关于这两种写法的重要知识点摘要如下:
两者放置相同条件,之所以可能会导致结果集不同,就是因为优先级。on的优先级是高于where的。
首先明确两个概念:
在left join下,两者的区别:
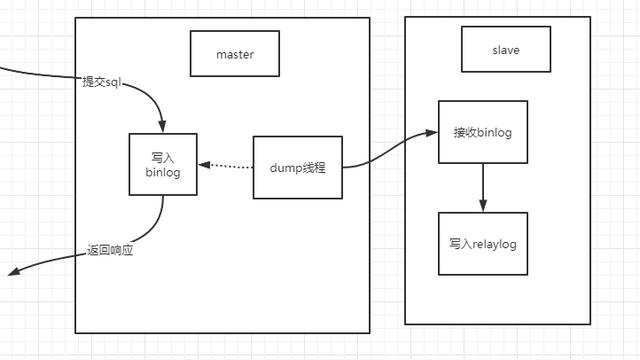
在多表查询时,on 比 where 更早起作用。系统首先根据各个表之间的联接条件,把多个表合成一个临时表后,再由 where 进行过滤,然后再计算,计算完后再由 having 进行过滤。由此可见,要想过滤条件起到正确的作用,首先要明白这个条件应该在什么时候起作用,然后再决定放在那里。
对于 join 参与的表的关联操作,如果需要不满足连接条件的行也在我们的查询范围内的话,我们就必需把连接条件放在 on 后面,而不能放在 where 后面,如果我们把连接条件放在了 where 后面,那么所有的left , right 等这些操作将不起任何作用,对于这种情况,它的效果就完全等同于 inner 连接。对于那些不影响选择行的条件,放在 on 或者 where 后面就可以。
记住:所有的连接条件都必需要放在 on 后面,不然前面的所有 left,right 关联将作为摆设,而不起任何作用。
第一步:新建2张表并插入数据
新建2张表:用户表(tb_user)、用户得分表(tb_score)

表 tb_user 和 tb_score 数据
第二步:执行查询语句
(1)执行 left-join-on-and 写法SQL
select u.name,u.age,s.score from tb_user u left join tb_score s on s.user_id=u.id and s.score<90 where u.age>20;
执行结果:

(2)执行 left-join-on-where 写法SQL
select u.name,u.age,s.score from tb_user u left join tb_score s on s.user_id=u.id where u.age>20 and s.score<90;
执行结果:

第一个sql的执行流程:首先找到 s 表的 score 小于90 的记录行(on s.user_id=u.id and s.score<90),然后找到 u 的数据(即使不符合 s 表的规则),生成临时表返回用户。
第二个sql的执行流程:首先生成临时表,然后执行 where 过滤 on s.score<90 不为真的结果集,最后返回给用户。
因为on会首先过滤掉不符合条件的行,然后才会进行其它运算,所以按理说on是最快的。
第三步:分析执行过程及结果
根据执行过程,从上述执行结果可以看出: