MySQL 采用插件化存储引擎,从这个角度,整体结构可以分为两层:
基于以上两层结构,MySQL 的锁也可以分为两大类。
server 层的锁,就是让我们头痛不已的元数据锁(MDL)。
存储引擎的锁,取决于各存储引擎的实现。
InnoDB 支持表锁、行锁、谓词锁(用于空间索引,我们不会介绍)。
表锁分为共享锁(S)、排他锁(X)、意向共享锁(IS)、意向排他锁(IX)、AUTO-INC 锁。
行锁分共享锁(S)、排他锁(X),以及有点特殊的插入意向锁(LOCK_INSERT_INTENTION)。
行级别共享锁(S)和排他锁(X)又都可以细分为三类:
接下来,我们就进入本文的主题,聊聊 InnoDB 的表锁。
顾名思义,共享锁指的是多个事务可以同时对同一个表加的锁,排他锁指的是同一时刻只有一个事务能对某个表加的锁。
如果事务 T 想要读取某个表的数据,同时允许其它事务读取这个表的数据,但是不允许其它事务改变这个表的数据,事务 T 可以对这个表加表级别的共享锁。
如果事务 T 想要改变(插入、更新、删除)某个表的数据,并且不允许其它任何事务读取或者改变(插入、更新、删除)这个表的数据,事务 T 可以对这个表加表级别的排他锁。
了解定义之后,我们再来看看怎么加表级别的共享锁和排他锁。
以给 t1 表加表级别的共享锁为例,先执行以下 SQL 加锁:
lock tables t1 read;
然后,执行以下 SQL 查看加锁结果:
select * from performance_schema.data_locks
where object_name = 't1'G
-- 加锁结果如下
0 rows in set
咦!lock tables 语句并没有给 t1 表加上表级别的共享锁,这是怎么回事?
这个问题代码里有说明:从 MySQL 4.1.9 开始,如果系统变量 autocommit 的值为 ON,lock tables 语句不会给表加表级别的共享锁或排他锁。
实际上,lock tables 语句是否给表加表级别的共享锁或排他锁,由 innodb_table_locks、autocommit 两个系统变量共同决定。
只有同时满足以下两个条件,lock tables 语句才会给表加表级别的共享锁或排他锁:
因为系统变量 innodb_table_locks 和 autocommit 的默认值都为 ON,所以前面执行的 lock tables 语句不会给 t1 表加表级别的共享锁。
我们先把系统变量 autocommit 的值修改为 OFF:
set autocommit = OFF;
show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | OFF |
+---------------+-------+
再执行一次 lock tables 语句:
lock tables t1 read;
然后查看加锁结果:
***************************[ 1. row ]***************************
ENGINE | INNODB
ENGINE_LOCK_ID | 4708798376:1415:4561418528
ENGINE_TRANSACTION_ID | 281479685509032
THREAD_ID | 53
EVENT_ID | 15
OBJECT_SCHEMA | test
OBJECT_NAME | t1
PARTITION_NAME | <null>
SUBPARTITION_NAME | <null>
INDEX_NAME | <null>
OBJECT_INSTANCE_BEGIN | 4561418528
LOCK_TYPE | TABLE
LOCK_MODE | S
LOCK_STATUS | GRANTED
LOCK_DATA | <null>
此时,我们可以看到 lock tables 语句给 t1 表加了表级别的共享锁。
看到这里,大家可能会有个疑问:autocommit = OFF 时,lock tables ... read 不给表加表级别的共享锁,怎么阻止其它事务改变表的数据?
答案是 MySQL 会给表加元数据锁。
不管系统变量 autocommit 的值是什么,我们执行 lock tables 语句之后,都可以看到 MySQL 给 t1 表加了元数据锁:
select * from performance_schema.metadata_locks
where object_name = 't1'G
***************************[ 1. row ]***************************
OBJECT_TYPE | TABLE
OBJECT_SCHEMA | test
OBJECT_NAME | t1
COLUMN_NAME | <null>
OBJECT_INSTANCE_BEGIN | 5143798864
LOCK_TYPE | SHARED_READ_ONLY
LOCK_DURATION | TRANSACTION
LOCK_STATUS | GRANTED
SOURCE | sql_parse.cc:6094
OWNER_THREAD_ID | 53
OWNER_EVENT_ID | 28
通过以上结果,我们可以看到 MySQL 给 t1 表加了类型为 SHARED_READ_ONLY 的元数据锁。
这个元数据锁限制了任何事务只能读取,不能改变(插入、更新、删除)t1 表的数据。
看到这里,大家可能会有另一个疑问:server 层的元数据锁,既然能实现表级别的共享锁和排他锁的功能,InnoDB 为什么还要支持表级别的共享锁和排他锁,这不是多此一举吗?
