一、现象
最近项目的测试环境遇到一个主备同步的问题:
备库的同步线程停止了,无法同步主库的数据更改。
备库报错如下:
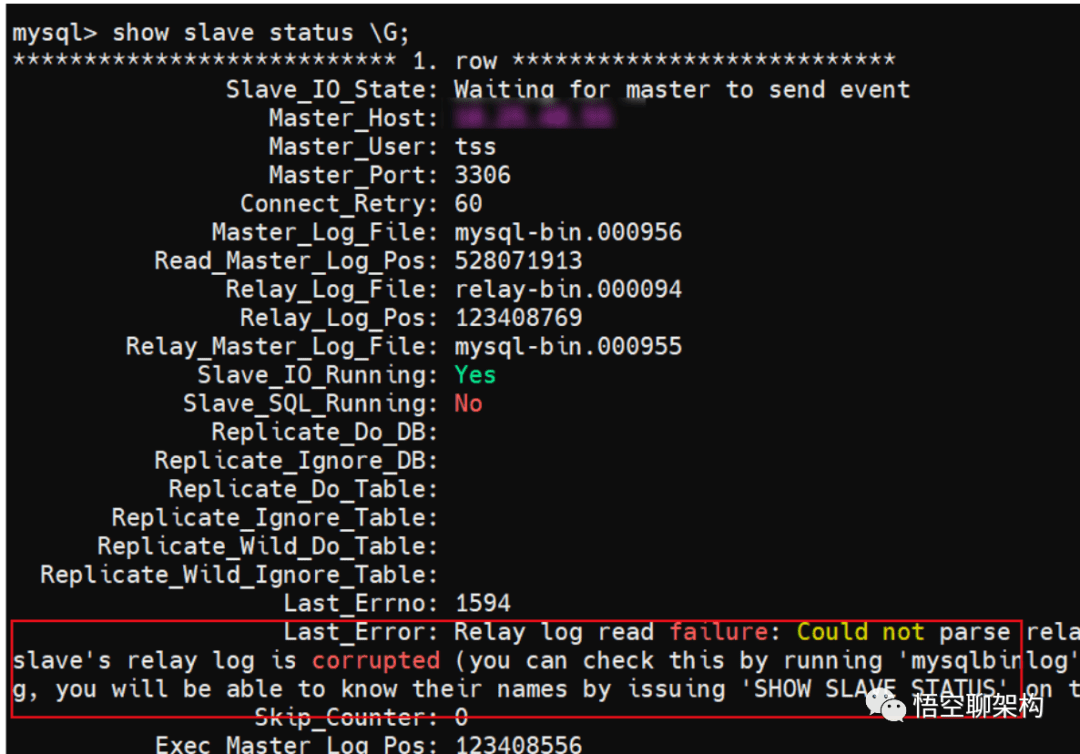 从库同步报错信息
从库同步报错信息
完整的错误信息:
Relay log read fAIlure: Could not parse relay log event entry. The possible reasons are: the master's binary log is corrupted (you can check this by running 'MySQLbinlog' on the binary log), the slave's relay log is corrupted (you can check this by running 'mysqlbinlog' on the relay log), a.NETwork problem, or a bug in the master's or slave's MySQL code. If you want to check the master's binary log or slave's relay log, you will be able to know their names by issuing 'SHOW SLAVE STATUS' on this slave.
上面的报错信息是什么意思呢?
