
现实世界中的机器学习解决方案很少只是构建和测试模型的问题。 到目前为止,从训练到优化,管理和自动化机器学习模型的生命周期是机器学习解决方案中最难解决的问题。 为了控制模型的生命周期,数据科学家需要能够持久地并大规模地查询其状态。 除非您认为任何平均深度学习模型都可以包含数百个隐藏层和数百万个互连节点,否则这个问题似乎微不足道。)存储和访问大型计算图绝非易事。 在大多数情况下,数据科学团队花费大量时间尝试将商品化的NOSQL数据库适应机器学习模型,然后得出一个不太明显的结论:机器学习解决方案需要一种新型的数据库。
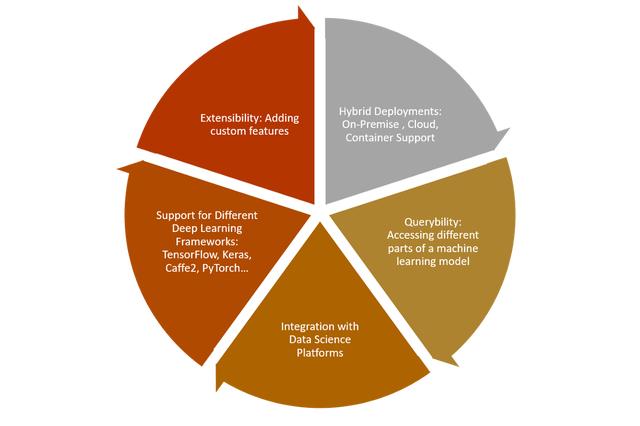
MLDB是为机器学习时代而设计的数据库。 该平台经过优化,可以存储,转换和导航表示机器学习结构(例如深度神经网络)的计算图。 我知道您在想什么AWS云机器学习平台(例如AWS SageMaker或Azure ML)已经包含用于机器学习图的持久性模型,那么为什么我们需要另一个解决方案? 好吧,事实证明,可以从真实数据库中受益的现实世界机器学习解决方案有很多需求:
输入MLDB
MLDB提供了一个开放源代码的本地数据库,用于存储和查询机器学习模型。 该平台首先在Datacratic中孵化,最近被AI强国Elementai收购,以验证数据库引擎在现代机器学习项目中的相关性。 MLDB有多种形式,例如可以部署在任何容器平台上的云服务,VirtualBox VM或Docker实例。
MLDB的体系结构结合了不同的工件,这些工件抽象了机器学习解决方案生命周期的不同元素。 从技术上讲,MLDB模型可以归纳为六个简单的组件:文件,数据集,过程,函数,查询和API。
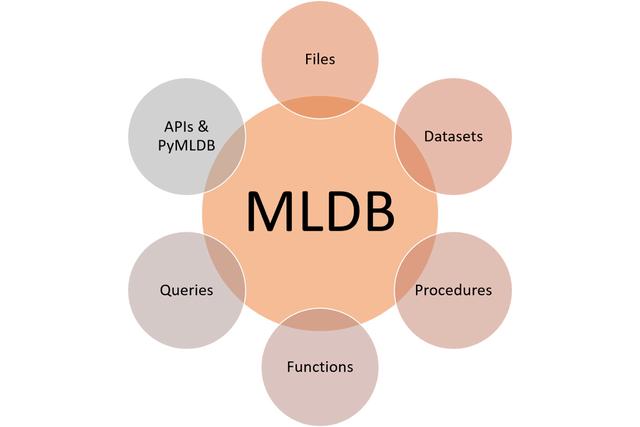
档案
文件表示MLDB体系结构中的通用抽象单元。 在MLDB模型中,文件可用于加载模型的数据,函数的参数或保留特定的数据集。 MLDB支持与流行的文件系统(例如HDFS和S3)进行本机集成。
数据集
MLDB数据集表示过程和机器学习模型使用的主要数据单元。 从结构上讲,数据集是无模式,仅附加命名的数据点集,它们包含在单元格中,单元格位于行和列的交点处。 数据点由值和时间戳组成。 每个数据点因此可以表示为(行,列,时间戳,值)元组,而数据集可以视为稀疏的3维矩阵。 可以创建数据集,并可以通过MLDB的REST API将数据添加到数据集,也可以通过过程从文件中加载或保存到文件中。
程序
在MLDB中,过程用于实现机器学习模型的不同方面,例如培训或数据转换。 从技术的角度来看,过程被命名为可重用的程序,用于实现长时间运行的批处理操作而没有返回值。 过程通常在数据集上运行,并且可以通过SQL表达式进行配置。 过程的输出可以包括数据集和文件。
功能
MLDB函数抽象了过程中使用的数据计算例程。 函数被命名为可重用的程序,用于实现可以接受输入值并返回输出值的流计算。 通常,MLDB函数封装表示特定计算的SQL表达式。
查询