还真不是。
根据代码里的描述,DDL 语句修改某个表结构的过程中,虽然会加元数据锁保证其它事务不会读写这个表,但是有两种特殊场景只在 InnoDB 内部实现,不会加元数据锁。
这两种特殊场景如下:
为了保证 DDL 语句和上面两种场景同时操作同一个表时不会出现问题,它们都会给表加表级别的共享锁或排他锁。
所以,InnoDB 支持表级别的共享锁和排他锁是必要的。
通过前面的介绍,我们可以看到,InnoDB 表级别的共享锁和排他锁并不常用,因为元数据锁在大部分场景下能够代替它们。
由于有些特殊场景的存在,虽然不常用,但是 InnoDB 也不能没有表级别的共享锁和排他锁。
有了表级别的共享锁和排他锁,怎么又弄出来个意向共享锁和意向排他锁,它们之间到底是什么关系?
意向共享锁、意向排他锁,其实和表级别的共享锁、排他锁没什么关系,它们是用来和行级别的共享锁、排他锁配合使用的。
如果我们经常关注表的加锁情况,可能会有如下发现:
我们以第一种为例,来看看加锁情况:
begin;
select * from t1 where id = 10
lock in share mode;
-- 查看加锁情况
select
object_name, lock_type, lock_mode,
lock_status, lock_data
from performance_schema.data_locks
where object_name = 't1'G
***************************[ 1. row ]***************************
object_name | t1
lock_type | TABLE
lock_mode | IS
lock_status | GRANTED
lock_data | <null>
***************************[ 2. row ]***************************
object_name | t1
lock_type | RECORD
lock_mode | S,REC_NOT_GAP
lock_status | GRANTED
lock_data | 10
从以上加锁情况可以看到,InnoDB 除了给 t1 表中 id = 10 的记录加了行级别的共享锁,还给 t1 表加了表级别的意向共享锁。
说了这么多,意向共享锁、意向排他锁和行级别的共享锁、排他锁到底是怎么配合的?
我们先不正面回答这个问题,而是假装没有意向共享锁、意向排他锁,要怎么解决下面这个场景中的问题。
场景是这样的:
我们把系统变量 innodb_table_locks 设置为 ON,autocommit 设置为 OFF,然后执行 lock tables t1 read。
执行 lock tables 语句的过程中,InnoDB 会给 t1 表加表级别的共享锁,但是加锁之前,InnoDB 要确定没有事务正在或者将要改变(插入、更新、删除)t1 表的记录。
因为事务改变 t1 表的任何记录之前,都会给这些记录加行级别的排他锁。
插入记录有一点特殊,这里我们暂且忽略插入记录加锁的特殊性。
这么一来,InnoDB 要确定没有事务正在或者将要改变(插入、更新、删除)t1 表的记录,只需要确定没有事务给 t1 表中的记录加了行级别的排他锁就可以了。
问题来了:InnoDB 要怎么确定没有事务给 t1 表中某条或者某些记录加了行级别的排他锁?