翻译一下就是主库的 binlog 或者从库的 relay log 损坏了,造成这个问题的原因:
首先我们还是得复习下主从同步的原理才能更好地分析原因。
二、主从同步的原理
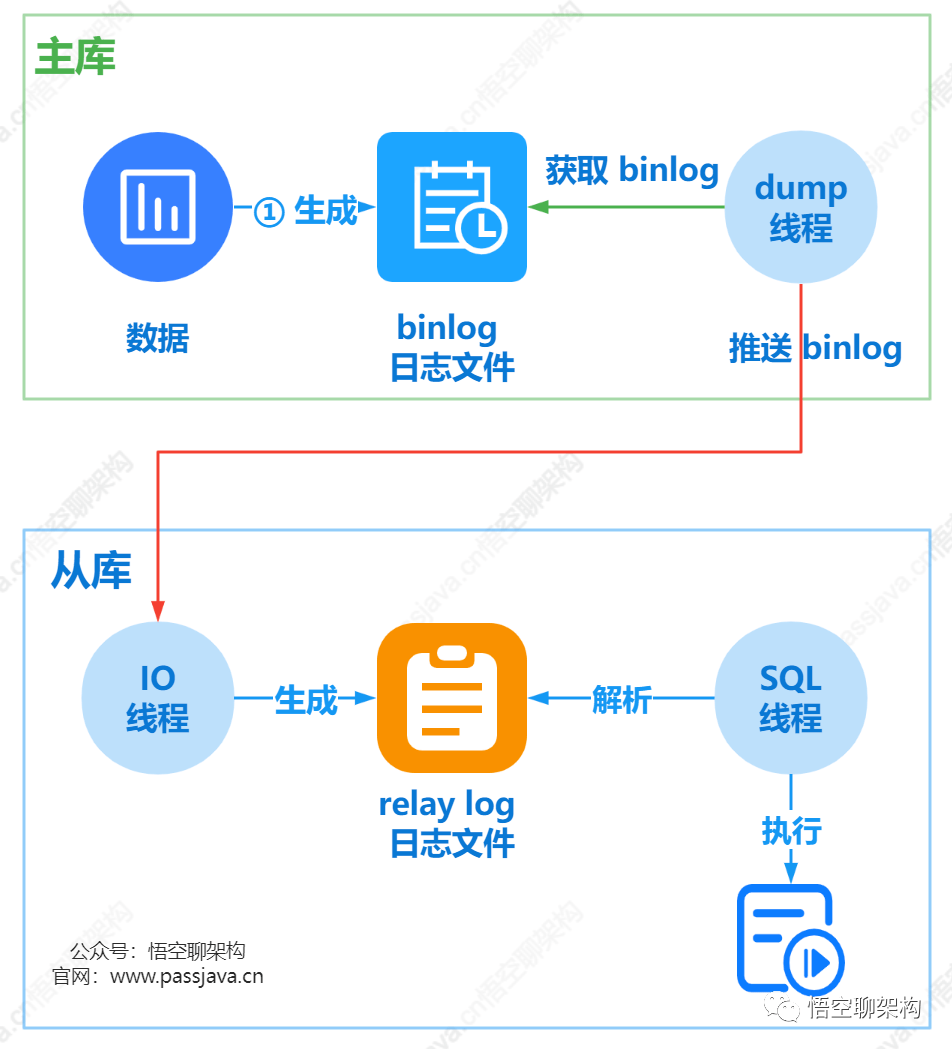 主从同步的原理
主从同步的原理
三、排查思路
1、分析从库的同步状态
我们可以打印下从库的同步状态,看到如下几个关键信息:
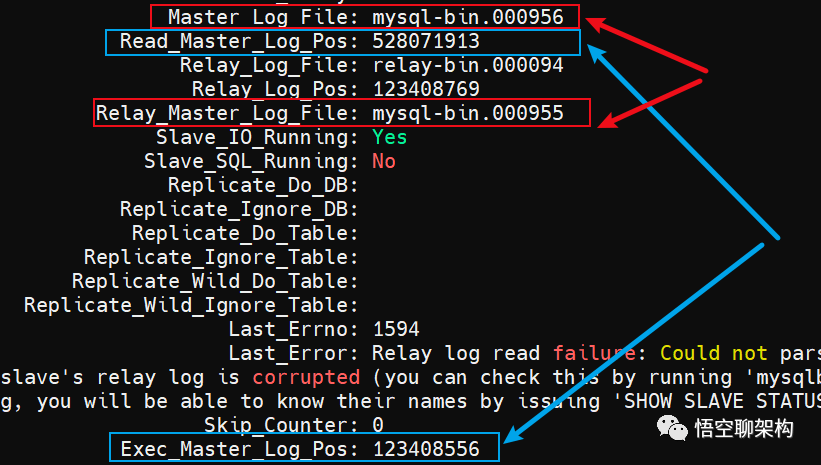 分析从库的同步状态
分析从库的同步状态
如果红色框起来的两个参数 Master_Log_File 和 Relay_Master_Log_File 相等,则说明从库读到的最新文件和主库上生成的文件相同,这里前者是 mysql-bin.000956,后者是 mysql-bin.000955,说明两者不相同,存在主从不同步。
如果蓝色框起来的两个参数 Read_Master_Log_Pos 和 Exec_Master_Log_Pos 相等,则说明从库读到的日志文件的位置和从库上执行日志文件的位置相同,这里不相等,说明主从不同步。
当上面两组参数都相等时,则说明主从同步正常,且没有延迟。只要有任意一组不相等,则说明主从不同步,可能是从库停止同步了,或者从库存在同步延迟。由于上面的 SQL 线程已经停止了,说明是从库同步出现问题了。
从库同步出现的问题在最开始的报错信息里面已经提到了,可能是网络问题导致,还有可能是 binlog 或 relay log 损坏。
