20个字节。
而可用窗口,即窗口的第三部分,将变为0。这通常被称为零窗口(Zero Window)。
发送方需要等到有新的确认包到达,才会有可用的窗口可以继续发送数据。

接收方成功接收了数据之后,会给发送方返回一个确认包。在确认包中,包含了一个确认序号,用于通知发送方,在这个序号之前的数据都已经成功接收了。(确认序号的主要作用,是用来解决不丢包问题。通知接收端已经接收了哪些数据。)
假设,已发送未确认部分(第32到第45字节),是由4个TCP报文段进行传输的。每个报文段的范围分别为:
假设第一段、第二段和第四段,都已经成功的发送给接收方了。但是,第三段还没有送达。
那么,接收方将只能确认第一段和第二段,即第32到第36字节已经接收成功了。而对于第四段,还不能进行确认。
这是因为,TCP采用的是累积确认的机制,确认序号表示在这个序号之前(确认序号值减去1)的数据都已经被成功接收。
由于第三段接收方还没有收到,因此不能越过这部分,去确认第四段。否则,发送方会认为第三段也已经被成功的接收了。
(事实上,现在的TCP支持SACK机制,如果启用了,可以支持确认非连续的数据块。)

发送方在接收到确认包之后,窗口将会向右移动5个字节(第32到36共确认5个字节)。而第32到36字节,将会合并到第一部分,变为已发送已确认状态。
由于确认了5个字节,窗口右移之后,又新建了一个5个字节的可用窗口(第52到56字节)。
这个过程会在每次发送方接收到确认包时发生,然后窗口会进行相应的移动,以调整缓冲区各部分的大小。(滑动窗口很形象)

有了滑动窗口机制,就可以使用一个确认序号来确认一整段数据。这为TCP面向字节流的服务,提供了可靠性支持,并且不需要为每一个序号的确认而耗费时间。
发送方在发送了第52到56字节的数据之后,就停下来不再发送数据了。因为被卡在了第37到41字节上,这个范围的字节仍然没有返回确认包。
当然,和PAR机制类似的,TCP也支持超时检测和重传数据包。
因此,在计时器超时之后,发送方将重发已丢失的报文段,并希望这一次能够到达目的地。
非常不幸的是,TCP的累积确认机制,仍存在一个缺点,它并不会独立的确认每个报文段。
这意味着,TCP有可能会重复发送那些实际已经被接收方成功接收的报文段。
在我们的例子中,第四段(第42到45字节)已经被成功接收。但只要第三段没有被确认,当超时进行重发时,第四段也会被重发。