有一个办法,就是遍历所有的记录锁,对于每个记录锁,都看看它锁定的是不是 t1 表的记录。如果是,再看看锁的类型是不是排他锁。
这个方法简单直接,但是有个问题,如果 InnoDB 中有非常多的记录锁,遍历所有记录锁消耗的时间就会很长。
显然,这个简单直接的方法不太靠谱。
此时,聪明如你,可能会想到另一个方案:采用登记制度,每个事务给 t1 表的记录加排他锁之前,先登记一下,表示它将要给 t1 表的记录加行级别的排他锁。
不管一个事务要给 t1 表的多少条记录加行级别的排他锁,只需要登记一次就行。
这样九九归一,原来要遍历 N 个表的所有行级别的锁,现在只需要看 N 个表的登记信息就行了,数量急剧减少,效率大幅提升。
采用登记制度之后,InnoDB 只需要看看登记本,就能确定有没有事务正在或者将要给 t1 表的记录加行级别的排他锁,也就能确定有没有事务正在或者将要改变(插入、更新、删除)t1 表的记录了。
前面大白话讲的登记制度,就是 InnoDB 加表级别的共享锁、排他锁之前,用来确定表中记录没有被加上行级别的共享锁、排他锁时使用的方案,也就是意向共享锁、意向排他锁。
事务对表中某条或者某些记录加行级别的共享锁、排他锁之前,都要先加对应的表级别的意向共享锁、意向排他锁。
所以,意向共享锁、意向排他锁可以分别看作行级别的共享锁、排他锁的登记本。
我们建表时,经常会把主键字段定义为整型,并且主键字段值还是一个递增的数字序列。
如果我们自己指定插入记录的主键字段值,需要保证插入记录的主键字段值,和表中已有记录的主键字段值不重复,否则插入记录会失败。
这么做,我们自己就比较麻烦了。
为了不麻烦我们自己,只好麻烦 MySQL 了。
于是,我们就经常使用 auto_increment 关键字把主键字段定义为自增字段。
插入记录时,我们就可以不指定主键字段值,而是让 MySQL 自动生成递增的主键字段值。
官方文档介绍:MySQL 并不限制只有主键索引或者唯一索引才能使用自增字段,非唯一索引也能使用自增字段,只是不推荐这么用。
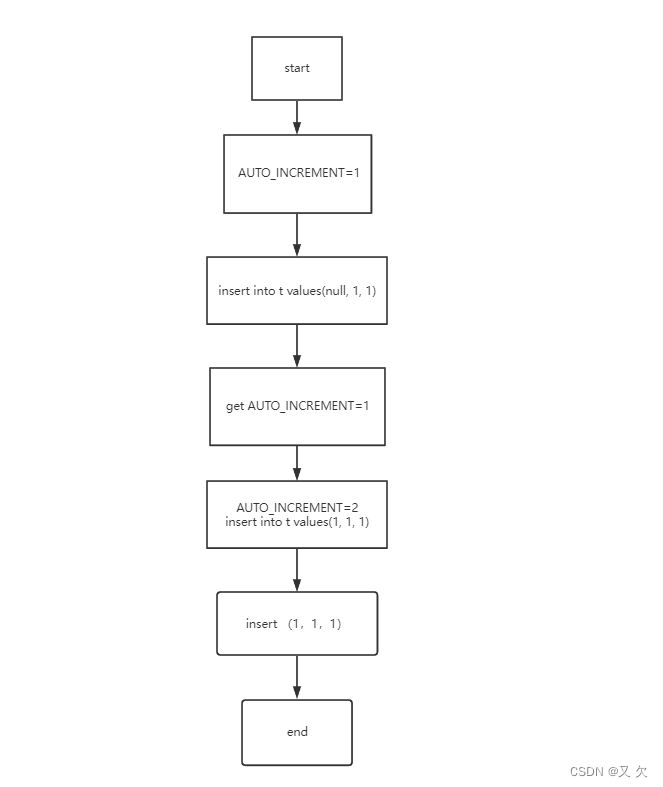
MySQL 怎么保证自增的主键字段值不重复呢?