2、重启万能大法
先通过重启来恢复从库的 SQL 线程试试看?重启方式就是两种:
这两种方式试了后,都不能恢复从库的 SQL 线程。
3、查看 binlog
再来看下 binlog 是否有损坏,在主库上通过这个命令打开 mysql-bin.000955 文件。
mysqlbinlog /var/lib/mysql/log/mysql-bin.000955
没有报错信息,如下图所示:
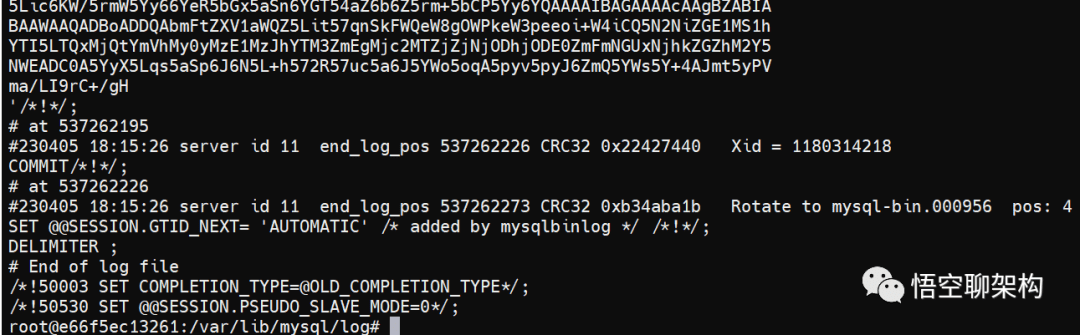 binlog 日志
binlog 日志
4、查看 relay log
看到从库同步的 Relay_Log_File 到 relay-bin.00094 就停止同步了,如下图所示,可能是这个文件损坏了。
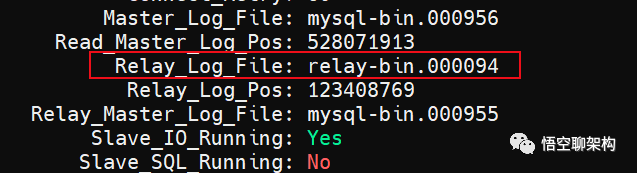 relay log 日志
relay log 日志
在从库上通过 mysqlbinlog 命令打开这个文件:
mysqlbinlog /var/lib/mysql/log/relay-bin.000094
可以看到有个报错信息:
ERROR: Error in Log_event::read_log_event(): 'read error', data_len: 7644, event_type: 31
ERROR: Could not read entry at offset 243899899: Error in log format or read error.