MLDB的主要优点之一是它使用SQL作为查询存储在数据库中的数据的机制。 该平台支持相当完整的基于SQL的语法,其中包括熟悉的构造,例如SELECT,WHERE,FROM,GROUP BY,ORDER BY等。 例如,在MLDB中,我们可以使用SQL查询为图像分类模型准备训练数据集:
mldb.query("SELECT * FROM images LIMIT 3000")
API和Pymldb
MLDB的所有功能都通过简单的REST API公开。 该平台还包括pymldb,这是一个Python库,它以非常友好的语法抽象了API的功能。 以下代码显示了如何使用pymldb创建和查询数据集。
from pymldb import Connection
mldb = Connection("http://localhost")
mldb.put( "/v1/datasets/demo", {"type":"sparse.mutable"})
mldb.post("/v1/datasets/demo/rows", {"rowName": "first", "columns":[["a",1,0],["b",2,0]]})
mldb.post("/v1/datasets/demo/rows", {"rowName": "second", "columns":[["a",3,0],["b",4,0]]})
mldb.post("/v1/datasets/demo/commit")
df = mldb.query("select * from demo")
print type(df)支持机器学习算法
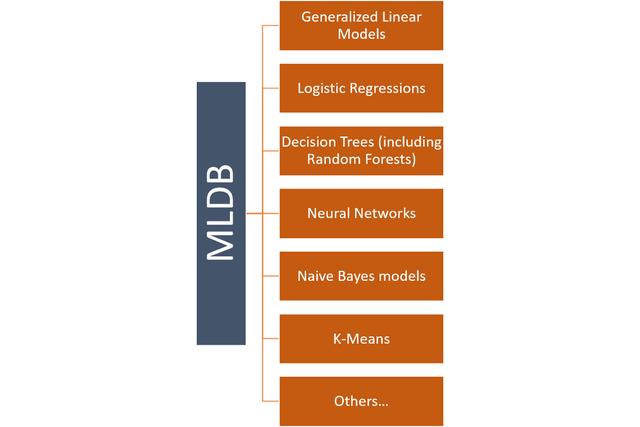
MLDB支持大量的算法,例如可以从"过程和函数"中使用的算法。 该平台还本地支持TensorFlow等不同深度学习引擎的计算图。
汇集全部
让我们以机器学习解决方案中的通用工作流程为例,例如模型的训练和评分。 下图说明了如何在MLDB中实现它:
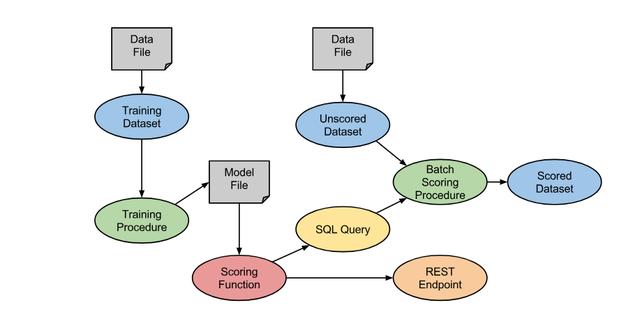
> Source: https://mldb.ai/
· 该过程从充满训练数据的文件开始,该文件已加载到训练数据集中。
· 运行培训程序以生成模型文件
· 模型文件用于参数化评分功能
· 可通过REST端点立即访问此评分功能,以进行实时评分
· 还可以通过SQL查询立即访问评分功能
· 批处理计分过程使用SQL将计分功能应用于未计分的数据集,从而产生计分的数据集
结论
MLDB是为实现机器学习解决方案而重新设计的第一个数据库实例。 该平台仍然可以进行很多改进,以支持现代机器和深度学习技术,但是它的灵活性和可扩展性使其成为了这个新领域的一次重大迭代。
(本文翻译自Jesus Rodriguez的文章《MLDB is the Database Every Data Scientist Dreams Of》,参考:
https://medium.com/dataseries/mldb-is-the-database-every-data-scientist-dreams-of-395dfa53749e)