答案就是加 AUTO-INC 锁。
AUTO-INC 锁有三种模式,由系统变量 innodb_autoinc_lock_mode 指定,枚举值为 0、1、2。
innodb_autoinc_lock_mode = 0,传统模式(traditional mode)。
引入系统变量 innodb_autoinc_lock_mode 之前,AUTO-INC 锁用的就是这种模式。
MySQL 8.0 保留这种模式,主要是为了兼容以前版本的逻辑,供用户需要时使用。
传统模式下,如果需要 MySQL 为插入记录生成自增字段值,生成之前,都需要给自增字段所属的表加上表级别的 AUTO-INC 锁。
传统模式的优点是:MySQL 为同一条 insert 语句插入多条记录生成的自增字段值是连续的,并且只要主从服务器上 insert 语句的执行顺序一致,主从服务器为同一条 insert 语句生成的自增字段值就是相同的,也就意味着基于语句的主从复制是安全的。
世事都有两面性,传统模式不只有优点,也有缺点。
传统模式的缺点是:同一时间,只有一个事务能获得某个表的表级别的 AUTO-INC 锁。
插入记录到同一个表的多条 insert 语句,如果都需要 MySQL 生成自增字段值,这些语句只能串行执行,这会降低 MySQL 的并发能力。
传统模式为 insert 语句的第一条记录生成自增字段值之前,就会加表级别的 AUTO-INC 锁,insert 语句执行完成时,才会释放。
innodb_autoinc_lock_mode = 1,连续模式(consecutive mode)。
这是 MySQL 8.0 之前的默认值。
连续模式也能保证 MySQL 为同一条 insert 语句插入多条记录生成的自增字段值是连续的,所以,基于语句的主从复制也是安全的。
连续模式不会像传统模式那样,为所有需要生成自增字段值的表都加表级别的 AUTO-INC 锁,而是会根据 insert 语句的类型加不同级别的锁。
对于 insert ... select 这种不能事先确定插入记录数量的语句,连续模式和传统模式一样,也会加表级别的 AUTO-INC 锁。
对于 insert ... values 这种简单的能事先确定插入记录数量的语句,就不会加表级别的 AUTO-INC 锁,只会加个轻量锁。
所谓轻量锁,就是生成自增字段值之前,加锁,生成自增字段值之后,马上释放,而不需要等待 insert 语句执行完才释放。
这种简单的 insert 语句,不管是插入一条记录,还是插入多条记录,都会一次性为所有记录生成连续的自增字段值。
对于简单的 insert 语句,还会有一种例外情况:当它要插入记录的表被其它事务加了表级别的 AUTO-INC 锁,它就不会加轻量锁了,而是改为加表级别的 AUTO-INC 锁,然后排队等待获得锁。
连续模式加的表级别的 AUTO-INC 锁,同样也要等待语句执行完成时才释放。
innodb_autoinc_lock_mode = 2,交错模式(interleaved mode)。
这是 MySQL 8.0 的默认值。
交错模式为所有 insert 语句插入记录生成的自增字段值,都不会加表级别的 AUTO-INC 锁,而是加轻量锁。
对于 insert ... select 这种不能事先确定插入记录数量的语句,每往目标表中插入一条记录之前,先加轻量锁,再生成自增字段值,然后马上释放轻量锁。
插入多条记录的过程中,如果有其它 insert 语句也生成了自增字段值,会导致 insert ... select 插入多条记录的自增字段值不是连续的。
交错模式是三种模式中效率最高的,但是为并发执行的多条 insert 语句生成的自增字段值可能不是连续的。
主从复制集群中,从库回放 binlog 日志时,即使和主库执行 insert 语句的顺序相同,也可能造成从库生成的自增字段值和主库不一致,从而导致主从数据不一致。
所以,交错模式对基于语句的主从复制不安全。
MySQL 8.0 把 innodb_autoinc_lock_mode 的默认值从 1(连续模式)改为 2(交错模式),是因为系统变量 binlog_format 的默认值,已经从 8.0 之前的 STATEMENT 改为 ROW,不再需要使用连续模式来保证主从复制的自增字段值的一致性。
InnoDB 表级别的共享锁和排他锁并不常用,因为 server 层的元数据锁在多数场景下代替了它的功能。
意向共享锁、意向排他锁是为了和行级别的共享锁、排他锁配合使用的,目的是加 InnoDB 表级别的共享锁、排他锁的时候,能够方便快速的判断表中是否加了行级别的共享锁、排他锁。
AUTO-INC 锁有三种模式:传统模式、连续模式、交错模式。
传统模式、连续模式都能保证为同一条 insert 语句插入多条记录生成的自增字段值是连续的,对基于语句的主从复制是安全的。
多条 insert 语句并发的情况下,交错模式为同一条 insert 语句插入多条记录生成的自增字段值可能不连续,对基于语句的主从复制不安全。