这段文字翻译过来就是读取错误,数据长度 7644,在读取偏移量为 243899899 的日志时发生了错误,可能是日志文件格式错误或是读取文件错误。
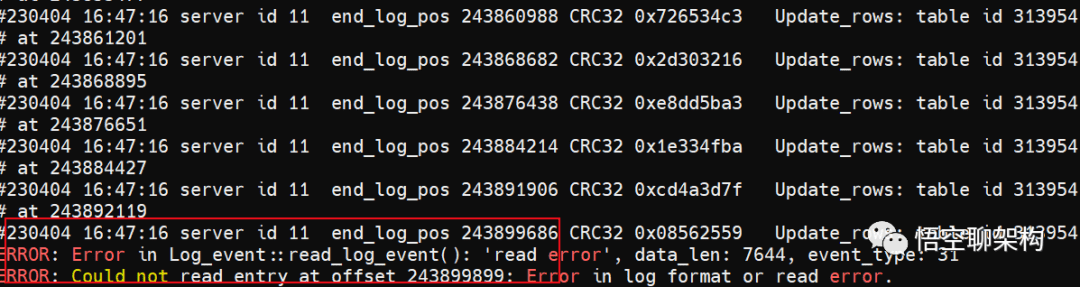 relay log 报错信息
relay log 报错信息
5、找原因
1)猜测事务日志太大
根据这个报错信息可以知道这个事务日志数据太长了,data_len: 7644,而导致读取错误。
而且上面还有很多 Update_rows 的操作。
猜测:会不会是主库执行了一个大事务,造成该事务生成的一条 binlog 日志太大了,从库生成的对应的一条 relay log 日志也很大, SQL 线程去解析这条 relay log 日志解析报错。
2)验证
到主库上查看下 binlog 日志里面有没有在那个时间点做特殊操作。
感觉快找到原因了。执行以下命令来查看:
mysqlbinlog File --stop-datetime=T --start-datetime=T
stop-datetime 指定为读取 relay log 报错的时刻 2023-04-04 16:47:16;
start-datetime 指定为读取 relay log 报错的时刻 2023-04-04 16:47:30。
发现并没有找到 Update_rows 的操作。继续把时间往后加一点,经过多次尝试,把时间锁定在了 2023-04-04 17:00:30~17:00:31。这 1s 内能找到 2023-04-04 16:47:16 的操作日志。
日志如下,这个命令会打印 N 多日志,直接把屏幕打满了!
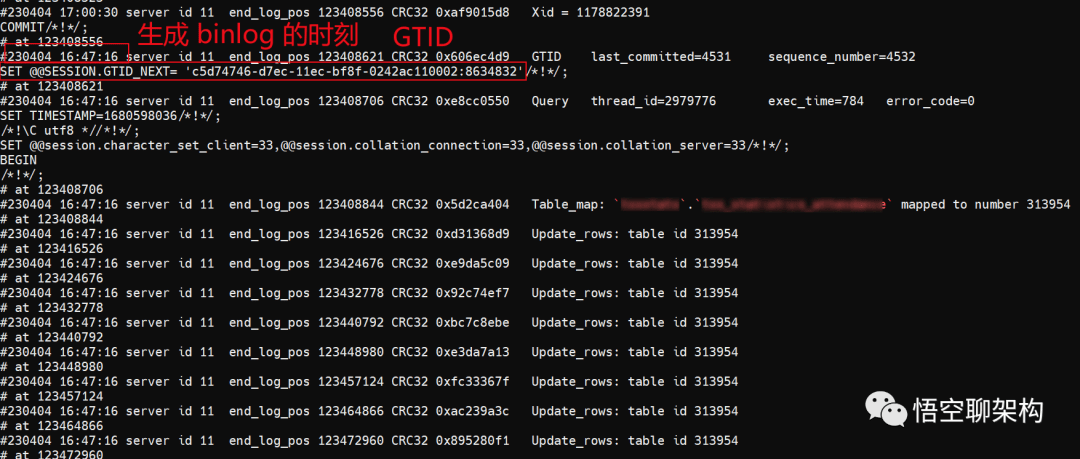
难道真的 binlog 对应的这条事务日志太大了吗?
存疑:2023-04-04 16:47:16 时刻对数据库中的表做了某个大事务的操作,造成该事务对应的这条 binlog 日志很大很大。生成的 relay log 也很大,SQL 线程解析 relay log 报错。
6、这是真相吗?
问了下熟悉这张表的同事,有没有在这个时刻做什么大事务操作。
同事看了下代码,发现有个批量插入的操作,一次执行 400 条,难道是 400 条太多了?这不应该是真正的原因,400 条也不多。
不经意间问了下这张表的数据量有多大,该同事在 4月4号 16:45:25 做了一个手动备份 xx_dance 表的操作,这张表有 25 万条数据。
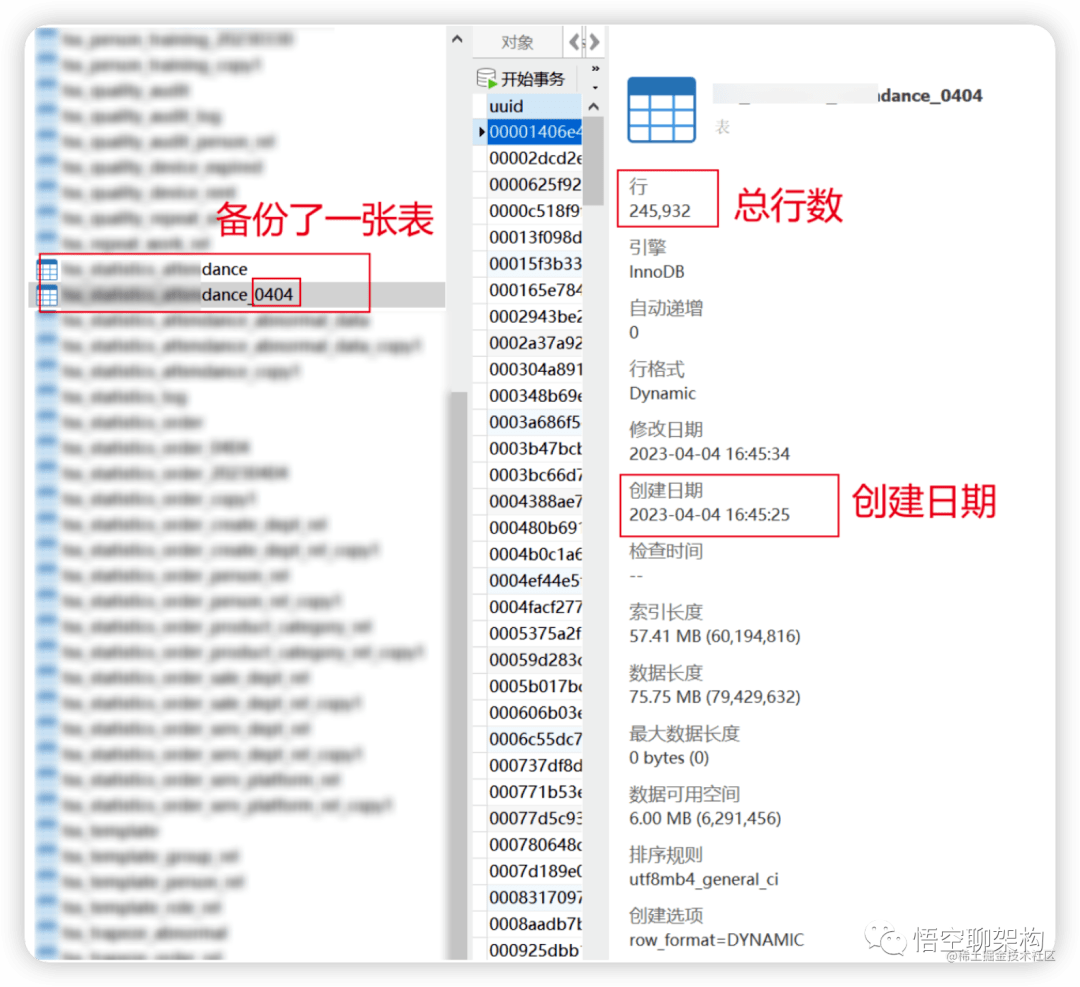 备份表 xx_dance_0404 的信息
备份表 xx_dance_0404 的信息
这个备份操作是在一个事务里面执行的,生成的一条 binlog 日志很大。
这里只是一个猜测,还未得到验证,文末会说明真正的原因。
如果真的是这样,那我可以先恢复从库的同步,备份表的操作在从库上其实不需要。
7、GTID
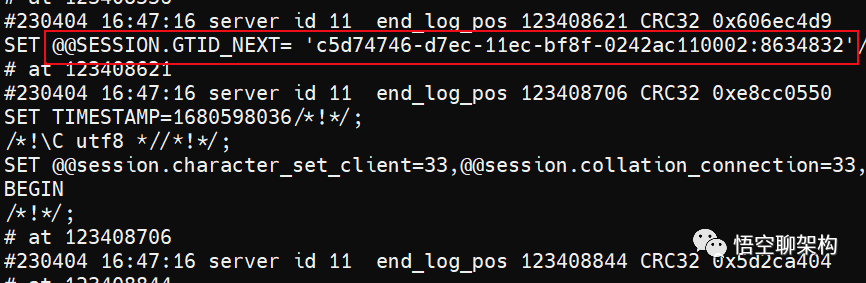
不知道细心的你是否有发现上面的 binlog 里面有一个GTID。
'c5d74746-d7ec-11ec-bf8f-0242ac110002:8634832
 binlog 中 GTID
binlog 中 GTID
记住 GTID 中的数字 8634832,后面恢复从库同步时要用到。
我们再来看下从库的状态,发现也有一个 GTID,如下图所示,值为 8634831,正好相差 1,感觉这两个 GTID 值之间有不可告人的秘密。
 从库的状态,GTID 集合
从库的状态,GTID 集合
那么从库 SQL 线程停止运行的原因就是卡在 8634832 这里了,我们可否跳过这个 GTID 呢?这里就需要了解 GTID 的原理了。
四、GTID 同步方式的原理
这里还是把主从同步采用 GTID 方式的流程拿出来看下,帮助大家快速回顾下,熟悉的同学可以跳过本节内容。
当从库设置完同步参数后,假定主库 A 的GTID 集合记为集合 x,从库 B 的 GTID 集合记为 y。
从库同步的逻辑如下:
 GTID 同步方式的原理
GTID 同步方式的原理
GTID 同步方案和位点同步的方案区别是:
五、恢复从库的同步
1、查看从库执行 GTID 的进度
在从库上执行 show slave status G 来查看 GTID 集合。
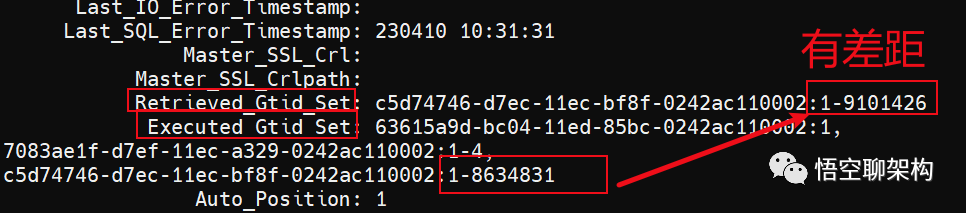
Retrieved_Gtid_Set 表示从库收到的所有日志的 GTID 集合。
Executed_Gtid_Set 表示从库已经执行完成的 GTID 集合。
如果 Executed_Gtid_Set 集合是包含Retrieved_Gtid_Set,则表示从库接收到的日志已经同步完成。
这里 Executed_Gtid_Set 的集合为 1-8634831,而 Retrieved_Gtid_Set 为 1-9101426,说明从库有些 GTID 是没有执行的。从库已经执行到了 8634831,下一个要执行的 GTID 为 8634832。
因为我们采用的同步方式是 GTID 方式,所以只要让从库跳过这个 GTID ,从下一个 GTID 开始同步就行。
带来的问题就是这个 GTID 对应的事务没有执行。因为报错的操作是从库备份一张大表,所以从库跳过这个备份操作也是可以接受的。
2、手动设置 GTID
1)重置从库进度
首先重置下从库同步的进度 reset slave,这条命令会把所有的 relog 给清理掉,重新启用一个新的 relay log文件。
stop slave;
reset slave;
重新开启同步后,主库会计算主库 GTID 集合和从库 GTID 的集合的差集,然后主库推送差集 binlog 给从库。
2)设置 GTID 为一个值
执行以下命令设置 GTID 为下一个值。
set gtid_next='c5d74746-d7ec-11ec-bf8f-0242ac110002:8634832';
begin;
commit;
set gtid_next=automatic;
start slave;
gtid_next 表示设置下一个 GTID = 8634832,这个值是在原来的 8634831 加 1。后面的 begin 和 commit 是提交了一个空事务,把这个 GTID 加到从库的 GTID 集合中。那么从库的 GTID 集合就变成了:
'c5d74746-d7ec-11ec-bf8f-0242ac110002:1-8634832';
3)查看当前 GTID 集合
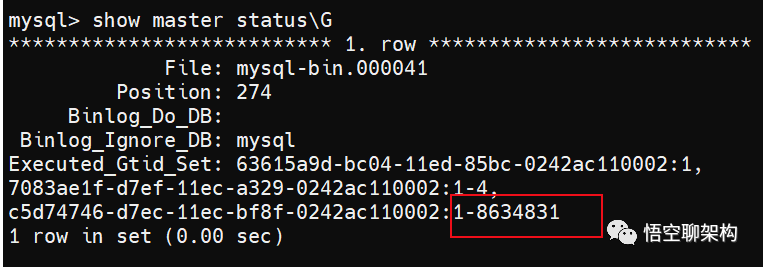
我们可以通过 show master statusG 命令来查看从库的 GTID 集合。下方截图是执行上述命令之前的。GTID集合为 1-8634831。另外 GTID 集合 为 1 和 GTID 集合为 1-4 的可以忽略,因为它们前面的 Master_UUID 不是当前主库的 uuid。
 show master statusG 的结果
show master statusG 的结果
也可以通过 show slave statusG 命令来查看 GTID 集合,结果也是一样的。
3、开启从库同步
再次启动从库的同步(start slave 命令),I/O 线程和 SQL 线程的状态都为 YES,说明启动成功了。
而且查看从库的同步状态时,观察到从库的同步是存在延迟的。通过观察这个字段 Seconds_Behind_Master 在不断减小,说明主从同步的延迟越来越小了。
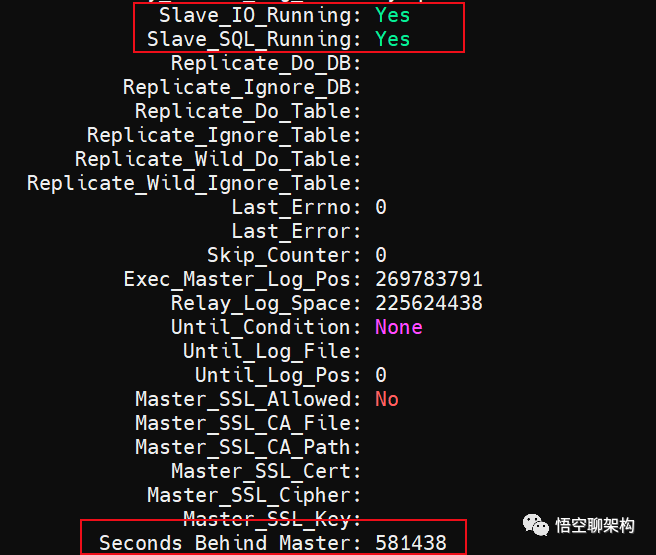 两个线程都是正常运行,主从同步延迟越来越小
两个线程都是正常运行,主从同步延迟越来越小
过一段时间后,执行的 GTID 等于收到的 GTID 集合,Seconds_Behind_Master = 0,说明主从完全同步了。
六、原因
上面的推测:备份大表造成 binlog 的一条日志太大,relay log 也跟着变大,SQL 线程无法正常解析。
但这是真相吗?
虽然从库重新开启了同步,且跳过了这条日志,但带来的是从库上就不会出现这个备用表 xx_dance_0404 。
但出现了两个奇怪的问题:
问题 1:从库开启同步后,居然出现了这个备份表 xx_dance_0404。不是跳过这个备份操作了吗?目前没想到原因。
问题 2:为了重现这个问题,我到主库上做了一个备份表的操作,表名为 xx_dance_0412,从库也同步了这个新的备份表 xx_dance_0412。而且 binlog 出现的日志现象也是一样的,对应的这条 binlog 日志也很大,但是从库同步正常。我又备份了一张 300 万的大表,依然没重现。
通过问题 2 可以说明上面的推测是错误的,备份大表并不会影响主从同步。
那么 relay log 报错的原因是什么?
只有一个原因了,即:relay log 文件真的是损坏的,从库的状态上也说明了原因,relay log is corrupted(损坏)。SQL 线程去解析 relay log 时报错了,导致 SQL 线程停止,从库不能正常执行同步。
小结:relay log 损坏了,导致从库的 SQL 线程解析 relay log 时出现异常。从库恢复方式是通过手动设置当时出错的 GTID 的下一个值,让从库不从主库同步这个 GTID,最后从库就能正常同步这个 GTID 之后的 binlog 了,后续 SQL 线程也能正常解析 relay log 了。
作者丨悟空聊架构
来源丨公众号:悟空聊架构(ID:PassJAVA666)